Summary & TL;DR
The ProbeLab team (probelab.io) is carrying out a study on the performance of Gossipsub in Ethereum’s P2P network. Following from our previous post on the “Gossipsub Network Dynamicity through GRAFTs and PRUNEs” in this post we investigate the number of messages and duplicated messages seen by our node, per topic. There is no public data on the overhead that broadcasting messages and control data over the network imply on each participating node.
For the purposes of this study, we have built a tool called Hermes, which acts as a GossipSub listener and tracer (GitHub - probe-lab/hermes: A Gossipsub listener and tracer.). Hermes subscribes to all relevant pubsub topics and traces all protocol interactions. The results reported here are from a 3.5hr trace.
Study Description: Gossipsub’s design is inherently allowing for message duplicates. A brief model we develop shows that it’s normal to receive each message up to 3 extra times (as a duplicate). This excludes the gossip mechanism which propagates messages through the IHAVE/IWANT control message sequence.
TL;DR: We find that indeed duplicates through mesh stay in the order of 3 per message or below, which, however, doesn’t count for duplicates through gossip. For instance, there are edge cases where a message is requested (and responded to) through an IWANT message while the actual message is already in transit. Eventually, this results in an extra duplicate. We make two recommendations:
- Reduce the number of concurrent
IWANTmessages we send through a limiting factor (somewhat similar to kademlia’salphaparameter). - Lower the current
heartbeatfrequency (i.e., increasing theheartbeatinterval) from 0.7 seconds to 1 second (as per the original protocol spec and recommendation). This would reduce the excessiveIHAVEmessages and reduce the chances of generating extra duplicates.
Background
GossipSub is a routing system that can be enabled on libp2p’s PubSub message broadcasting protocol. This protocol organizes the message broadcasting channels on what is commonly known as Topics, where peers subscribed to a given topic keep a particular subset of connected peers for that particular topic. This subset of peer connections per topic is also known as “mesh”.
In the case of GossipSub, the standard broadcasting mechanism of PubSub is extended with a few sets of enhancements that make it:
- more efficient than what is commonly called flooding, reducing the protocol’s bandwidth usage
- more resilient, as the protocol:
- shares metadata of seen messages over sporadic Gossip messages (for censorship or Sybil attacks)
- keeps a local score for each mesh-connected peer to ensure healthy and useful connections, where each peer keeps connections with the highest scoring neighbours
- avoids sharing a message with peers that already sent the message to us
This all looks good on paper. However, there is still no public data on the overhead that broadcasting messages and control data over the network imply on each participating node. Even more importantly, how much room for improvement exists within the protocol and the implementations to make it more optimal.
Expected Results
Message propagation through the GossipSub’s mesh considers some occasional duplicates that can arrive as the message might come from different peers within the mesh:
Given:
nas the number of nodes in the graphkas the mesh degreelas the number of connections (links) between two nodes l = \frac{nk}{2}
The number of links used to propagate a message to all nodes in the graph can be defined as n-1 ~= n. The links form a spanning tree with the message origin as root (n is big enough compared to the initial sender link, so that it can be considered negligible).
The number of links not used to propagate a specific message corresponds to l-n = \frac{n(k-2)}{2}.
This means that on average each node will have 1 link used to receive a message, 1 to propagate it to a peer that doesn’t have it yet. And the rest k-2, to either send or receive the duplicate message.
Assuming that \frac{k-2}{2} links are used to send the message to peers that already have it, it means that we receive \frac{k-2}{2} duplicate messages.
In the case of Ethereum, k=8, and therefore, it follows that \frac{k-2}{2} = 3. So, the expected value is to receive 3 duplicate messages for each message.
Results
As previously introduced, this report aims to provide insights on:
- the number of duplicate messages that we receive per each shared message in the network,
- the extra bandwidth that we are spending on duplicates,
- any existing unexpected behavior or potential optimization that could be applied on GossipSub.
NOTES:
The numbers presented in the following sections belong to the same 3.5 hours run ofHermesas the previous studies, with the following extra configuration:
- The experiment is ran on the
Holeskynetwork- Our node was subscribed to the following topics:
beacon_blockbeacon_aggregate_and_proofsync_commmittee_contribution_and_proofattester_slashingproposer_slashingvoluntary_exit* (checkHermesissue → Broadcasting of invalid `voluntary_exit` messages to mesh peers · Issue #24 · probe-lab/hermes · GitHub)bls_to_execution_change
Overall Number of Messages
To give a little bit of context, the report starts by taking a look at the number of messages and the respective duplicates received over time. The following graph shows the number of HANDLED events by the libp2p-host in comparison with the DELIVERED and DUPLICATED ones.
NOTE: In this report we will consider the
DELIVERevents as unique identifier of the arrival of a message. This is because the internal event tracer at the libp2p host notifies of the arrival of a unique message at multiple levels, which in turn, makes theHANDLEDandDELIVERevents at the arrival of a new message the exact same notification, just at different levels of the host.
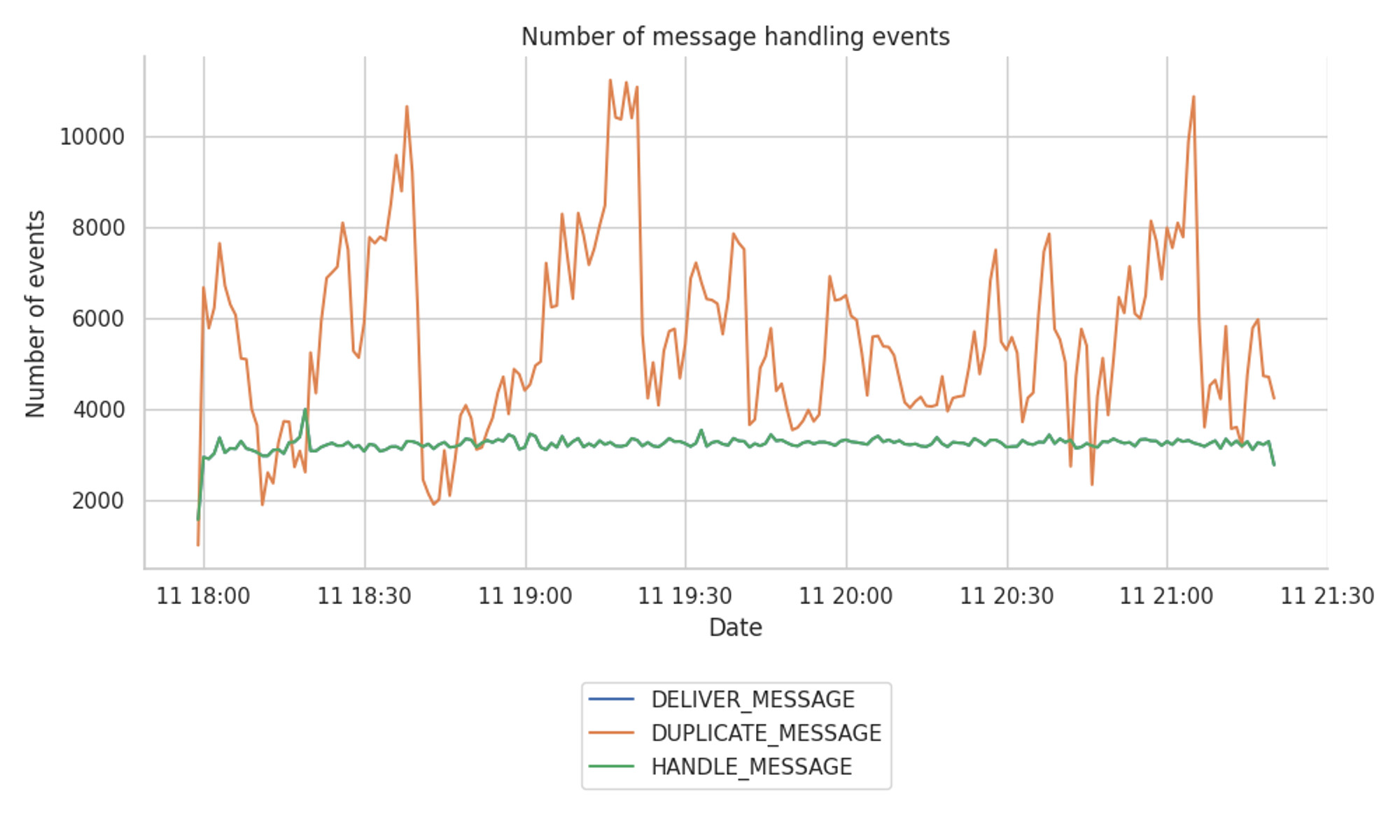
- The number of unique messages (i.e.,
HANDLE_MESSAGE) stays steady around the 3,000 and 3,200 unique messages per minute. - By looking closer into the messages per topic (not shown here), we observe that the topic with the highest message frequency is the
beacon_aggregate_and_proofone, receiving over 90% of the tracked unique messages. - There are some duplicated spikes at the
beacon_blocktopic that reach up to 60 duplicates in some occasions. - The number of duplicates seems to vary quite wildly over time, which can be related to the number of connections per mesh (as per the analysis done further up which showed that 3 duplicates per message are expected).
Number of Duplicate Messages
When it comes to the actual number of DUPLICATE messages, the following figures show that number of duplicates can oscillate over time.
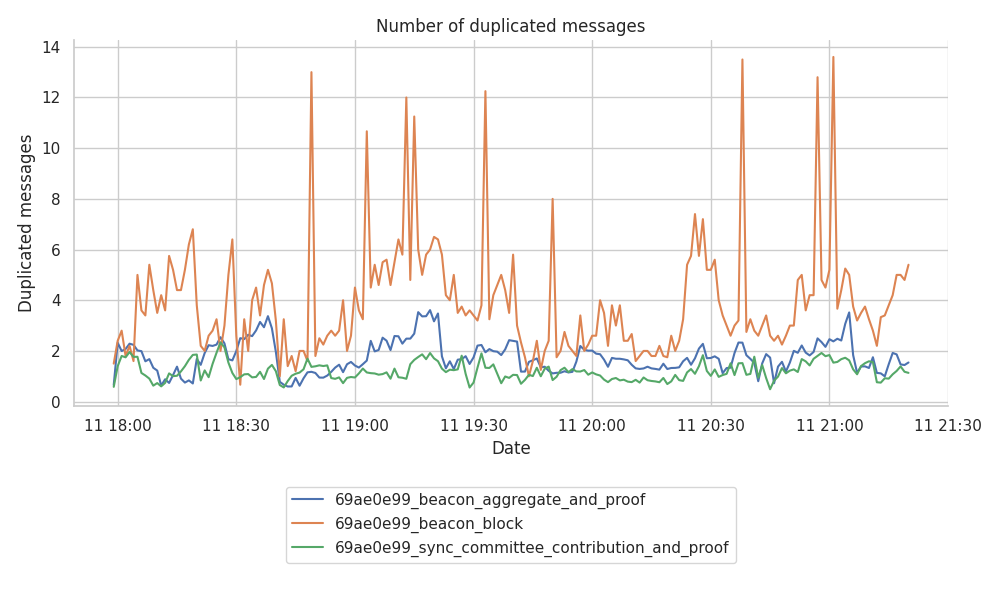
Clearly, the beacon_block topic seems to be the only one generating the largest number of spikes at times.
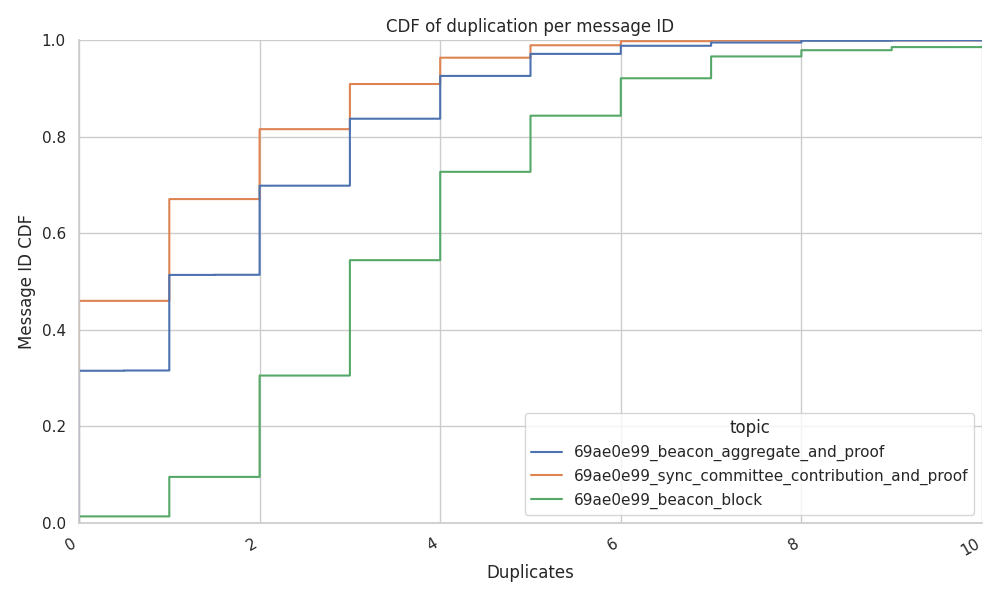
CDF of Duplicate Messages
The following graph shows the Cumulative Distribution Function (CDF) of the duplicates per message per topic. In the graph, we can see that:
- smaller but more frequent messages like the
beacon_ggregate_and_proofandsync_commitee_contributionsdo have fewer duplicates.- between 32% and 45% of the messages do not have any duplicates.
- 50% of the messages are received with less than 2 duplicate messages, keeping the mean lower than the theoretical target of
3duplicates per message. - the upper tail shows that less than 10% of the messages get more than 4 duplicates, with a cap at 8-10 duplicates (i.e., the node’s mesh size,
D).
- the case of the
beacon_blocksis completely different.- there are almost no recorded messages without duplicates (1%-2%).
- 54% of the messages report the expected
3duplicates from the mesh - Taking look at the tail of the CDF (shown in the dropdown plot further down) there are a few messages that were received up to 34 or 40 times.
Correlation between Message Size and Number of Duplicates
From the CDF above there seems to be a pattern of “the bigger the size of the message, the more duplicates it has”. So we went a step further to investigate if there is indeed a correlation. The following graph shows that the correlation between the size of a message and the number of duplicates is somewhat present but is not a norm or at least doesn’t follow any fixed pattern.
The figure is complemented by two auxiliary quartile plots or “boxplots”, which represent the given distribution of points of their respective axis, helping us understand that:
sync_commmittee_contribution_and_proofmessages are the smallest ones in size, which also correlates with the smallest ratio of duplicate messages.beacon_aggregate_and_proofmessages are the second ones in size, having also a bigger tail of duplicates on the Y concentration plot.beacon_blockmessages, despite being the ones with the widest variation in size, do not follow any particular pattern that could correlate the message size with the number of duplicates.
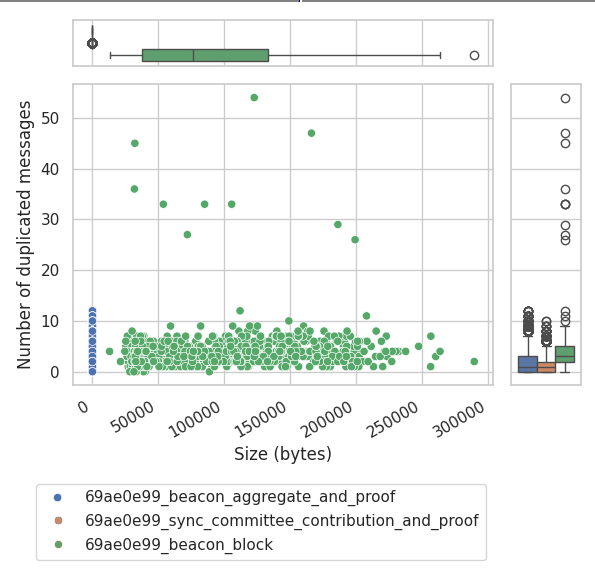
As such, we conclude that there is no correlation between message size and number of duplicates.
Arrival Time of Duplicates
Reducing the number of duplicates has already been a topic of discussion in the community. There are already some proposals like gossipsub1.2 that spotted this large number of duplicated messages previously, proposing the addition of a new control IDONTWANT message that could not only notify other peers that we already got a message, but also cancel the IWANT ongoing messages.
In order to see how effective the IDONTWANT control message would be, we’ve computed the time between the first delivery of each message and their respective first duplicate. This is done to validate that there is enough time to send the IDONTWANT message once a new message is received (prior to the message validation) and before the duplicate starts being sent over.
The following graph gives the time between the delivery time of a message and the time to the first duplicated message in seconds.
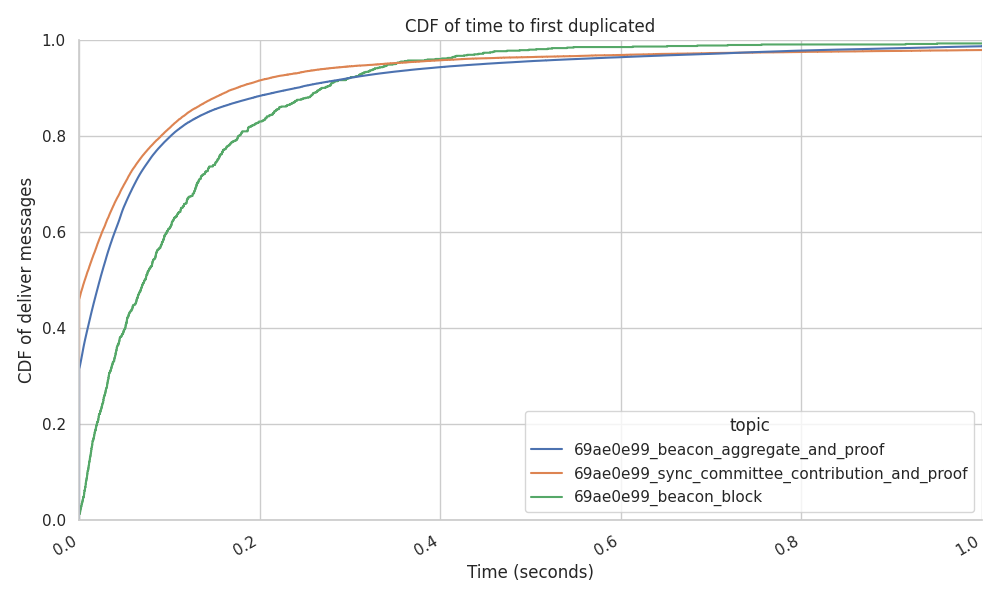
Results show that 50% of the duplicated beacon blocks arrive within 73 milliseconds, roughly an entire Round Trip Time (RTT) with a well connected peer. In practice, this means that the IDONTWANT message could prevent at least the other 50% of messages that arrive between 73 milliseconds and 2 seconds of the first arrival.
We’ve spotted that a big part of the duplicated messages arrive from IWANT messages that we sent milliseconds before the arrival of the same message though the mesh.
The gossipsub1.2 proposal already contemplates this scenario, where the same IDONTWANT message could break or stop any ongoing responses to IWANT messages for that msgID.
In summary, we conclude that the IDONTWANT control message addition to Gossipsub will be a valuable enhancement that can indeed prevent the vast majority of duplicate messages.
Conclusions and takeaways
This set of conclusions have been extracted from running the
go-libp2pimplementation and, although it also involves the traces of how other implementations interact with Hermes, it might be a biased conclusion from the point of view of the Go implementation.
-
We have identified that there is no limit on the number of peers that we simultaneously send
IWANTmessages to for the samemsgID.
We identify that this has some benefits:- Concurrently fetches the message from multiple actors.
- Bypasses bandwidth limitations of peer(s) we have sent
IWANTmessages to, since we have forwarded theIWANTmessage to multiple peers.
However, it also has obvious downsides:
-
We receive multiple duplicates from the peers that respond to our simultaneous
IWANTrequest, consuming more bandwidth on both ends. -
The message could be already on the wire through the mesh connections, so when the
IWANTmessage responses arrive, the message was already delivered through the mesh. -
There is no track of who we contacted for a given message, given that Gossipsub is:
- forwarding the message only the first time we see it, and
- removing the peer that sent us the message from the list of peers we’re broadcasting the message to and forgetting about that peer.
This makes the entire broadcasting process unaware of who sent us that message in
IHAVEs, or who we are already contacting for a particular message - resulting in multiple duplicates.
Canceling ongoing
IWANTmessages withIDONTWANTmessages, which is a proposal included in gossipsub1.2 is a valuable enhancement that will limit the number of duplicates.Recommendation 1
We propose having a limiting factor (somewhat similar to kademlia’s
alphaparameter), which would limit the number of concurrentIWANTmessages we send for the samemsgID.
-
The gossiping mechanism of Gossipsub acts as a backup mechanism to the broadcasting/mesh propagation part of the protocol for those messages that didn’t manage to reach all nodes in the network. The more frequent gossiping is, the higher its contribution becomes to message propagation (i.e., more messages are being requested through
IWANTrequests because they have not reached the entirety of the network).An edge case that results from very frequent gossiping (i.e., small
heartbeatinterval) is that messages that are already in transit, but have not been downloaded completely, are being requested through anIWANTmessage. This inevitably results in a duplicate message once both messages arrive at their destination.It is hard to quantify how often the message responses to
IWANTmessages are indeed future duplicates, but it is still worth pointing out that high heartbeat frequency increases the chances of those edge cases.Recommendation 2
A quick and straightforward optimization is to lower the current
heartbeatfrequency (i.e., increasing theheartbeatinterval) from 0.7 seconds to 1 second (as per the original protocol spec and recommendation). This would reduce the excessiveIHAVEmessages and reduce the chances of generating extra duplicates.
-
We have spotted some edge cases that may occur due to the “lack” of control over the triggered events at GossipSub (
IHAVE/IWANT).It isn’t easy to judge from the logs whether those cases are just a matter of timing, as GossipSub replies to those events as interruptions (at least in the Go implementation), or if some of those cases are caused by a bug in one of the implementations.
We found that the number of messages where we received multiple duplicates from the same peer to just 1% of the total number of
beacon_blocksreceived. We, therefore, conclude that this is not critical or an issue that requires further investigation.
For more details and weekly network health reports on Ethereum’s discv5 DHT network head over to probelab.io.