@vbuterin I think you are referring to using compress_proof and decompress_proof on a naive sparse merkle tree. I was referring to implementations in new_bintrie_optimized.py and new_bintrie_hex.py.
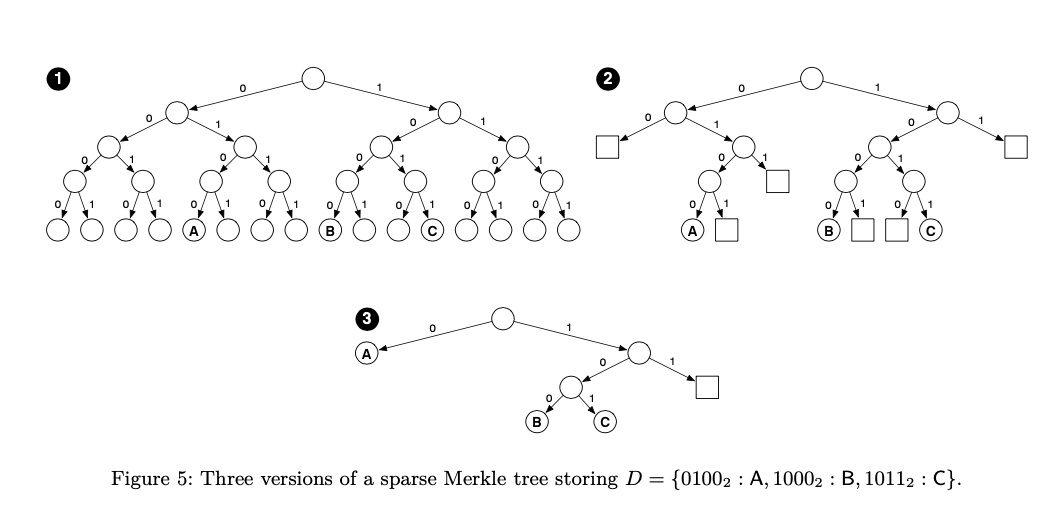
Those implementations are just changes to how the data is stored in the database, they don’t actually change the verification that gets executed. new_bintrie_optimized.py, new_bintrie_hex.py and the simple SMT are all different algorithms to implement the exact same thing. So in either case you’d be doing a bulletproof over 256 hashes.
The number of proof nodes is quite different in case of simple SMT and new_bintrie_optimized.py. Since number of hash calls only depends on the number of proof nodes, there are much less hash calls in new_bintrie_optimized.py. I did some basic benchmarking on the forked code and for the same number of leaves, the simple SMT always has 256 proof nodes as expected whereas the optimized one has 10-15. You can find the benchmark code here.
That’s because each proof node in the more complex implementations is a “virtual proof node” that often stands in for many “actual proof nodes”.
1 Like
there is an implementation of the optimized tree in JS and Solidity here:
We used it to store quadratic vote balances in ERC-1948 tokens at a pop-up democracy.
Together with our partner Deora we at LeapDAO took a deep dive into Quadratic Voting over the last year.
Today we want to present you with our findings after analyzing the outcomes of two very different events, at the first convention of Volt Germany and ETHTurin.
Additionally you will find a short overview of our technical implementation including sparse Merkle trees in our blog post here: https://ipfs.leapdao.org/blog/quadratic-voting/
1 Like
In case someone is looking at this in 2021: This bitmap for indicating where non-zero proofs are needed might not be necessary if your root generation function anyways ingests the leaf index that is supposed to be written and fills up the tree from left to right.
Because I didn’t know, I first ended up implementing the optimization compression proof outlined in the original post of this thread. My commit: Optimizing sparse merkle tree · rugpullindex/indexed-sparse-merkle-tree@dac73bf · GitHub
But then, after looking at the ETH2 deposit contract implementation, I realized that here simply the “size” AKA highest leaf index in the tree is used to determine if a partial proof is a “non-zero” leaf or not: consensus-specs/deposit_contract.sol at 34fc0a5d09fae6649e0c6ac7a0cb09ff5a999957 · ethereum/consensus-specs · GitHub
So I ended up imitating that strategy in my SMT library and also went with using the index parameter to primarily safe gas.
You can find all of the results here: GitHub - rugpullindex/indexed-sparse-merkle-tree
- I’ve included your optimization into rugpullindex/indexed-sparse-merkle-tree: Make H(0, 0) = 0 · attestate/indexed-sparse-merkle-tree@eacc9e4 · GitHub
We now also ship a gas benchmark file: indexed-sparse-merkle-tree/.gas-benchmark at 36ae144f78fb8ffc9111fd45bd7f024b01ad7aa7 · attestate/indexed-sparse-merkle-tree · GitHub
One thing that hasn’t been discussed yet is that both our index and proofBits variable actually take quite some gas, particularly when having to store and load it from and to memory many times.
To reduce gas costs further, I was discussing with @pinkiebell to sort the proofs array. But it’s tough to wrap my head around it momentarily. If anyone knows of a Solidity implementation of it, that’d be helpful.
I found your implementation quite interesting. Particularly the updateMany function. I’m wanting to implement it as well once I have time.
Iota has a good merkle tree structure.
It is so efficient they’re on the way of zero fee transactions.