Do you have more details on this? My understanding was that portal was going to provide a network wide state storage system, but it wasn’t going to do anything to try to ensure individual nodes had all of the state they would ever want to reference locally. I thought the design was to ensure state was well distributed over the network with sufficient replication, not optimized for local access needs?
1 Like
When you say “optimized for local access needs”, I assume this means having the data locally, available for reading without having to do higher latency lookups over the network.
Our network design is able to support this use case. Preliminary spec is available here. The rough concept is that we’ll be pushing state diffs into the network at every block. Anyone who wants to keep some slice of the state up-to-date can use the diffs to continually update their local cache/copy.
Maybe a more appropriate statement here would be: The Portal teams are already working on clients that are trying to accomplish a set of goals that look very similar to what is outlined int his post… these are probably the droids you are looking for. It seems we may already be building the solution described in this thread.
I agree that Portal is building a part of the thing described here, and I try to bring up that fact at every opportunity. I don’t think it is the full story though, as for true local-node-priority we need them to be trustless, which means getting state diffs proven with each block and part of consensus.
Do you have any data on the overhead required to participate in the portal network? The 80GB flat-db state for all current state is currently achievable only by dropping the entire MPT datastructure, which I think cuts the disk requirement in half or more, plus makes pruning much easier. If a user stores say 10GB of state (in a flat DB, no MPT) they care about and wants to share access to that with the portal network, how much metadata will they need on disk to achieve that?
These reduced-state nodes would only need to fetch extra data from somewhere when they find they are missing state they need (hopefully a rare occurrence).
But do reduced-state nodes participate in broadcasting of block / tx data so that they would mostly have this data in the first place? If yes, then I’d consider that a significant bandwidth overhead which would certainly prevent the typical wallet to actually run such a service (hence my question on how this is envisioned to be rolled out practically) and thus stand in the way of a maximally decentralized Ethereum. If no, then these massive number of nodes still creates a massive bandwidth and connection overhead for existing full nodes (full in the sense of having all state and broadcasting).
So bottom line I see no way around actually thinking about what @vbuterin wrote above
we eventually would benefit a lot from getting comfortable with paying nodes for services via a standardized (and anonymized) market.
Ah, I see what you are asking about now. I would hope that the light nodes are able to help with some amount of propagation. Perhaps they could propagate headers and state diffs, but not bodies. If we have proven blocks, these nodes also wouldn’t need the bodies (just headers and state diffs), so in theory they would contribute about as much as they consumed.
Of course, how this all works out in the end definitely is dependent on what technology we actually manage to develop (realistic block proving is still a long way off). In general, I am also not terribly against an anonymized data market, especially if we can utilize payment channels so if it costs $0.00001 per block or something (which I would imagine would cover the bandwidth costs?), then users could pay $2/month to stay synced. Maybe less depending on what the costs actually end up being and how competitive the market is.
1 Like
I think this would work well with in-protocol block witnesses or state diffs.
Portal becomes the backbone for bootstrapping new nodes or nodes that have been offline for a period. Full availability of any portion of the state that a node wants to pull into their local copy.
Keeping this data up-to-date can be done with witness based block execution or just by applying the portion of the state diff that applies to their local state.
And contributing back to Portal doesn’t need to be a function of the size of the local state data held by the node. A node could have 80GB of state data that it keeps locally and only choose to offer 1GB of storage back to portal. This is the part about Portal that is maybe conceptually important. Nodes don’t get to choose what data they store for the network. This is fundamental in the design of the network to ensure that data is evenly replicated and that even unpopular data remains available. Any design that is based on nodes choosing what data they store and offer the network is going to have trouble making the unpopular data readily available on the network. So the 1GB of storage offered to Portal in this example would likely be mostly disparate data from other 80GB.
Is there any deduplication that can occur here? If all state is 100GB and the user is storing 50GB for their own use, and their randomly assigned slice of state is 10GB, then ~5GB of their randomly assigned state is state that they have chosen to keep local for personal reasons. Will the user need to store ~60GB or ~55GB in this scenario?
1 Like
Yes, this data can be de duplicated if the client developers choose to do so in their implementation.
1 Like
tl;dr In addition (AND not OR) to solving the full node problem, I wanted to shed light on GATE: Gateway Abstraction Technical Elements. I did a full presentation on it at the 1kx summit
It’s valuable to have a full node so that you can have a local RPC server that you can use to read the chain in a trustless, censorship-resistant and privacy-friendly way.**
This is theoretically true.
Practically (unfortunately?) I do not believe RPC is going away.
This extends beyond Ethereum nodes to any open canonical dataset/service; Tor relayers, OpenStreeMapsData, LLMs, etc…
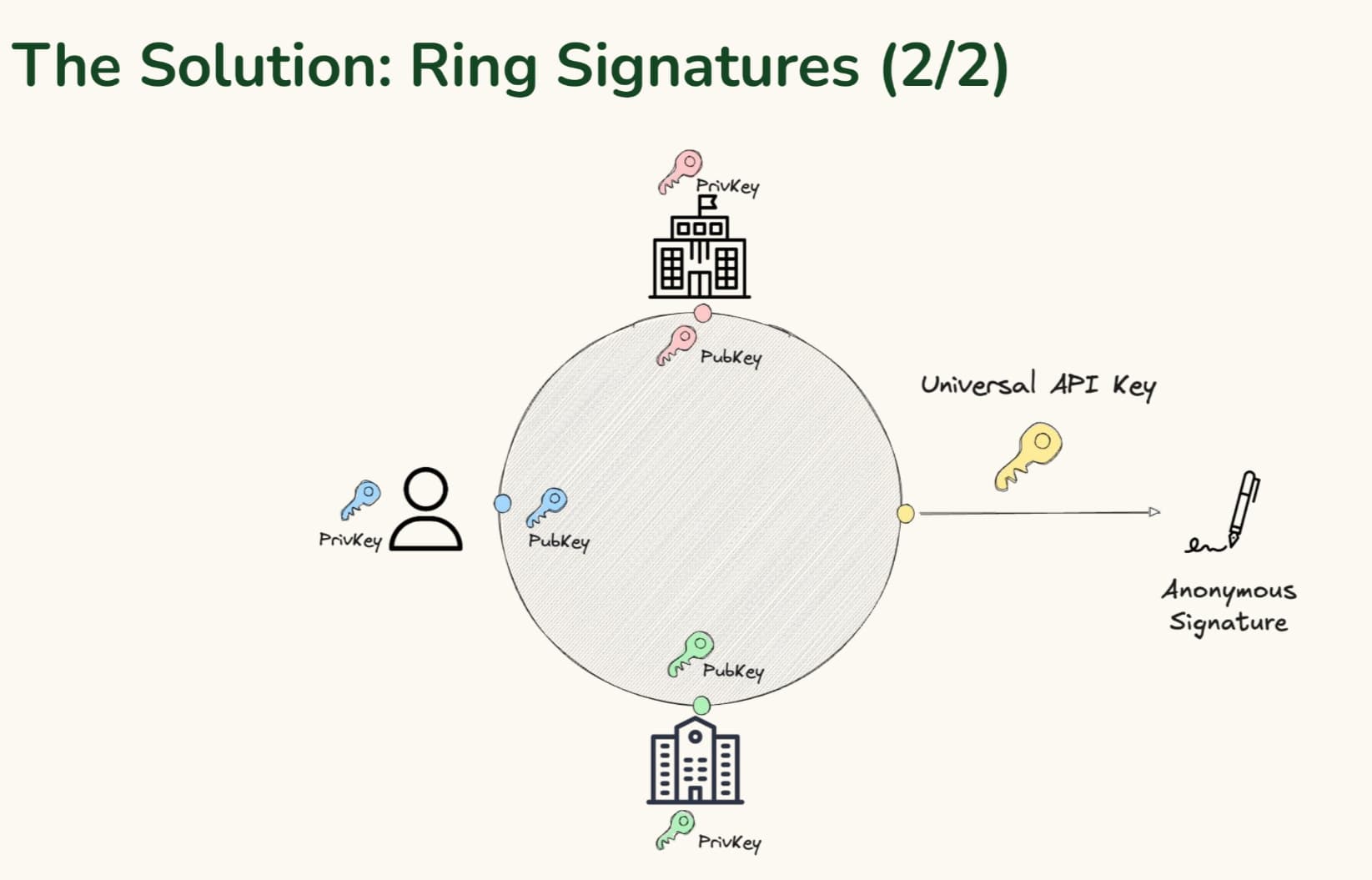
If I get a few ![]() here, I’m happy to share a thread of how we’re thinking about it. I want to avoid highjacking this thread and avoid any biases that relate to our project/company.
here, I’m happy to share a thread of how we’re thinking about it. I want to avoid highjacking this thread and avoid any biases that relate to our project/company.
The high level technical approach is:
-
Permissionless directory of endpoints
-
Verifiable API counter (probabilistic)
-
Optimistic rate limiter (with crypto-economic incentives)
-
Smart Quality-of-Service SDK
-
Delegated trust
-
Borrows ideas from Grant Negotiation & Authorization Protocol; an IETF standard;
1 Like
Well - this is a classic example of solving a problem that users don’t actually ask to solve.
Ethereum today is a somewhat-decentralized network, with a Nakamoto coefficient of around 3.
Most users are perfectly fine with this level of decentralization. In fact, they dont care about rollups being 100% centralized.
What Vitalik is missing in his line of thought, is why suddenly decentralization is important in the particular case that he is considering and totally unimportant in other cases.
“Most users” are perfectly fine with a 100% centralized censorious financial system, as long as they are not the ones being censored. IMO, Ethereum should be filling the currently unfulfilled niche of censorship resistant finance, not trying to compete with censorable systems.
What cases do you think should take priority over ensuring that users can operate the software in a sovereign way?
Product of Ethereum is not settling with some abstract block builders. It’s infrastructure service that allows to settle deals between entities or groups of such, where settlement between two end-users is a distinct use case.
All I’m saying is that while decentralised storage solution and stateless verifications are great, from what I can see today - it seems premature.
While it is it’s valuable to have a full node so that you can have a local RPC server that you can use to read the chain in a trustless, censorship-resistant and privacy-friendly way, the proposed roadmap will not solve problems of end-users not able to run p2p nodes due to fact that most end-users are behind CGNATs.
This fact implies that it still would require local users to set up a server, call their provider and arrange CGNATs configuration.
Hence, in anyway the “localism” adaption and degree of possible decentralisation achieved will be limited by the last mile carrier internet providers.
This brings to question whether such participants, operating telecom equipment and often a server rack or two, are concerned by (What are estimated HW requirements?)
Or do they have another concerns why they refuse today to run (at scale) Ethereum infrastructure on their premises?
In my humble view, Ethereum needs more research thinking in telecommunication network level and close intermediate gaps by getting incentives right for internet operators (local node ROI, EIPs to advertise RPC serving capacity/endpoints) , that will create incremental local-node favoring delta by moving out cloud resourced on to the edges AND will produce demand for decentralised storage and partial state etc etc.
How would reduced state nodes know that some piece of cached state they have is stale?
As you mention, in a post-statelessness world they could of course check the block’s witness, but it is very possible that the witness is quite large (especially if the proposals to scale mainnet by many orders of magnitude come to fruition).
You could try asking a node “please give my state that has changed since last block,” but you have no guarantee that the list is exhaustive and you leak what state you are interested in to third parties.
You could download all of the state you care about each block, but this is quite wasteful and still leaks what set you are interested in.
One idea here is we could add some probabilistic data structure like a bloom filter to the block that can help nodes check what accounts and slots have changed in that bock. If we can keep false positives low enough (hopefully by learning from the mistakes of the existing logs bloom), we can download close to the minimal amount of data per block, and ensure exhaustiveness.
This proposal doesn’t fully solve the privacy concern (although it does reduce the amount of data leakage since you only leak information when state has changed), but if you download your updates via PIR/TEE+ORAM we can temper those concerns. It’s main benefit is that it is probably simpler and more scalable to add to Ethereum today than full bock witnesses.
Another idea that does not require any in protocol changes, but hurts the privacy element is to register with n providers what state you care about. These providers can be queried to get the set of state that has changed. We then implement a sort of dispute game. We ask the providers to prepare an ordered list of updated state and merkleize this data structure. If they all agree on the root, we can fetch the full list from one node and if it matches the root, accept it as valid. If there is a disagreement, we can bisect the tree until finding the point of disagreement. At that point, we fetch a merkle proof of this state, and confirm whether it is valid and whether it has changed in a given block. This allows us to identify every dishonest node in the set, and come to agreement on what the correct set is (assuming existential honesty).
Are there any other techniques I am missing? If we can get a way to do this we would certainly implement it in Helios.
They would download deltas (the block-level access list proposals basically include this already)
We could require deltas to be sorted, which would allow nodes to download only the portion of deltas relevant to the portion of state they are keeping - though this leaks more data.
1 Like
Well, Micah, then Vitalik or someone else that has a power at EF needs to state this as the goal of Ethereum Foundation.
Currently the statements EF are making absolutely the opposite. Add to this the ghosting policies they have. They never answer questions they do not like.
Rollups a censoring and centralized. Not a single person from Ethereum Foundation ever explained how decentralize them, and they do not want to. They want to have another meaningless token from the likes of Optimism.
It is a fake morale build from the top down, I understand the powerlessness of people at the bottom.
You would agree with me that it is meaningless to have conversation, when the other party has a profit-maximizing strategy.
The pyramid built by the Ethereum Foundation has nothing to do with science and nothing to do with opensource. It has nothing with DAOs. And it has absolutely nothing with the spirit of opensource.
It is a very typical Russian organization where people at a particular Layer warship people at the layer above and get war shipped by the people at the layer below…