By Ali Atiia and Keewoo Lee.
Thanks to Ling Ren, Dimitris Mouris, Will Scott, Soham, Adria, Dan, Andy, Divyá Ranjan, Yue Chen, Pranav Shriram Arunachalaramanan, Felix Lin, and Jongmin Kim for feedback and comments on the draft.
Also thanks to Alex Hoover, Nam, Vitalik Buterin, and Igor Barinov for earlier PIR discussions and experimentations; to Guillaume Ballet, Carlos Perez, Takamichi Tsutsumi, and Tomás Arjovsky for discussion and collaboration on binary tries, and to Leo for discussions on provable UBT-MPT equivalence.
TLDR
Private Information Retrieval (PIR) can allow Ethereum users to read chain data from remote servers without the latter knowing what is being read. PIR schemes have different performance tradeoffs and user/server overheads. On the other hand, Ethereum data has different update profiles, and is consumed in different contexts with varying sensitivity to latency.
If Ethereum data is sharded so as to pair every dataset to the optimal PIR scheme for it, we could achieve better overall performance with the same privacy guarantees had we used one scheme for the entire Ethereum state —as long as users query all schemes with decoy queries parallelly to the real query.
This post proposes a set of slices of Ethereum state data, goes over PIR schemes and the decision tree to pair them with data slices, proposes a design sketch for sharding, and touches on some Ethereum-specific optimizations that may further scale the overall system.
Table of Contents
- 1. Introduction
- 2. Requirements
- 3. Sharding Ethereum Data
- 4. Private Information Retrieval
- 5. PIR System Architecture
- 6. PIR Scheme Selection
- 7. Universal PIR interface
- 8. Ongoing research & optimizations
- 9. Resources
1. Introduction
Ethereum users read chain data from remote servers to know and verify the current and historical state of interest or to construct and simulate transactions. Leaking what is being read can lead to the server correlating on-chain and off-chain user identities, enabling frontrunning and other extractive MEV, among other issues.
Primitives for Oblivious Reads enable a client to read data from a database host server without the latter knowing which data is being read. This, coupled with network-level unlinkability through anonymized routing, brings almost perfect privacy for users.
One such primitive, Private Information Retrieval (PIR), allows a client to retrieve an entry from a server-hosted database without the server learning which entry was accessed. The intuition behind one common construction (based on FHE, though there are other constructions): the client’s query is encrypted, and the server processes the encrypted query to produce an encrypted response — only the client can decrypt the result.
PIR is one of several approaches to oblivious data access — others include Trusted Execution Environments paired with ORAM (TEE+ORAM), which achieve obliviousness via hardware isolation and access-pattern hiding. TEE+ORAM is orders of magnitude faster than PIR in practice, but it relies on trust in hardware — specifically, that the TEE has not been compromised. We focus on PIR because it relies on cryptographic guarantees alone, without relying on availability of and trust in hardware.
This post proposes a design sketch for how to harness the various schemes of PIR (each with their own tradeoffs) to serve different slices of Ethereum data (each with their own characteristics) in different usage contexts (each of which have different sensitivity to latency). With this sharded approach, we can get the same privacy guarantees of one monolithic PIR engine for all Ethereum data while maintaining better overall performance tailored to every context of consumption.
With Ethereum data split into S shards, each shard being served by a PIR engine tailored to its types and access requirements, users query the engine of interest but simultaneously submit decoy queries to all other engines as well. This is equivalent privacy-wise to the user submitting a single query to one monolithic PIR engine serving the entirety of chain data.
2. Requirements
- Client-side verifiability of state reads is a requirement, which informs how PIR slices are extracted. e.g., we assume storage reads will be verified and therefore with each storage read we also have to read account and Merkle roots and block headers.
- The “all-data-or-nothing” requirement: if all Ethereum data is PIR-blanketed except, say,
getProof, then querying the non-masked data “doxes” the other queries to masked data, jeopardizing the whole thing. So the privacy of all user queries must be preserved. - Backward compatibility with Ethereum RPC: querying of PIR engines is abstracted from users who continue to query the Ethereum state using Ethereum RPC spec as is now. Similarly for Ethereum nodes, they answer RPC calls from sync’ing PIR engines without modification.
- We focus on single-server PIRs only to avoid the overhead that comes with coordinating non-colluding parties.
3. Sharding Ethereum Data
3.1 Contexts of consumption
Examining the type of blockchain data that is being queried in various contexts (figure below) shows almost all types of data get queried in all contexts.
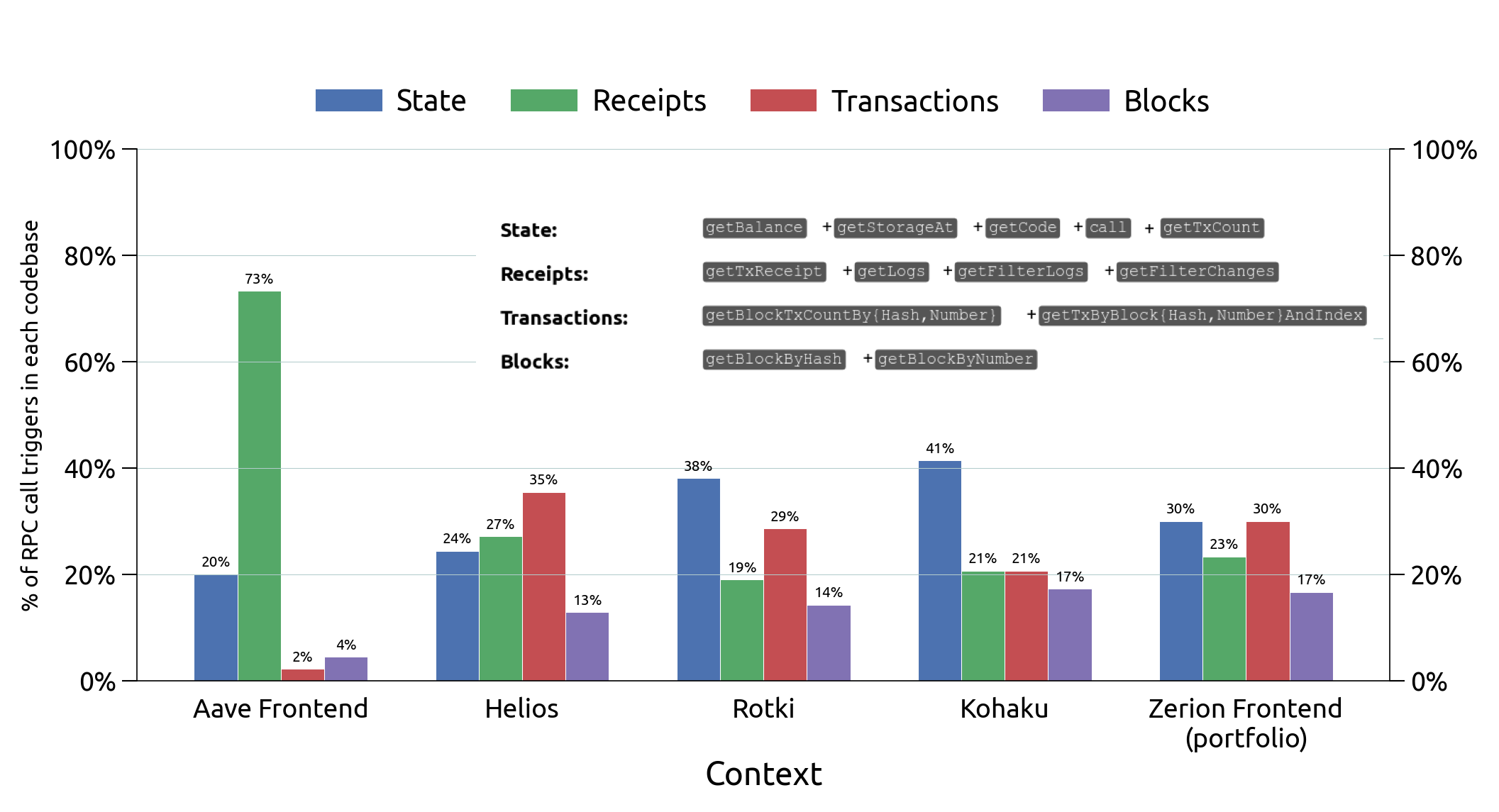
This makes sense when we consider the common intentions behind querying from wallets and frontends:
- What are my balances? \rightarrow
State(account header (ETH) or contract storage (ERC* tokens)) - Did I receive the ERC20 transfer, or has my DeFi deposit succeeded (cTokens) \rightarrow
Receipts - Has my transaction been confirmed/finalized? \rightarrow
BlocksorTransactions - What is the transaction history of this address? \rightarrow archival (historical)
BlocksorTransactionswith a specifiedblockNumberolder than most recent 128 blocks.
Reads-related RPC calls
table th, table td { background-color: white; font-size: 12px; }| Data source | RPC methods that touch it | Example Queries | |
|---|---|---|---|
| Hot State (full node) |
State Trie Mutable & appendable |
eth_getBalance† |
- What is my [provable] current ETH/ERC20 balance? - If I add this much collateral what would my liquidation price be, provably (contract exec simulation)? |
eth_getStorageAt† |
|||
eth_getCode† |
|||
eth_call† |
|||
eth_getTransactionCount† |
|||
eth_getProof† |
|||
| Transactions Tries (1 per block) Block header & body Append-only |
eth_getBlockTxCountBy{Hash, Number} |
- Has my transaction been included in the latest block? | |
eth_getBlockBy{Hash, Number} |
|||
eth_getTxByBlock{ Hash , HashAndIndex, NumberAndIndex} |
|||
| Receipts Tries (1 trie per block) Append-only |
eth_getTxReceipt |
- Have I received a shielded transfer (shielded pool events)? - Did my DeFi deposit succeed (DeFi cToken events)? |
|
eth_getLogs |
|||
eth_getFilterLogs |
|||
eth_getFilterChanges |
|||
| Historical State (archival node) |
Historical State Trie Append-only |
eth_getBalance‡ |
- What are my all-time balance changes of token x? - What was my [shielded] balance on Dec 31st? - Have I ever harvested any DeFi yield in 2025? |
eth_getStorageAt‡ |
|||
eth_getCode‡ |
|||
eth_call‡ |
|||
eth_getTransactionCount‡ |
|||
eth_getProof‡ |
|||
† when |
|||
3.2 Data slices of the Ethereum state
Factors that have the most consequential impact on PIR performance are:
- database size
- update frequency.
On the other hand, some user queries are frequent and latency-sensitive:
- What are my balances?
- Has my incoming or outgoing transaction been included?
while other queries are less frequent and/or less latency-sensitive:
- What is my transaction history: typically behind multiple clicks in wallets or pagination/further clicks on a frontend.
- Can I independently verify my balances: the part of verification dependent on internal (non-value) nodes and can tolerate being run in the background by a light client.
- What is my balance change history: for portfolio or accounting purposes. The former can be latency sensitive for portfolio frontends and represent a challenge because such data is sourced from
Huge(see below). For accounting dApps, this can tolerate high latency because users are accustomed to accounting/tax calculations taking a long time.
Considering these different data types (eg mutable vs append-only) and contexts:
The figure below shows an example slicing of Ethereum active and historical state aiming to isolate by such frequency and sensitivity metrics.
The estimation in the slices below can fluctuate when we take into account the fact that we can prune out a lot of “dead” state, eg ancient accounts with nonce 1, “spam” contracts that were only deployed for gas rebates (in the era pre the neutering of SELFDESTRUCT), contracts created and never accessed, etc:

Collectively the above slices in the figure encompass all hot and archival state data of Ethereum’s EL layer.
The Medium & Large slice are particularly challenging because they are both large in size and frequently mutated. This can potentially be adapted to by slicing it further “horizontally” per level of the state trie (see Section 8.1)
The High update frequency in Huge dataset refers to appending of new snapshots every block to the archival state. This is adapted to by the main+sidecar design discussed in Section 5.2, and the potential snarkification of archival state discussed in Section 8.4.
4. Private Information Retrieval
As stated in the intro section, PIR is the primitive of private reads this post is focusing on.
Two scoping notes:
- Symmetric PIR (SPIR) additionally hides the database contents from the client — only the queried entry is revealed. Since Ethereum data is public by nature, database privacy is not a requirement here and SPIR is out of scope.
- Keyword PIR. Standard PIR is index-based: the client queries by the numerical index of the entry it wants. Keyword PIR allows querying by key (e.g., an Ethereum address) rather than index, and importantly, its performance depends on the size of the database, not the size of the keyword space. There is a generic transformation from index PIR to keyword PIR via cuckoo hashing. In practice, keyword PIR is the more natural interface — users query by address and receive a balance, not by row number — so for the rest of this post we simply say “PIR” with the understanding that keyword PIR is the intended mode of access.
4.1 Taxonomy
PIR schemes differ along many axes — communication cost, per-query computation, and more. We classify them here by their state architecture: where does state live (client, server, or both), and how it is established. This provides a clean and practical lens for choosing the right scheme for a given application.
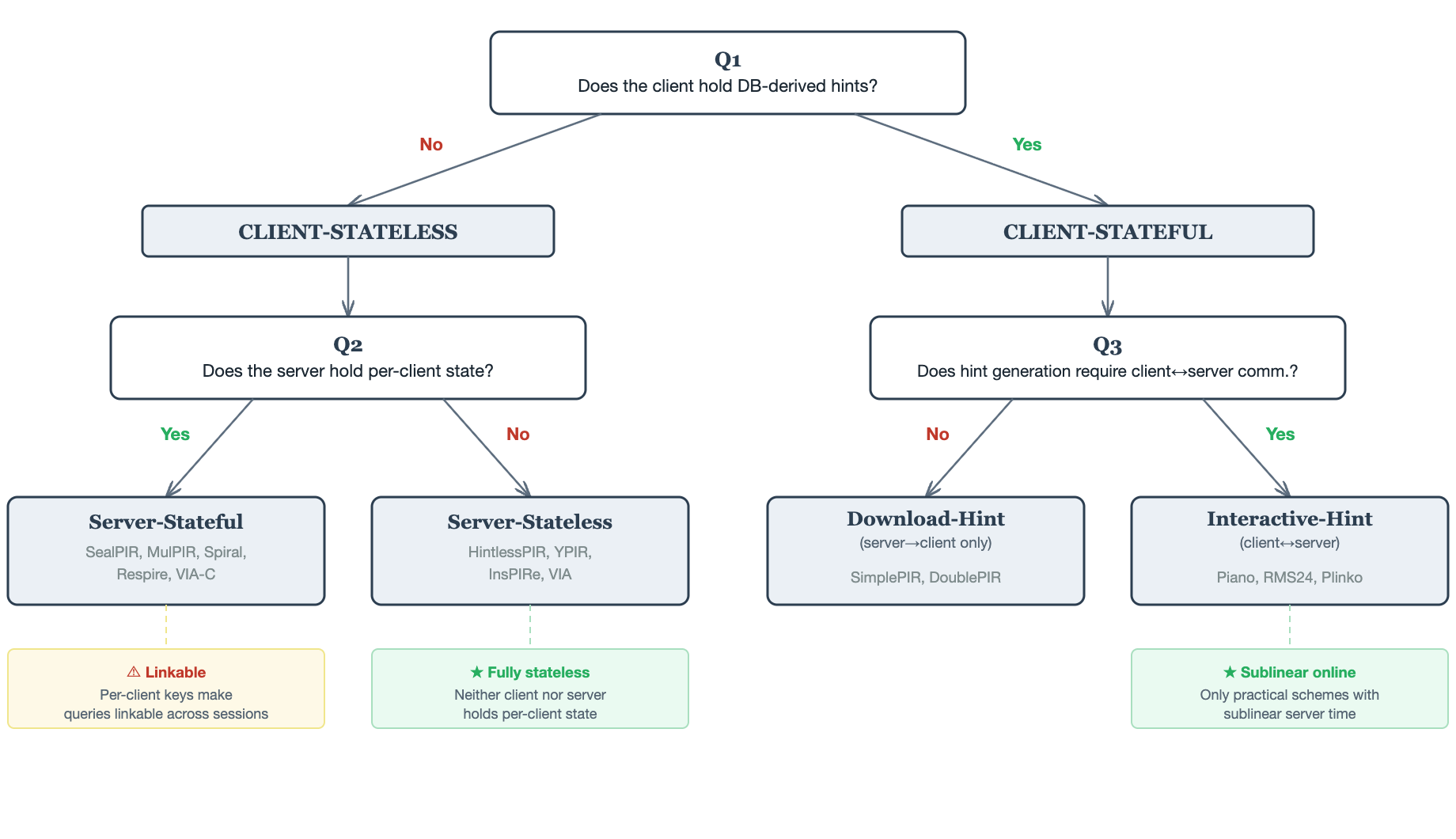
Client-stateless schemes require the client to store nothing between queries. All preprocessing is server-side. When the DB updates, clients are unaffected — only the server re-preprocesses. Within this category:
- Server-stateful schemes (e.g., SealPIR, MulPIR, Spiral, Respire, VIA-C) require the server to cache per-client cryptographic material such as FHE evaluation keys. The server’s storage grows with the number of clients, and each query must be matched to the right key — making queries from the same client linkable across sessions even when network-level privacy techniques like onion routing hide the client’s IP. DB preprocessing cost is usually minimal in these schemes (e.g., FHE plaintext encoding only).
- Server-stateless schemes (e.g., HintlessPIR, YPIR, InsPIRe, VIA) require no per-client state at all. The server preprocesses the DB into a shared structure that all clients use. This is the most operationally clean category. The tradeoff: preprocessing cost tends to be more significant compared to server-stateful schemes, and online communication is typically larger. However, server computation per query is generally better at the frontier of this category.
Client-stateful schemes require the client to download or compute hints that are derived from the DB contents. These hints enable faster, lower-communication online queries — but when the DB updates, hints become stale and must be refreshed, which requires communication between the server and client. The sub-split is about the direction of that communication during hint generation:
- Download-hint schemes (e.g., SimplePIR, DoublePIR): hint generation is server→client only. The server computes hint material and broadcasts it; the client downloads and stores it locally.
- Interactive-hint schemes (e.g., Piano, RMS24, Plinko): hint generation requires client↔server communication. Typically, the client streams the entire database and compresses it into a smaller hint. This is the most cumbersome setting, but among practical schemes it is the only one that achieves sublinear (the server does not have to touch every entry in the database) online server time — scaling slower than the DB size. (In principle, the client’s role in hint generation could be wrapped under FHE and delegated to the server, but this appears prohibitively expensive in practice for now.)
4.2 Operational Profile
| Category | Subcategory | Server per-client state | Preprocessing Cost (Server) | Preprocessing Cost (Client) | Linkability | Examples |
|---|---|---|---|---|---|---|
| Client-stateless | Server-stateful | Eval keys, etc. | Minimal (FHE packing) | None | Yes | SealPIR, MulPIR, Spiral, Respire, VIA-C |
| Server-stateless | None | Moderate (shared across clients) | None | No | HintlessPIR, YPIR, InsPIRe, VIA | |
| Client-stateful | Download-hint | Typically none | Moderate (shared across clients) | Moderate (download hints) | No | SimplePIR, DoublePIR |
| Interactive-hint | Typically none | Moderate (per-client) | Typically heavy (stream entire DB) | Typically no | Piano, RMS24, Plinko |
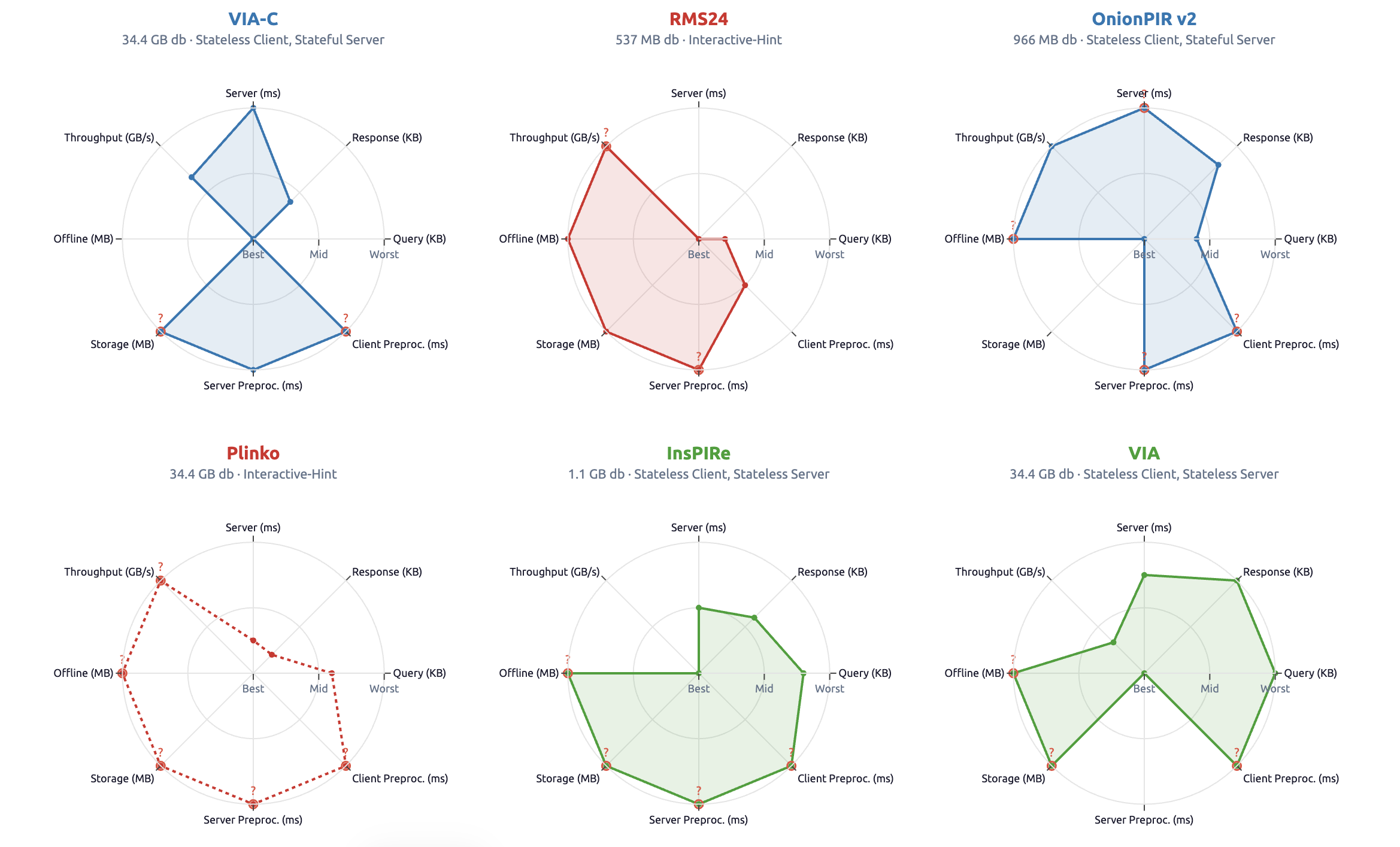
4.3 Comparative Benchmarks
The figure below shows an example set of PIR schemes and the typical metrics for exploring their performance tradeoffs:
5. PIR System Architecture
5.1 Sharding
Logical slices of Ethereum have distinct consumer profiles and contexts, come in different sizes, and can be hot and mutable or cold and immutable.
We juxtapose these data attributes with PIR performance tradeoffs to build a custom sharded privacy-of-reads backend that is abstracted behind a stable interface (not affected by swapping engines/dataset) which different clients plug into: wallets[sdks], frontends, dApps, and nodes.

Key observation: Consider a server that maintains k databases d_1, d_2, \ldots, d_k. A client wishes to access data from one of these databases, say d_i, while hiding which database it is accessing. To this end, the client issues k queries q_1, q_2, \ldots, q_k in some order. The query q_i is a genuine PIR query targeting d_i, while the remaining queries \{ q_j \}_{j \ne i} are decoy queries. Each query q_j lands on an engine n_j that hosts database d_j; each engine processes its query independently and returns a response to the client. Under this construction, the resulting privacy guarantees are equivalent to those obtained if one or more of \{ q_1, \ldots, q_k \} were submitted to a single engine hosting the entire database D = \bigcup_{j=1}^{k} d_j. This approach offers a performance advantage when the queries are processed in parallel: if the target database d_i is relatively small, the client can obtain the desired response with lower latency compared to applying PIR monolithically to the entire database D. Moreover, in regimes where one database d_j is significantly larger than the others, the total communication cost and total server work remain comparable to the monolithic approach.
Security Note: Timing side-channel
In the sharded design, different databases have different sizes and therefore different response latencies. If the client acts on a fast response (e.g., from a small database or sidecar) before responses from larger databases arrive — say, by submitting a transaction — a network-level observer or a server that can correlate client activity with subsequent on-chain actions could infer which database the client genuinely targeted. This partially undermines the decoy-query privacy model.
The straightforward mitigation is to wait for all k responses before acting, but this negates the latency benefit of sharding. This concern is significantly reduced when network-level privacy (Tor, mixnets) is in place, since the observer can no longer correlate the client’s PIR queries with their subsequent actions.
Two further adaptations can help:
- m-of-k querying. Rather than querying all k databases, the client queries a subset of m databases. This reduces the total wait time to the slowest of m responses rather than k. The tradeoff: m-of-k is less private than k-of-k since the server learns that the target is among the m queried databases.
- Continuous decoy traffic. To compensate for m-of-k leaking the subset, the client issues m-of-k decoy query groups at a constant rate in the background. When a genuine query arrives, it is indistinguishable from the surrounding decoy groups — privacy comes not only from the m - 1 decoy queries within the group but also from the stream of decoy groups before and after it.
5.2 Handling DB updates
A core tension in (preprocessing) PIR: the server and/or client invest significant upfront work — the server may precompute data structures over the DB, and the client may stream the entire DB to preprocess it into a compact hint — to enable fast, low-communication online queries. When the underlying DB mutates, these precomputed structures and hints become stale and must be re-derived. For Ethereum, where the state trie changes every ~12 seconds, this is untenable if preprocessing targets the entire dataset.
We categorize databases by their update profile and propose an architectural strategy for each regime.
Dimensions of the update problem
We characterize each database’s update profile along two dimensions:
- Update frequency (relative to DB size). How costly is it to re-preprocess when an update occurs? A small DB or one that updates rarely can simply re-run preprocessing; a large DB that updates every block cannot.
- Churn ratio. What fraction of the DB is modified per update. Append-only data (logs, txs, receipts) is a special case of low churn — new entries are added but no existing entry changes.
These dimensions yield three regimes:
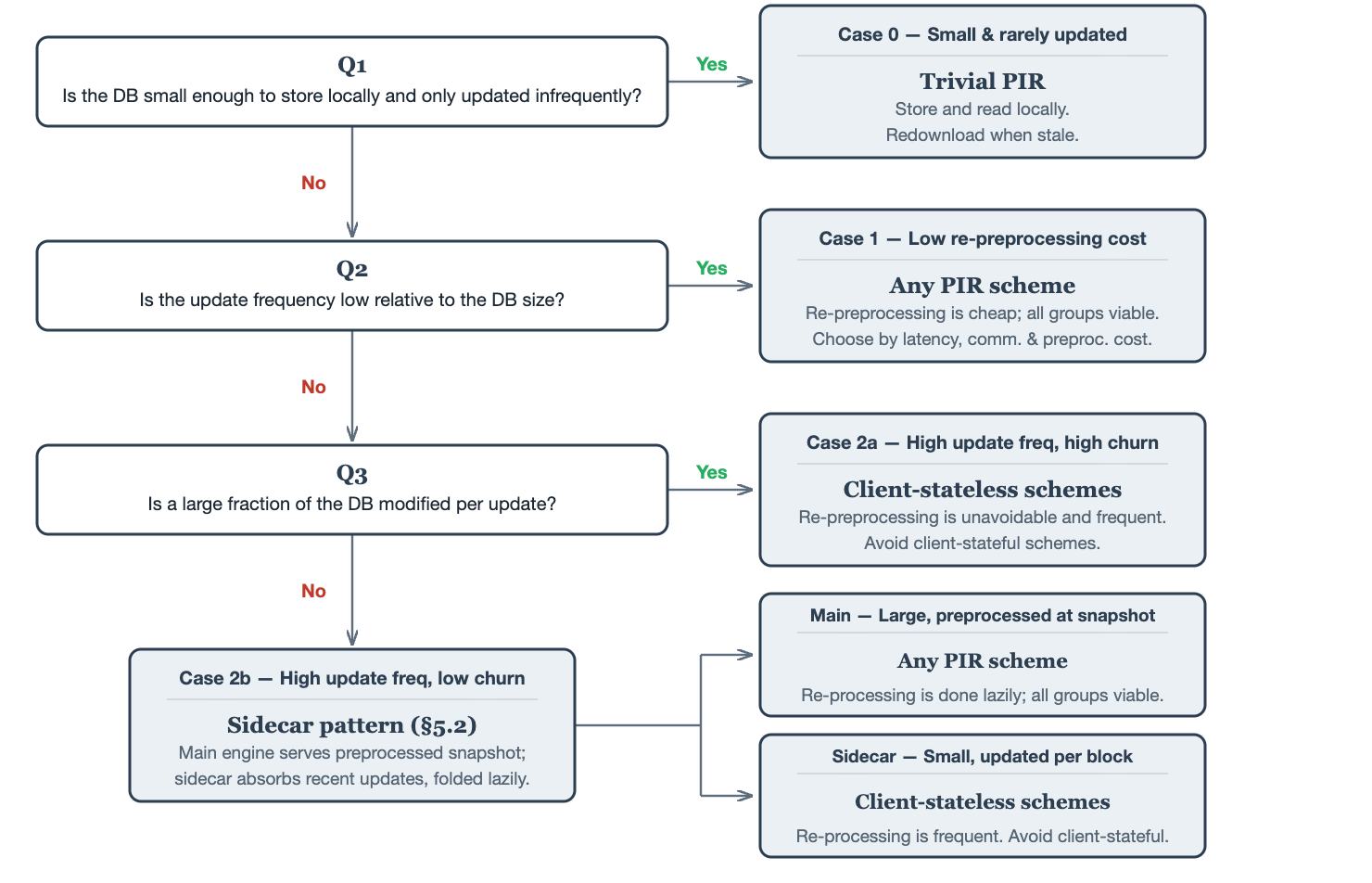
Case 1: Re-preprocessing cost per update is low
Re-running preprocessing per update is not a major issue.
This covers databases that are either small (cheap to re-preprocess regardless of frequency) or large but rarely changing (re-preprocessing is infrequent).
| Ethereum example | Size | Update freq | Why it fits |
|---|---|---|---|
| Contract bytecode | Small | Never | Small + immutable |
| Latest headers | Small | Per-block | Small enough that per-block re-preprocessing is cheap |
| Archival state snapshots | Large | Never (historical) | Immutable once finalized |
Architecture: Straightforward preprocessing. Re-preprocess on every update — this is affordable since either the DB is small (cheap per re-run) or updates are infrequent (rare re-runs). No special update machinery needed.
Case 2a: Update frequency is high relative to DB size, high churn
Cannot avoid re-running preprocessing. Minimize its cost.
When the DB is large, updates are frequent, and a large fraction of entries change per update, incremental approaches offer little savings — most hints are invalidated anyway. This case is rare in Ethereum (even at peak load, state churn is a small fraction of the total trie) but could arise in other domains.
The key constraint: avoid Client-stateful PIR schemes. If re-preprocessing is unavoidable and frequent, client-dependent preprocessing burdens both sides: the client must redo its preprocessing work on every update, and the server must redo per-client work for each client. Both scale poorly under high update frequency.
Case 2b: Update frequency is high relative to DB size, low churn
This includes the append-only case. Use a sidecar architecture with lazy re-preprocessing.
The DB is large and updates frequently, but only a small fraction of entries change per update. Existing hints are mostly still valid — we just need to handle the updated entries.
| Ethereum example | Size | Update freq | Churn | Why it fits |
|---|---|---|---|---|
| Live state trie | Large | Per-block | Low (~thousands of keys out of billions) | Large DB, frequent updates, tiny changeset |
| Transactions, logs, receipts | Large | Per-block | Low (new entries only) | Large DB, frequent appends, no mutations |
| Blobs | Large | Per-block | Low (new entries only) | Same as above, with bounded retention |
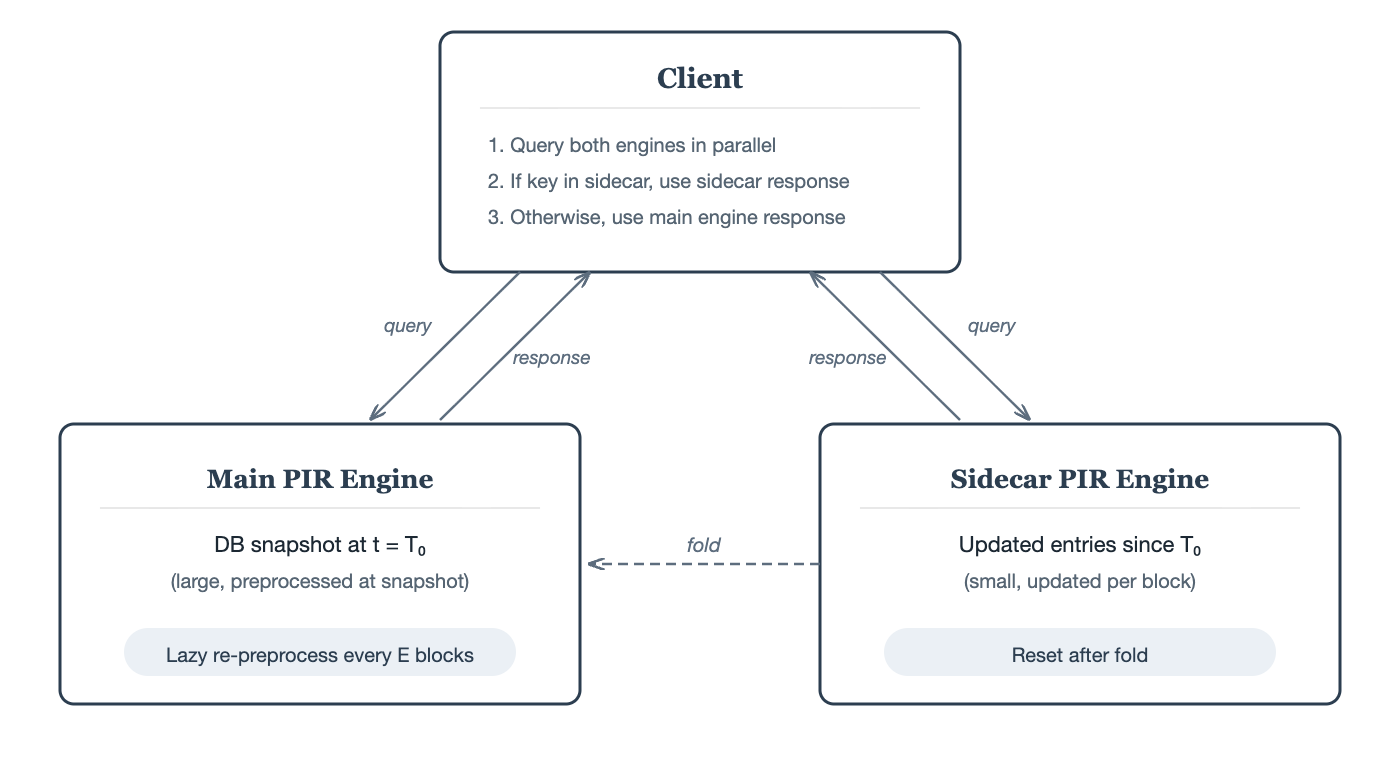
5.3 Architecture — the sidecar pattern
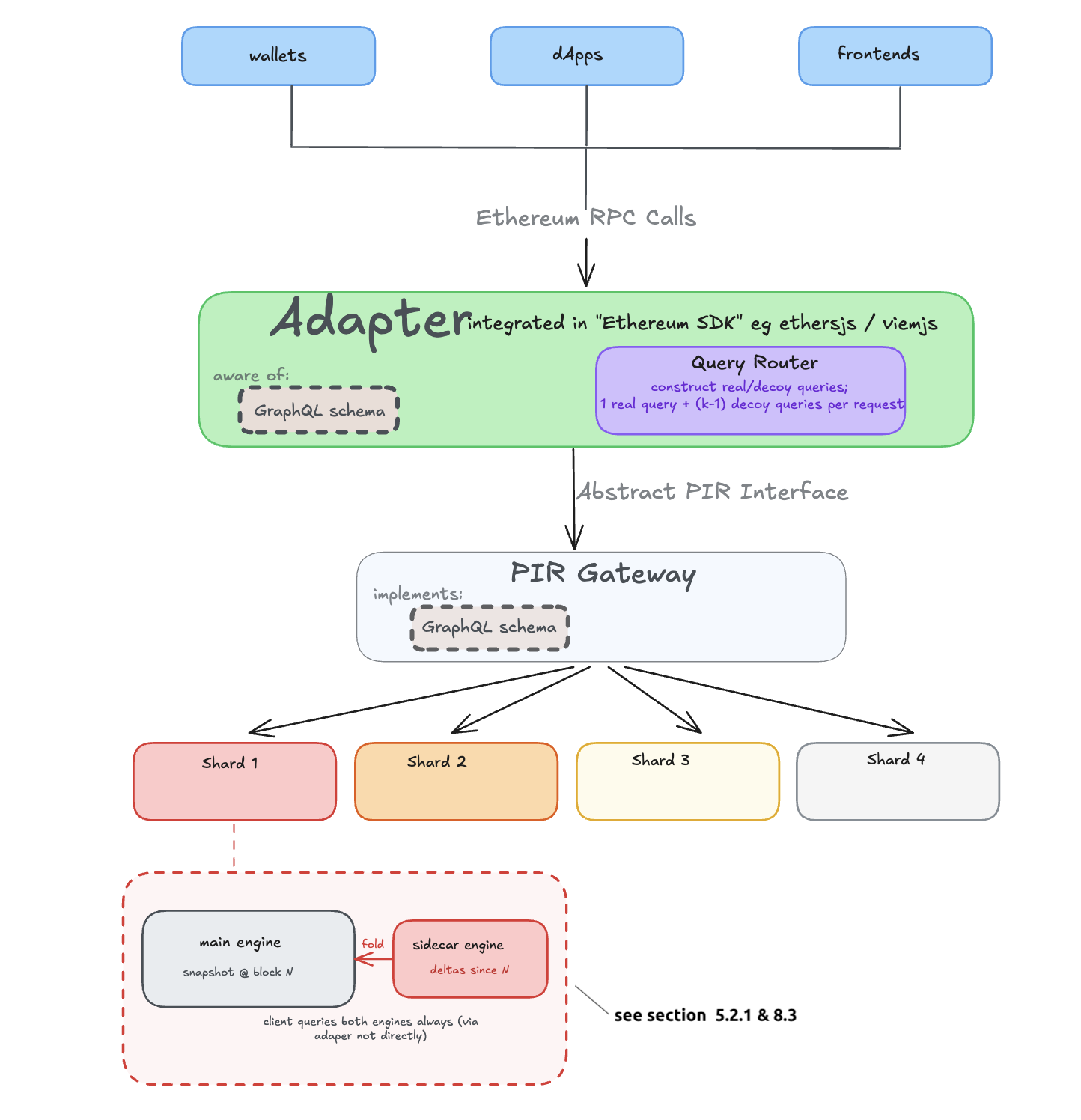
The main PIR engine hosts the bulk of the data, preprocessed at some reference snapshot. A small sidecar PIR engine hosts the full updated entries for keys that have changed since the last snapshot. To answer a query, the client queries both in parallel:
- The main engine for the base snapshot (using preprocessed hints — fast, low communication).
- The sidecar engine for updated entries (small DB, so even a non-preprocessing scheme is cheap here).
Since the sidecar holds full values, the client can use the sidecar’s response as soon as it arrives — if the queried key was updated, the answer is self-contained and the client does not need to wait for the main engine. The client only falls back to the main engine’s response if the key is absent from the sidecar.
Periodically (lazily — e.g. every E blocks, or when the sidecar grows beyond a threshold), the sidecar’s entries are folded into the main DB and preprocessing is re-run. The sidecar is then reset. The key property: re-preprocessing happens in the background at a relaxed pace, not on the critical path of every update. The sidecar absorbs the real-time update pressure. During the fold, the old main engine continues serving queries while the new preprocessed version is built. Once ready, the client switches over and the sidecar resets to accumulate only entries updated since the new snapshot.
For append-only databases, the sidecar is even simpler: it only holds new entries. The main engine’s hints are never invalidated, so re-preprocessing the main engine is purely about absorbing the sidecar’s accumulated entries to keep the sidecar small.
Security Note:
Re-preprocessing must be consistent across databases — if a client re-preprocesses one database but not another, the discrepancy could leak which one it genuinely targets.
6. PIR Scheme Selection
The taxonomy in Section 4 classifies PIR schemes by their structural properties. The decision tree below inverts this: given the characteristics of a database and its consumers, which group of schemes is the best fit?
7. Universal PIR interface
There are two realities that any PIR system in the Ethereum context must adapt to:
- The edge (wallets, frontends, dApps, ..) must be able to continue expressing their queries using the very same Ethereum RPC calls, as they do now.
- PIR backends must be able to continue evolving without impacting the edge: swapping schemes, changing database slices, changing key-to-index adapters, ..
The challenge then becomes in having a middleware that satisfies these two requirements with clean abstraction such that changes in either side does not affect the other. The middleware itself should only be aware of an abstract PIR interface that is concretely implemented by each PIR scheme (engine).
One possible way to do this:
- Define a GraphQL schema that is fixed, because the structure and semantics of the Ethereum state is ~unchanging (esp. after the UBT upgrade)
- Implement a client-side adapter that sits between the canonical rpc handling logic and the schema. In practical terms, this would wrap the existing RPC handling logic on the client side.
Key considerations:
- Where and how the adapter is integrated at the edges. One attractive option is in the few wallet SDKs (which are also integrated by frontends) such that the many edge clients that integrate do not absorb any concerns.
- How to handle client-dependent preprocessing for PIR schemes that require it, and how tightly preprocessing logic and associated storage is coupled with the adapter.
The figure below sketches a rough design (details are left to a future post).
8. Ongoing research & optimizations
8.1 PIR for Merkle trees
Client-side verifiability is a requirement of this design (Section 2). The most natural approach — given Ethereum’s existing eth_getProof RPC method — is to verify each value against a trusted root via Merkle proofs. This means the client needs not just the leaf value but the sibling hashes along the path from the leaf to the state root. Under PIR, retrieving this proof is non-trivial.
There are two baseline approaches:
Baseline 1: per-level PIR instances. Maintain a separate PIR database for each tree level. The client issues one PIR query per level. In tries — such as Ethereum’s MPT and UBT — the path is fully determined by the key, so all per-level queries are known upfront and can be processed in parallel. This property does not hold for all tree structures in general.
In a trie with branching factor b and N leaves, each level below the point where keys have diverged (roughly below depth \log_b N) contains approximately N nodes, and each level of the proof requires b - 1 sibling hashes. Pessimistically, the total cost across all D levels is b \cdot D times the cost of querying a single level of size N.
In practice, D need not be the worst case (256 for UBT, 64 for MPT). With uniformly distributed keys and N \approx 10B:
- UBT (b = 2, realistic upper bound D \approx 40): the top \log_2 N \approx 33 levels have sizes that grow as 1, 2, 4, \ldots up to N — their total contribution is bounded by \sim 2N due to geometric decay, leaving D - \log_2 N \approx 7 levels that each cost \sim N. With b - 1 = 1 sibling per level, total overhead: \sim 9\times.
- MPT (b = 16, realistic upper bound D \approx 10): the top \log_{16} N \approx 8 levels grow as 1, 16, 256, \ldots up to N — their total contribution is bounded by \sim \frac{16}{15}N \approx 1.07N due to the faster geometric decay of the wider branching factor, leaving D - \log_{16} N \approx 2 levels at full cost. With b - 1 = 15 siblings per level, total overhead: \sim 48\times.
Baseline 2: pre-attach proofs to leaves. Concatenate each leaf’s full Merkle proof directly into its PIR database entry. A single PIR query returns the leaf and its proof in one shot — but entry size blows up, increasing server storage:
- UBT (b = 2, realistic upper bound D \approx 40): proof is D \times 32 = 1{,}280 bytes per leaf. This is a ~40× blowup.
- MPT (b = 16, realistic upper bound D \approx 10): proof is D \times (b-1) \times 32 = 10 \times 15 \times 32 = 4{,}800 bytes per leaf. This is a ~150× blowup.
Additionally, the server must precompute and attach a proof for every leaf in the database, which adds significant preprocessing time proportional to the total number of leaves and the tree depth.
Where is the sweet spot? Intermediate strategies exist — for instance, pre-attaching partial proofs covering the top k levels (which are shared across many leaves and thus most storage-redundant) while querying the remaining bottom levels via separate per-level PIR instances. This reduces both the number of separate PIR databases and the per-entry blowup. Whether better approaches exist beyond this straightforward hybrid, and how the optimal split point depends on the PIR scheme’s cost profile, remains an open question.
8.2 verifiable UBT > MPT
We can use the binary state trie today, reaping its benefits, if we prove its equivalence to canonical MPT, which we can. This reduces the size of the PIR db hosting the merkle roots of the state, as one example benefit.
This also simplifies other potential optimizations, see eg the snarkification of archival state below.
The way it works is simple: the public input to the UBT STF prover is a canonical zkVM proof of the next L1 block + the block body. The application of the block + running the verifier to the zkVM proof is done within the zkVM proving of the UBT STF (ie the guest program is the UBT-enabled Ethereum node).
Two ongoing approaches to achieve this:
- Proof the execution of UBT-Keeper (stateless Geth) with OpenVM via WOMIR; see ~34:00 ~ 40:00 in this lecture for keeper → wasm → openvm. A prerequisite to this is the conversion of existing MPT state to UBT which is WIP.
- Prove the execution of EIP7864-ready Ethrex and include in it a proof of the verifier of mainnet Ethrex zkVM proof. This is also WIP.
8.3 Isolating mutability
See also the sidecar <> main-engine design in Section 5.
The high-level rationale is:
Some Ethereum datasets are updated with every block, but in append-only fashion. This includes blocks (which encompass list of transactions and receipts), blobs, and the historical state snapshots.
We can get away with having to update the dataset and incur the update cost of some PIR schemes by snapshotting at, say, the 1st day of the year. For example, on January 1st 2026 we take the snapshot of all blocks, do the required preprocessing on that dataset, and never have to update it again. Block data >= Jan 1st (which would be massively smaller than former) is maintained in a dedicated dataset that is update-optimal.
This approach allows us to use large-db-size-efficient scheme for the forever immutable non-appendable slice, while using update-efficient scheme for the smaller but volatile set, until the latter becomes too large to be efficient for the current scheme (update-cost-wise) and needs to be “immobilized” and wrapped with a different scheme.
Routing RPC read calls depending on the blockNumber parameter to hit the right dataset from amongst the two is trivial (client is aware of the schema, which defines the cutoff between immobilized and “active” dataset as a function of time, measured in block numbers).
Similar approach can be followed for blobs and historical snapshots.
8.4 SNARKifying the archival state to reduce db size
- This section assumes the Ethereum state is UBT so there are no ‘extension nodes’, it’s a single unified trie.
- In the UBT regime there is no storageRoot in the account header; a snark proving the validity of an account header attests only to nonce/balance/codehash
- For now this discussion does not take into account ‘overflowing’ stems that store storage 64th+ storage slots. Unlike in MPT where a proven
storageHashcould in turn prove validity of arbitrary storage slots, here in ubt a proven account header is only useful for proving slot 1-63 (“lower roots” in schematic below)
The size of the Ethereum archival state is dominated by the Merkle roots, which users need to independently verify queries like: what was my ETH balance at block N << latest block and how do I independently verify that?
The user could instead verify a SNARK attesting to the validity of that balance, instead of: fetching the Merkle roots and hashing their way to the state root, followed by either a verification of the chain of block headers or (in the future) verifying the zkVM proof of that historical block’s state root.
Assume every Ethereum block has a zkVM proof P_s (as in state). The proof has a witness (or trace) W_s associated with it as public input.
We do a zkVM proof of the corresponding archival node’s update for that block, P_h (as in history). This proof:
- Verifies P_s taking W_s as public input. Notice that such proof automatically proves the link between this block and the entire chain of blocks since genesis.
- Applies W_s to get the history snapshot at that block.
- For every touched account-header
stemNodei in W_s, a proof p_i of the merkle path to the block header is generated (ie proving correct hashing of the merkle path leading to the zkVM proven state root, proven by P_s). Recall these are the merkle paths that we want to do away of sending to clients inquiring “prove to me my eth balance was 1 ETH at block N”. - A side key-value table that tracks (
leaf,last_edited) is updated with current block number. - The hash of the key-value table is part of the header of the archival node.
- Verifies the previous P_{h-1} << this recursion creates a chain of trust for all the headers of the archival node.
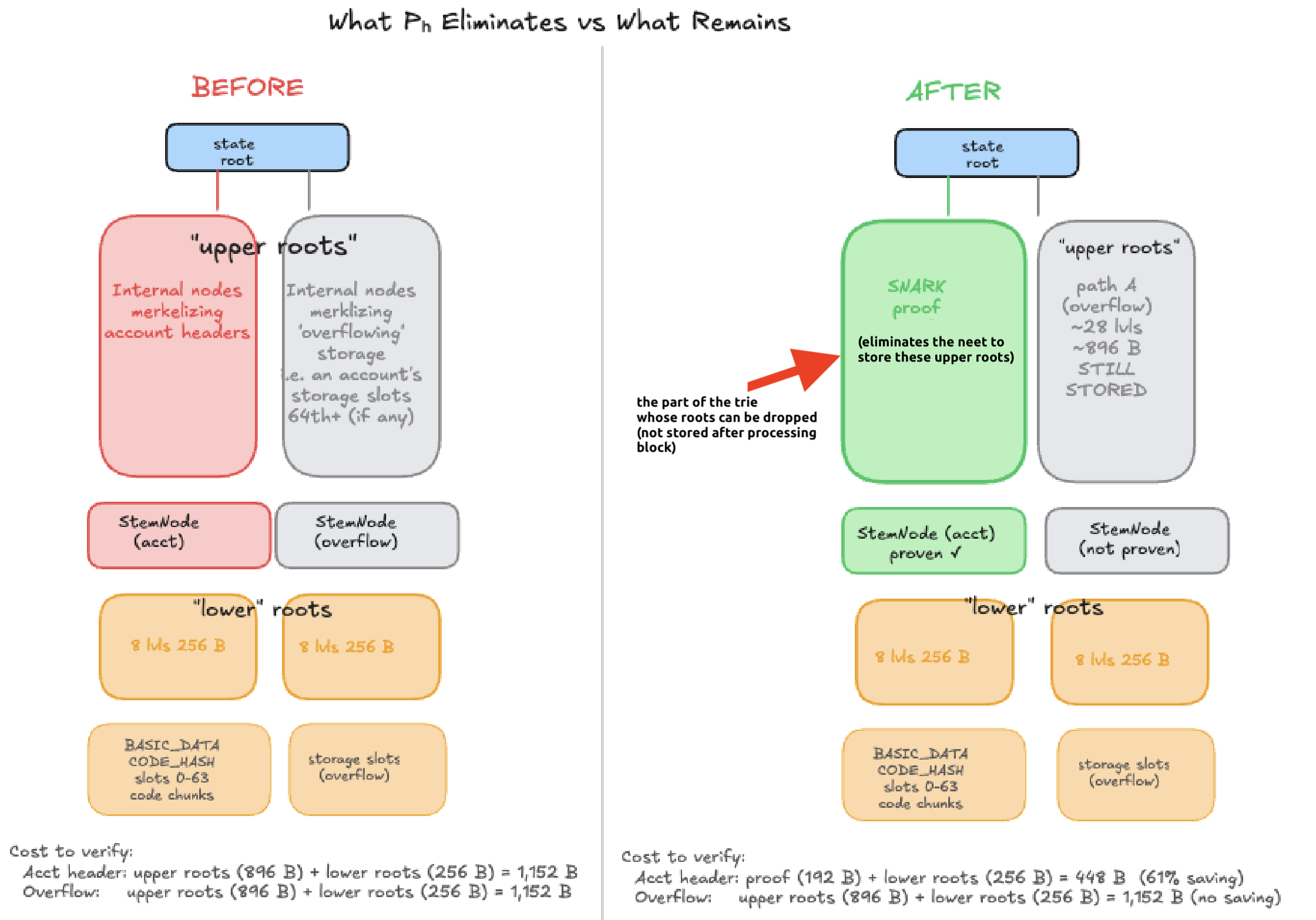
Note: zk proofs of touched leaves in a block could be stored in a trie analogous to tx’s/blocks (this aspect isn’t detailed here).
There are 3 types of “leaves”:
- Account headers (balance, nonce, codehash, ..): the merkle roots for these lead up to the block’s state root
- Storage slots 1-63 under an account header
- Storage slots 64+ : these are stored and merklized independently in the trie (though their location is deterministically derived from address)
A snark proving the validity of changes to #1 (and only that) means:
- No Merkle roots are needed for proving balance, nonce, codehash
- For storage slots 1-63, Merkle roots from values of these slots to the account header still need to be served to light clients
- Storage slots 64+ (if they exist for a given account) need the full path (“upper roots” in schematic above) to the block state root of the block (because they are stored independently).
- Todo estimate savings per year given projected gas limit increases
The proof that a certain account-header stemNode has not changed since the last time it was edited is ensured by the fact that the archival state update applied exactly the set of transactions that were proven by the P_s’s. Had the account changed and not been updated would imply that the some state transition of the archival state was invalid, but that is not possible because every such transition is recursed with the proof of the previous block (step 6 above).
Analogous to the per block Transaction Trie and Receipt Trie, we have (in this modified archival node) a SNARKs Trie hosting all the generated snarks for all account headers that were touched in this block.
8.5 Delegating hint generation in interactive-hint schemes
Interactive-hint schemes (e.g. Piano, RMS24) are the only practical single-server PIR schemes that achieve sublinear (the server does not have to touch every entry in the database) online server time — but they require the client to stream and process the entire database during hint generation. The client remains stateful (it holds hints) and must re-interact with the server when the DB updates.
As noted in Section 4.1, the client’s role in hint generation could in principle be wrapped under FHE or distributed via MPC and delegated to the server or a set of helpers, reducing the client’s computational and bandwidth burden. (Note that the client is still stateful; the question here is about minimizing the client-side cost of hint generation.) In practice, this delegation appears prohibitively expensive today. Making it concretely efficient would unlock the best online performance (sublinear server time) for resource-constrained clients.
8.6 Concretely efficient DEPIR
Doubly Efficient PIR (DEPIR) is, in terms of the taxonomy in Section 4, a client-stateless scheme — the client holds no hints or state — but with asymptotically sublinear (the server does not have to touch every entry in the database) server-side cost per query after preprocessing. This combines the operational simplicity of client-stateless PIR with the (asymptotic) online performance that today only client-stateful schemes (Piano, RMS24) achieve.
The gap is concrete efficiency. The constants hidden in asymptotic bounds place existing DEPIR constructions orders of magnitude behind practical PIR schemes on real databases. DEPIR today is a theoretical result — asymptotically superior but concretely not even competitive.
A concretely efficient DEPIR matching the online performance of client-stateful schemes would dramatically simplify the PIR landscape: a single client-stateless scheme with sublinear per-query cost could serve all data slices, eliminating the need to shard by PIR performance tradeoffs.
9. Resources
- Tutorial: Vitalik’s tutorial on Plinko
- Spec / reference code: RMS24 & Plinko
- Benchmarks reported in the literature
- Engineering notes
- Implementations: Plinko RMS24 [InsPIRe] [2] [3] OnionPIRv2 Piano CwPIR DistributionalPIR DoublePIR FastPIR FrodoPIR HintlessPIR NPIR Pirouette Respire SealPIR SimplePIR Spiral XPIR YPIR
- PIR schemes referenced in this post: SealPIR, MulPIR, Spiral, Respire, HintlessPIR, YPIR, InsPIRe, VIA, VIA-C, SimplePIR, DoublePIR, Piano, RMS24, Plinko