I would love to see state expiry implemented! I spent something like 6 months trying to solve it with some Ethereum researchers a while back but we were never able to come up with a solution that we thought would be satisfactory enough to actually get implemented. If someone has figured out a solution I would love to hear it!
2 Likes
What if you pay validators a fee per MB to encourage investment in storage. The more storage a validator has the more rewards it gets.
Why? There’s no requirement for FOCIL validators to accept transactions according to any specific formula; making a non-empty FOCIL list is a purely volunteer task. So they can use whatever rules they want, and then keep the state that is necessary for them to be able to enforce those rules.
I increasingly think the solution to state expiry is to just move closer and closer to a world where every node is a partial state storing node. Users what want to send txs that use state that other people don’t store would have to locally store the associated witnesses and attach those witnesses to their transactions.
3 Likes
I appreciate the effort towards increased resilience here again. But I’m not sure if what is proposed is actually realistic.
What I would like to see play out is end-users are able to run their own RPC servers that follow head and store the vast majority of all interesting state on Ethereum.
Yes, that aligns with censorship resistance, but I doubt it’s the realistic outcome. What would that look like in practice? Ideally, every wallet would run a local reduced-state node - think “Mist, but scalable.” But that shifts an even heavier burden onto full nodes, which would then have to:
- Lookup light-client proof data → increased storage (read) load
- Generate the light-client proof → increased compute load
- Relay the light-client proof over the network → increased bandwidth and connection load
I’d love to see performance estimates, but depending on rollout, you could easily end up with partial-state nodes outnumbering full nodes by more than 1,000x (assuming one wallet per reduced-state node). That alone could bottleneck full nodes. And network load isn’t just about bandwidth - it’s also about how many concurrent connections a node can handle.
With all that extra work, why would full-node operators participate? We’ve managed so far with only a few light nodes freeloading on existing full nodes, but that dynamic would break once most Ethereum users run light clients.
Maybe I’m off base here - it all depends on how this is rolled out and adopted. I’m curious what @vbuterin envisions in practice, since that will determine what additional systems - like a dedicated light-client proof-data layer - we might need to design, build, and incentivize.
1 Like
If FOCIL includers don’t store (or query, or verify a proof) the validity-only state (balance and nonce basically), they can’t know which transactions should be kept or pruned in the mempool, which means an attacker can easily spam the mempool with a lot of invalid transactions, that would then end up in ILs and crowd out valid ones.
In practice they can definitely choose not to hold state if they don’t want to, but then they wouldn’t be able to participate in FOCIL and propose “good”, relevant ILs. If we don’t assume all nodes will want to participate in FOCIL (which is fair, it’s just a departure from the model we have today where all participating nodes running an EL client maintain the public mempool according to the exact same rules), then FOCIL should probably opt-in, and FOCIL nodes should be cleanly separated from other nodes performing other duties (e.g., Attester-Includer Separation) in the future. But then they might need incentives with either fees, or issuance. This is a topic we’re actively exploring but it’s very tricky find a simple, incentive compatible solution there.
1 Like
For persistent storage to survive in a decentralized system, the erasure code needs to be composable and decentralized, i.e. RLNC. One-time use codes like RS will lead to loss of ability to recover the data because nodes come and leave.
F.H.P. Fitzek, Toth, T., Szabados, A., Pedersen, M.V., Lucani, D.E., Sipos, M., Charaf, H., and Médard, M., “Implementation and Performance Evaluation of Distributed Cloud Storage Solutions using Random Linear Network Coding," IEEE CoCoNet 2014
V. Abdrashitov and Médard, M., “Durable Network Coded Distributed Storage," Allerton 2015
V. Abdrashitov and Médard, M., “Staying Alive - Network Coding for Data Persistence in Volatile Networks," invited paper, Asilomar 2016.
While I’m very excited for state expiry and encapsulated ethereum history storage finally solved,
As local node runner myself, I don’t see how storage is a problem. 4TB SSD investment is fairly cheap and returns on investment come within month or two.
What I do rather see as a challenge is that APY is low, and if running full execution client for just single validator is not that much capital efficient.
What I do anticipate is incentives to run local nodes. It should be heavily driven by “unfair” APY advantage over cloud hosted solutions, empathising that cloud solutions are single-point-of-failure and hence less valuable for the network.
What do you think of [2403.13230] BFT-PoLoc: A Byzantine Fortified Trigonometric Proof of Location Protocol using Internet Delays ? It seems like the most realistic approach toward getting this delta really impactful.
I’m assuming that Ethereum blocks would come with state deltas and proofs by default, and so you do not need any extra infrastructure in order to service partial-state nodes. In fact, a partial-state-node heavy world is lighter on infra than fully relying on helios + TEE/ORAM/PIR based RPC nodes.
But on top of this, ultimately I think that we eventually would benefit a lot from getting comfortable with paying nodes for services via a standardized (and anonymized) market.
3 Likes
My view is basically:
- FOCIL is de-facto opt-in already
- With 7701, the idea is that each node will be able to choose its own validity rules, and connect to its own mempool. There may be a mechanism by which we economically abstract this, and allow anyone to create a mempool by staking some amount of ETH (and if txs from that mempool end up invalid too often, nodes blacklist it by default)
- Hence, we should just embrace the idea that FOCIL nodes can choose which mempools they are helping to enforce
The only constraint on mempools would be the FOCIL validity rule, which would ensure that a tx can be thrown out if it does not pay fees.
Isn’t there a situation where you may touch some data that is sibling to data you don’t have, and then you aren’t able to calculate the MPT root anymore? Or perhaps you are imagining a move away from our current structure in order to achieve this state expiry mechanism?
1 Like
These reduced-state nodes would only need to fetch extra data from somewhere when they find they are missing state they need (hopefully a rare occurrence). If they have all of the state they need then the only extra proving is by the block builder once per block, where the block builder would generate and distribute a proof of the state diff for their block. This is different from light clients like Helios who route all of their queries through third parties.
What is being discussed here is RPC serving nodes, not staking nodes. You are correct that stakers can afford hardware, and they are a service provider being paid to do work so it is reasonable to require this of them. RPC serving nodes are end-users that may be poor, may have low end hardware, and likely aren’t going out of their way to build out Ethereum-only PCs/servers.
1 Like
The idea would be that:
- For data you want to read, you store and keep up-to-date only the state
- For data you want to use in the validation section of a tx, you store and keep up-to-date the state and the sister nodes up to the root
Probably not the most interesting thing but just to make sure we’re on the same page, FOCIL is definitely not opt-in in its current form. You’d have to modify client code if you didn’t want to participate in building ILs according the inclusion rules chosen by clients
Ok I see, so only basic ´nonce´ and ´balance´ checks, and then if other more complicated interactions (e.g., an IL transaction is invalidated by another “balance emptying” transaction included by the block producer before in the payload) invalidate transactions they can still be included in ILs but if specific mempools are responsible for too many invalid txns they become blacklisted, got it!
A few thoughts:
-
I like the idea because of the flexibility it would give but asking each node to keep track of many different mempool and blacklist them sounds a bit messy and might open some attack vectors (wouldn’t an attacker be able to just spin up new mempools whenever one gets blacklisted?)
-
One thing that can help is to play around with mempool rules, like enforcing at most N pending full AA transaction per address (this is how we deal with 7702 txns atm) so we limit IL flooding.
-
Maybe one thing to consider is how much of a spectrum would we really see between nodes. To me FOCIL nodes can:
- Store validity-only state and either:
- Optimistically include full AA txns in ILs
- Decide to include full AA txns only if they come with witnesses attached, or not to include full AA txns in their ILs at all
- Store the full state and include all txns valid against the pre-state
- Store validity-only state and either:
This leads to two small qs:
- In case FOCIL nodes only store validity-only state and optimistically include full AA txns, how do we deal with attackers spamming all mempools at the same time (at no cost because these txns will be invalidated anyways), what are examples of custom validation rules that could help with this? Maybe more of a q for @yoavw here
- Do you think in practice we would see a lot of FOCIL nodes store validity-only state + some state related to specific applications they care about? Or is it more of a binary (validation-only or full state) thing?
Note: If we use BALs with post-values txns + nonce and balance checks, attesters can perform static validation and vote for a block with full AA txns without having to wait for the full execution (h/t Francesco and Toni) so I think everything works out for attesters in any case, which is nice.
1 Like
Isn’t this what Portal is doing. Except instead Portal is getting robustness through replications rather than erasure coding’s. Both have trade offs, but I think robustness through replications should be sufficiently durable as the number of replications would grow with the set of nodes participating and with the total storage being contributed.
Is this bullet point suggesting a different storage solution should be built rather then Portal? What are priorities and trade offs desired in the target solution?
This ensures the property that “a blockchain is forever” without depending on centralized providers or putting heavy burdens on node operators
^ Portal should be sufficient for these goals, which is why I ask.
This somewhat echo’s what Kolby just stated.
I believe that Portal solves all if not the vast majority of the stated goals and functionality outlined in this post. If this is a priority for Ethereum, we’re already on it and have solutions ready to go.
Portal History network is already storing this information. We are generating ERA-style files for archival purposes of this data. Portal is ready as fast as EL clients are ready to drop this.
Portal History network already provides a robust solution for this. It’s live and working.
Portal State network is already underway in going live and is designed for lightweight personal nodes that have full RPC capabilities. The ability to have these clients verify blocks improves if the protocol is willing to upgrade to include commitments to things like witnesses or state diffs.
State trie unification like is proposed in Verkle also improves things.
I might be totally off topic here, but as far as I understand, the motivation of this ongoing work is to enable more localised, decentralised ethereum network infrastructure as general challenge ecosystem faces.
What stumbles me often in these EF discourses, is how much abstract, mathematical thinking is there as opposed to physical telecommunication real world.
TCP networks do not look like “client ↔ server”. They look (very simplified) like this:
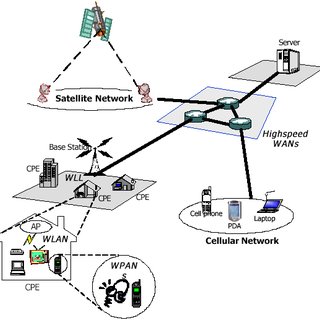
In initially linked articles network throughput is put under concern, however no analysis of what is physical topology demand is for such throughput.
It’s also claimed that
However this problem statement does not include detail that indeed it is not the technical difficulty that faces bottleneck. It’s a financial incentive and return on investment difficulty to justify totally tangible and feasable technical requirements. Ethereum hardware requirements are not TON alike where you need a datacenter rack to launch a node.
Challenges are in i) financial incentive of doing so (low APY plus increased broadband internet, static IP costs) ii) difficulty (cost) of obtaining static IP address from my ISP iii) lack of competitive market of ethereum node oriented hardware (dappNode with $2k cost bill is a lol).
Further, in local RPC serving nodes proposal here, assumption is that clients may want to store partial data. While I agree with that, If we take in context that we knowing how network topology of ISPs looks today:
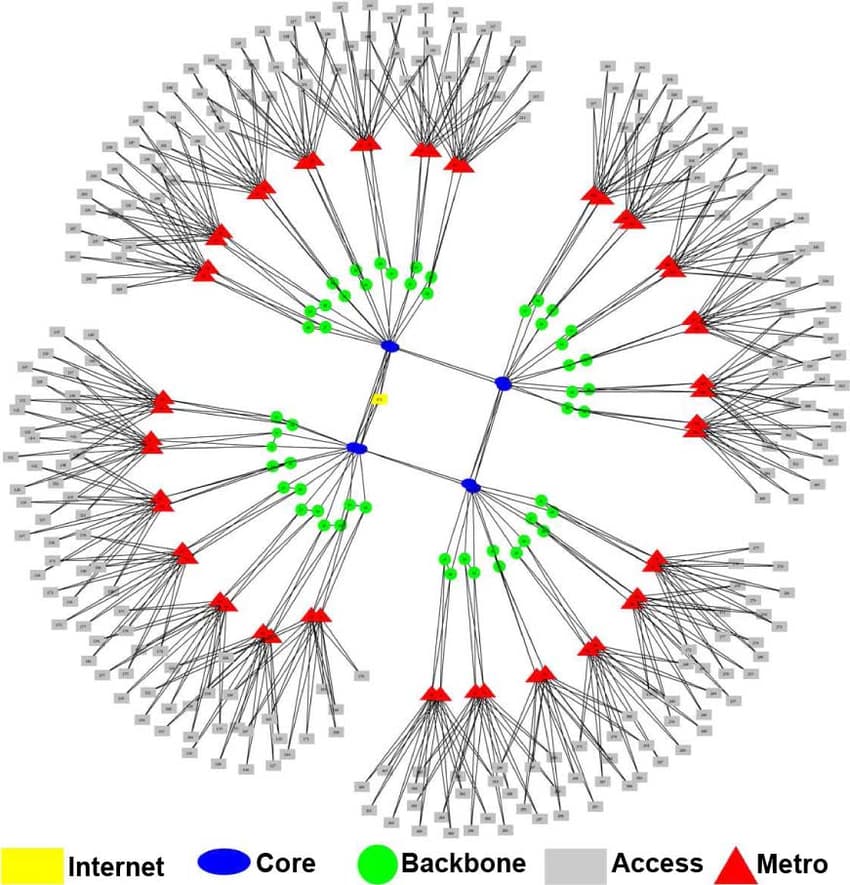
Then we are still missing this analysis of throughput demand. Is it really uniform (transactions happen with equal probability between two randomly picked end-clients)?
I doubt it. I’d rather bet on that majority of settlements requiring high throughput are actually happening between local access points (end-users) doing their settlements.
If majority of traffic is localised then, candidates to run such “partial” clients are ISPs, last mile carriers, telecom companies who should be able to provide near instant settlement for transactions for network clients & contracts that are subset of their underlying client base and then slowly settle them to main ledger (and how it plays with rollup-centric stuff?).
And that’s my point - they have no problems running 4TB SSD. They have static IP addresses already (!). They have specialised hardware companies and expertise that can enter market and create competitive hardware pricing.
In many aspects, last mile carriers are much better candidates to reinforce network decentralisation and localisation.
The problem is that they don’t see incentives in doing this.
If I’m running local node, there must be way of earn high yield on being able to settle end-user transactions quicker then others or for relaying that requested data to end user (and here partial state can be though as distribution network caching layer).
That gets me back to article on BFT-PoLoc paper I linked. If my local node can proof that it is able to do fastest settlement between two network clients, it should be able to take that opportunity at risk of already present stake it has.
Then you get both win-win: network scales as crazy as that’s what users wants (instant secure and cheap settlements), and spatial decentralisation is achieved (data centers located remotely from user locations naturally cannot win settlement profits from ISPs or last mile carriers if market is latency based).
2 Likes
in context of EIP-4444 I suggest also adding
- Event logs chosen to be stored by the operator, plus an option to store them as indexed, fast retrieval objects (potentially removes the need to host separate indexer clients)
“Settlement” on Ethereum is between users and block builders. For each block, there are users all over the world submitting transactions, and a single builder somewhere in the world that is building the block. Once that block is built, it needs to be propagated to every node on the network.
1 Like