Special thanks to Micah Zoltu, Toni Wahrstätter, Justin Traglia and pcaversaccio for discussion
The most common criticism of increasing the L1 gas limit, beyond concerns about network safety, is that it makes it harder to run a full node.
Especially in the context of a roadmap focused on unbundling the full node, addressing this requires an understanding of what full nodes are for.
Historically, the thinking has been that full nodes are for validating the chain; see here for my own exposition of what could happen if regular users cannot verify. If this is the only issue, then L1 scaling is unlocked by ZK-EVMs: the only limit is keeping the block building and proving costs low enough that both can remain 1-of-n censorship-resistant and a competitive market.
However, in reality this is not actually the sole concern. The other major concern is: it’s valuable to have a full node so that you can have a local RPC server that you can use to read the chain in a trustless, censorship-resistant and privacy-friendly way. This document will discuss adjustments to the current L1 scaling roadmap that make this happen.
Why not stop with trustlessness and privacy via ZK-EVM + PIR?
The privacy roadmap I published last month focuses on TEEs + ORAM as a short-term patch plus PIR as a long-term solution. This, together with Helios and ZK-EVM verification, would allow any user to connect to external RPCs and be fully confident that (i) the chain they are getting is correct, and (ii) their data privacy is protected. So it is worth asking the question: why not stop here? Don’t these kinds of advanced cryptographic solutions make self-hosted nodes an outdated relic?
Here I can give a few replies:
- Fully trustless cryptographic solutions (ie. 1-server PIR) will be expensive. Currently the overhead is impractically high, and even after many efficiency improvements it is likely to stay expensive.
- Metadata privacy. The data of which IP address makes requests at what times, and the pattern of requests, is itself enough to reveal a lot of information about users.
- Censorship vulnerability: a market structure dominated by a few RPC providers is one that will face strong pressure to deplatform or censor users. Many RPC providers already exclude entire countries.
For these reasons, there is value in continuing to ensure greater ease of running a personal node.
Short-term priorities
- Up-prioritize a full rollout of EIP-4444, all the way up to the final end state where each node stores data for only ~36 days. This greatly reduces disk space requirements, which are the primary issue preventing more people from running nodes. After this, the disk space requirements for a node will be (i) state size, (ii) state Merkle branches, (iii) 36 days of history.
- Build a distributed history storage solution, by which each node can store a small percentage of historical data older than the cutoff. Use erasure coding to maximize robustness. This ensures the property that “a blockchain is forever” without depending on centralized providers or putting heavy burdens on node operators
- Adjust gas pricing to make storage more expensive and execution less expensive. A particularly high priority is increasing the gas cost of creating new state: (i) SSTORE for new storage slots, (ii) contract code creation, (iii) sending ETH to accounts that do not yet have a balance or nonce.
Medium-term priority: stateless verification
Once we enable stateless verification, it becomes possible to run an RPC-capable node (ie. one that stores the state) without storing state Merkle branches. This further decreases storage requirements by ~2x.
A new type of node: partially stateless nodes
This is the new idea, and will be key for allowing personal node operation even in a context where the L1 gas limit grows by 10-100x.
We add a node type which verifies blocks statelessly, and verifies the whole chain (either through stateless validation or ZK-EVM) and keeps up-to-date a portion of the state. The node is capable of responding to RPC requests as long as the required data is within that subset of the state; other requests will fail (or have to fallback to an externally-hosted cryptographic solution; whether or not to do this should be the user’s choice).
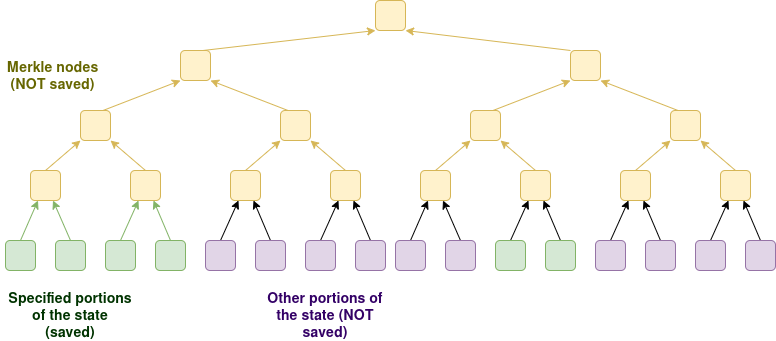
The exact portion of the state to be held will depend on a config chosen by the user. Some examples might be:
- All state except for contracts that are known to be spam
- State associated with all EOAs and SCWs and all commonly used ERC20 and ERC721 tokens and applications
- State associated with all EOAs and SCWs that have been accessed in the last two years, some commonly used ERC20 tokens, plus a limited curated set of swap, defi and privacy applications
The config could be managed by an onchain contract: a user would run their node with --save_state_by_config 0x12345...67890, and the address would specify in some language a list of addresses, storage slots or otherwise filtered regions of the state that the node would save and keep up to date. Note that there is no need for the user to save Merkle branches; they only need to save the raw values.
This type of node would give the benefits of direct local access to the state that a user needs to care about, as well as maximal full privacy of access to that state.