Thanks so much for this nice post! It was a pleasant and interesting read! And definitely a really nice proposal!
How is this a small field? Is almost the order of the scalar one of Ristretto or 25519 already (2^{255}-19).
I wonder if in general you have explored other commitment schemes. If the SRS (trusted setup) is a must-have, then seems only KZG is the other viable option.
- I wonder if this could be done differently to avoid using EC-based stuff in the networking layer(considering there are plans to migrate to PQ primitives). I’m thinking about Ajtai commitments mostly. But there could be other things worth exploring. Just need to be sure I understand all the properties that this requires to a commitment scheme.
- Also, worth considering using on the “Don’t care about PQ case” something like: Efficient Elliptic Curve Operations On Microcontrollers With Finite Field Extensions. This allows us to have curves that have extremely tiny fields, yet give us 128-bit security. Thus, enabling us to have all the benefits of small fields with the properties like hash-to-curve etc…
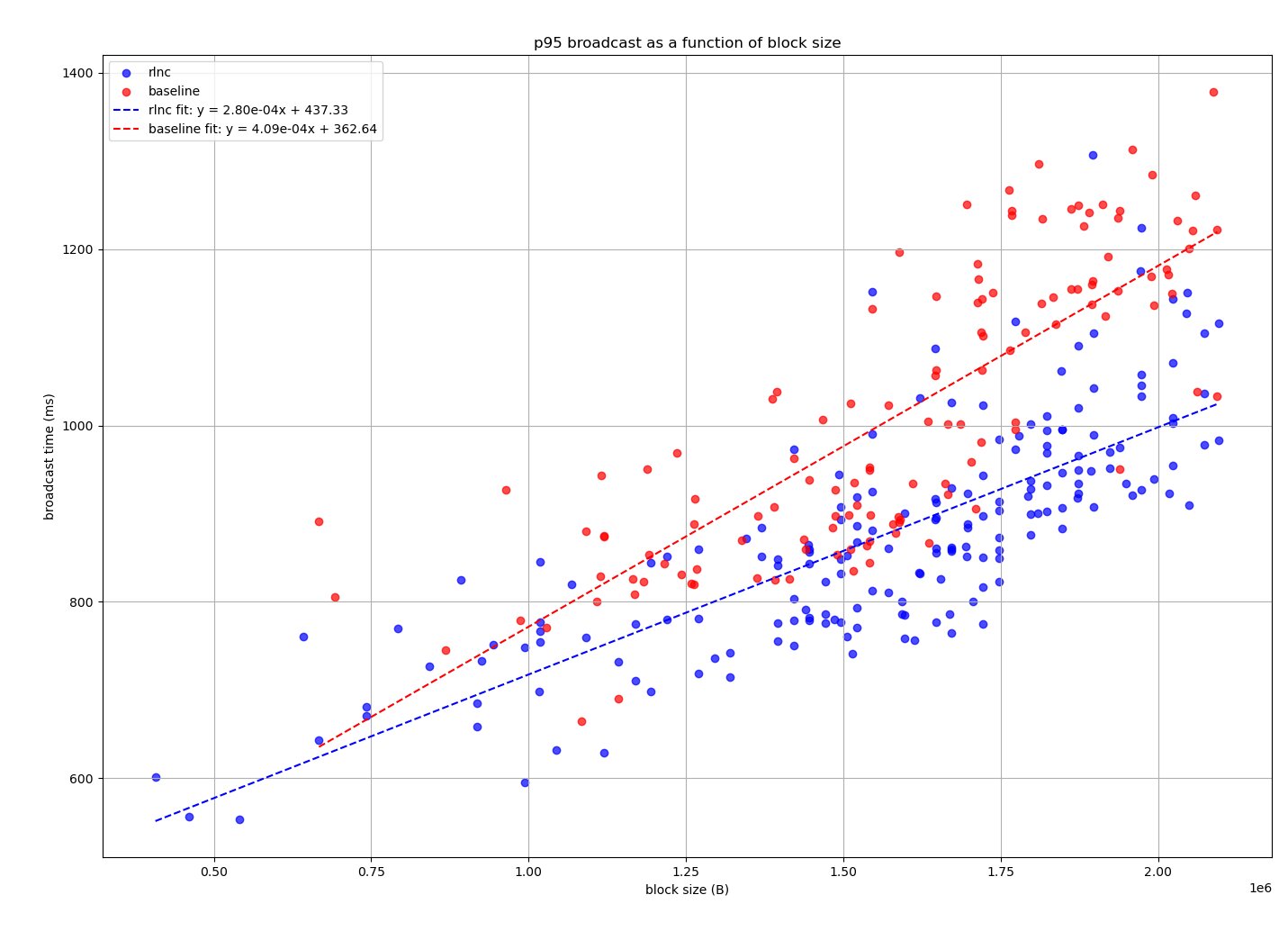
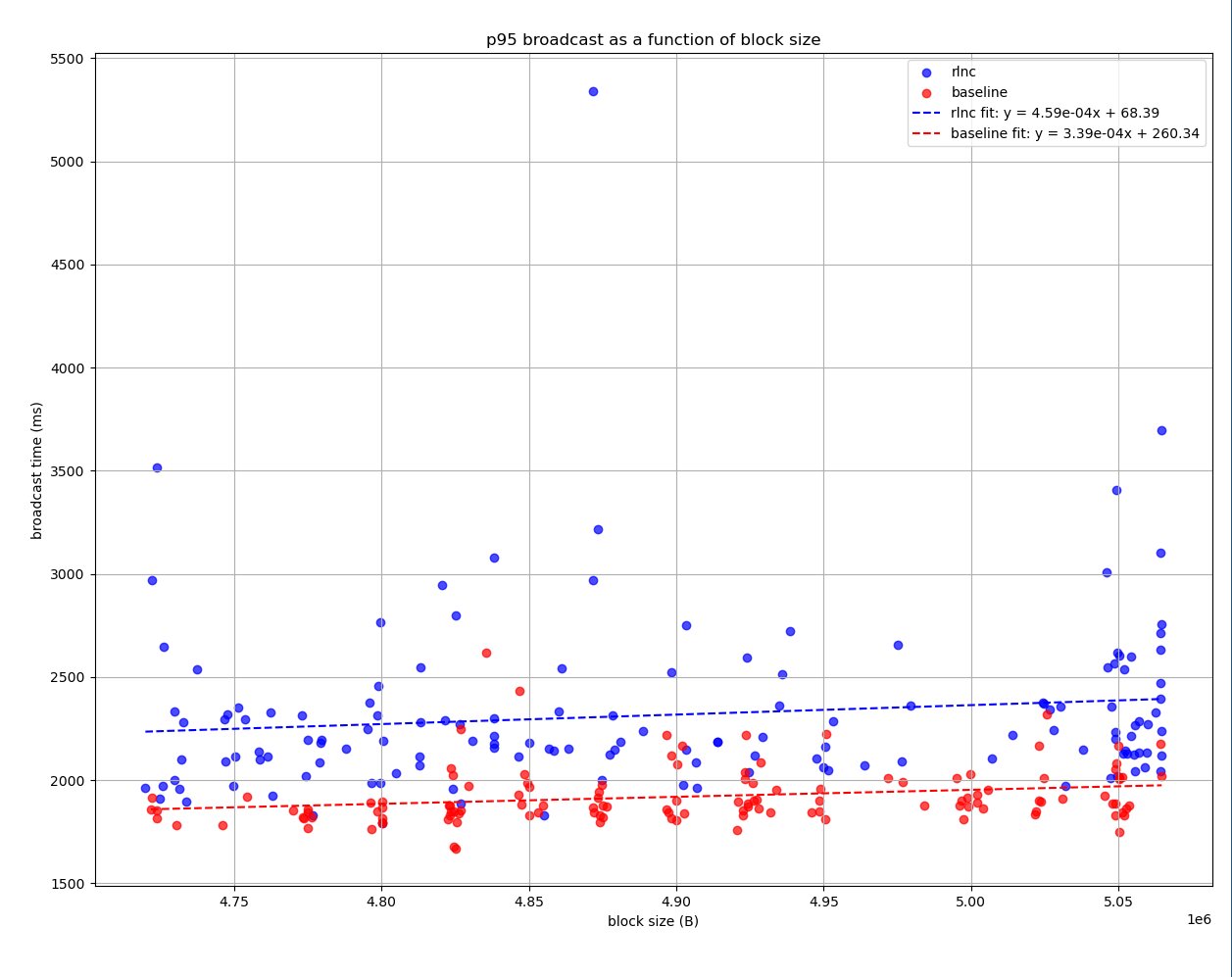
As for RLNC this is definitely a really nice option for gossiping!
I think it’s also important to highlight this metric. RLNC saves us bandwidth undeniably. And it definitely seems to improve converging times. ie. time it takes to the majority of the network to be in sync on latest state sent.
Do you envision any possible improvements in that part? Is already RLNC addressing this problem too? Hence we just ignore this?