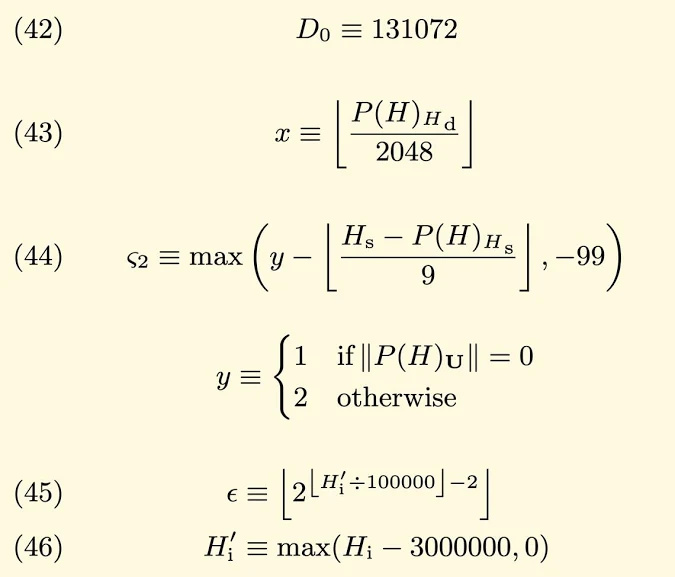A few weeks ago I plotted Blocktimes overtime and noticed a pattern. The past few days I have been working on calculations around the difficulty bomb at the Status Hackathon. While working I observed a few more related pieces and after talking to a few people here, was recommended to post for additional feedback. I am not sure the significance of these findings from a Tokenomic incentives perspective, and would appreciate feedback and validation/invalidation of the underlying ideas.
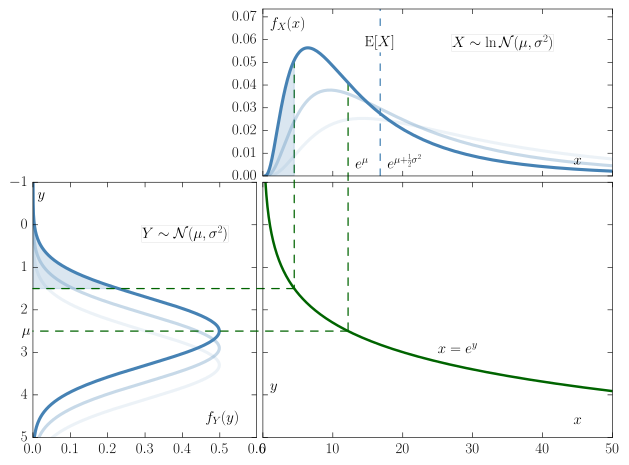
The probability distribution of block times is a [Log-Normal Distribution](https://en.wikipedia.org/wiki/Log-normal_distribution)
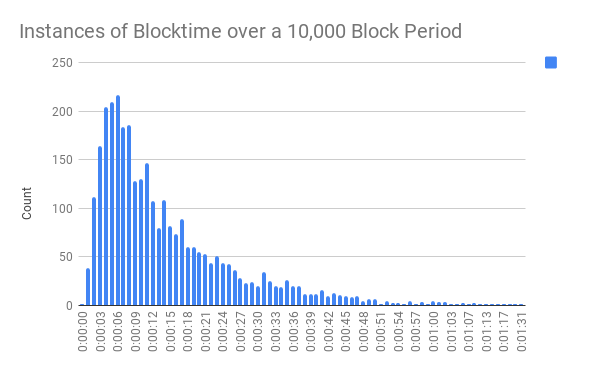
Most often when dealing with probabilities we see a Normal Distribution. At first thought it is easy to think that BlockTime fits into this as well, but it in fact does not. Logically, it can be seen because you are unable to have a Blocktime of less then zero on one end and on the other a blocktime can be of any length (all though very unlikely to be extremely long). You can also see this in the data. The chart below is distribution of blocktimes over 10,000 blocks starting on Sep-08-2018 12:53:38 PM +UTC
** The Difficulty Function Adapts Linearly **
The correction factor in the difficulty adapting equation responds linearly in respect to block time. Why may this be a problem?
** The probability that a blocktime occurs is an exponential function, but the function that responds to changes in blocktime reacts linearly **
If the claims are true the function adapting the difficulty target would under react or over react to changes in block time.
Some possible consequences:
- Oscillations in difficulty and blocktime. Eventually the linear function catches up and explains the stability of blocktimes over large enough periods of time.
- The existence of a “sweet spot” where there is an ideal acceleration or deceleration of Hashrate in order to maximize accumulation of coins over time.
My conclusion is that if we had a difficulty function that adapts to how statistically unlikely a block time is to occur that the blockchain would be more robust and stable against increases and decreases in Hashrate.
Feedback and correction is welcome and preferred. I am not a trained mathematician, just a musician that loves numbers and hopes any of these observations can help.
Cheers,
James