Yep, that makes sense. Though, even if it reduces to being just a hash function, I think using MiMC has some advantages. The biggest drawback is probably potential attacks against MiMC that we don’t need to worry about with true and tested hash functions.
There is another potential optimization I thought of which, if works, can reduce proof size by about 15%. The optimization tries to take advantage of some redundancies in the FRI proof structure.
In your example, each layer of a FRI proof contains two sets of Merkle paths (code):
- Merkle paths for indexes in the “column” (tree
m2 in the example);
- Merkle paths for indexes in the “polynomials” (tree
m in the example).
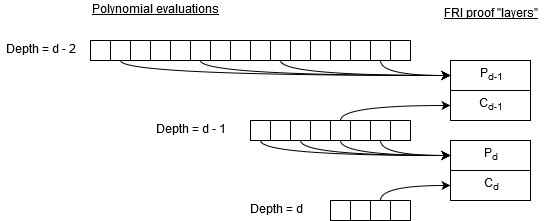
In subsequent layers, m2 becomes m, and a new m2 is created from m by splitting it into sets of quartic polynimials and evaluating them at a random point x. I tried to illustrate this in the graphic below:
In this picture, P are the “polynomial” Merkle paths, and C are the “column” Merkle paths. For each path in C, there are 4 paths in P (in the example, number of paths in C is 40, and, thus, number of paths in P is 160).
It is easy to see that P_d and C_{d-1} paths come from the same tree. If we can make it so that C_{d-1} is a subset of P_d without compromising security, we can reduce FRI proof size by up to 20%. Here is how I think it could work:
Instead of deriving pseudo-random indexes from roots of m2 at every layer (code), we can do the following:
- Derive pseudo-random indexes from the root of
m2 at the last layer (i.e. depth d). These indexes will determine paths for C_d (40 indexes).
- Use these indexes to determine indexes for P_d (160 indexes). This is done in the same way as now (code).
- Use root of
m2 at the next layer up to randomly sample indexes for C_{d-1} from P_d (basically, choose 40 random indexes out of the set of 160 indexes).
- Same as in step 2, use indexes for C_{d-1} to determine indexes for P_{d-1}.
- Move to the next layer up and repeat steps 3 and 4.
Here is an illustration of how indexes for each set of paths could be derived:

Basically, we recurse all the way down, and then use the root of the Merkle tree at the bottom layer to derive all other indexes as we move back up in the recursion.
It doesn’t seem like an attacker gains any advantages in this setup. They still need to build all the same Merkle trees on the way down in the recursion, and the indexes for each proof layer are still selected pseudo-randomly based on the roots of all treesn
If you (or anyone else), sees any flaws in this approach, let me know.