I’ve been mulling this for a while, but was prompted to write-up by @vbuterin’s tweet on gauging support for protocol changes.
Background
Crowdsourced methods such as “Likes” on Twitter and ‘Upvotes’ on Reddit have become a fundamental tool for curating content and by extension, ideas. Crowdsourced curation is superior to relying on a handful of specified curators in that it:
- smooths out individual biases
- is able to curate a higher volume of content, because content consumers are also able to provide curatorial input
However, existing methods do not reward consumer-curators for their efforts, and so there is little incentive to search through generally lower-quality uncurated content, to find as-of-yet unidentified high quality content. As a consequence, the overwhelming majority of people take a path of least resistance, and consume-curate content that has already been curated to some extent by others, for example by following already-popular Twitter handles. This leads to a reversion back to curation being dictated by a handful of individuals, and as a consequence a lot of high quality content remains undiscovered.
More fundamentally, it results in feedback loops wherein populist or inflammatory content is amplified, and more controversial or balanced content is suppressed. This increases groupthink and makes online information aggregation tools less effective for reasoned discourses and comparison of alternative ideas.
A solution may be to leverage the Efficient Market Hypothesis for content curation, wherein curators are incentivised to identify undervalued content. In such a market-based mechanism, instead of simply ‘Liking’ content, curators purchase tokens that signify support of that content. These tokens are issued at an algorithmically determined price using a bonding curve model; the more tokens in circulation, the higher their purchase price is.
This means curators who are able to identify good quality content early are able to purchase tokens at a lower price. Such curators are then able to subsequently sell their tokens at the current market price, thereby making a profit from their insight, and equally driving the price back down. As such, the price of the ‘support’ token, fluctuating according to demand, becomes a measure of how popular a piece of content is. Critically, there is no concrete payout for holding a support token - all potential profit is in speculation around a Schelling Point.
Inversely Coupled Bonding Surfaces to prevent Price Manipulation
On its own, the price of a support token can be manipulated by a content creator to artificially make their content appear more popular than it is. By purchasing a large number of tokens as soon as a market is created, a creator can increase the token price from P_0 to P_1. As the creator was the first participant in the market, the token price can not drop below P_1 without the creator selling their tokens. This means the creator, having artificially inflated the price for a desired period, can sell their tokens at any point and recoup all of their initial investment.
In order to prevent this phenomenon, a secondary token that signifies opposition to the content is also available to purchase. The price of the support and opposition tokens are algorithmically linked, such that purchasing opposition tokens drives the price of support tokens down and vice-versa.
This means that the initial listing price of the ‘support’ token is no longer its lowest possible price, making it impossible to inflate its price without any risk. The secondary token has the advantage of allowing a direct comparison of the support versus opposition to a particular idea or policy.
Bonding Surface Construction
Together the two tokens form a bonding surface, which is used to define their price behaviour. To construct this Bonding Surface, we will use a Cost Function C(s_1,s_2) , which states that the total amount of funds paid to the contract in exchange for tokens T_1 and T_2 is a function of only their current supplies s_1 and s_2.Thus the cost to purchase \Delta s_1 of T_1 and \Delta s_2 of T_2 is
The Cost Function that defines our inversely couple bonding surface is then given by:
Here F_i is analogous to the Reserve Ratio for each token, and determines the rate at which token price grows with respect to supply, and \beta is the coupling coefficient between the two tokens. Token prices are negatively correlated when 0<\beta<1, independent when \beta=1, and positively correlated when \beta>1.
To further understand the behaviour of the Cost Function, let us choose sensible parameter values, such as \beta=\frac{1}{2} and F_1=F_2=3. Then:
The price of a token is given by the partial derivative of its supply with respect to C, so for T_1:
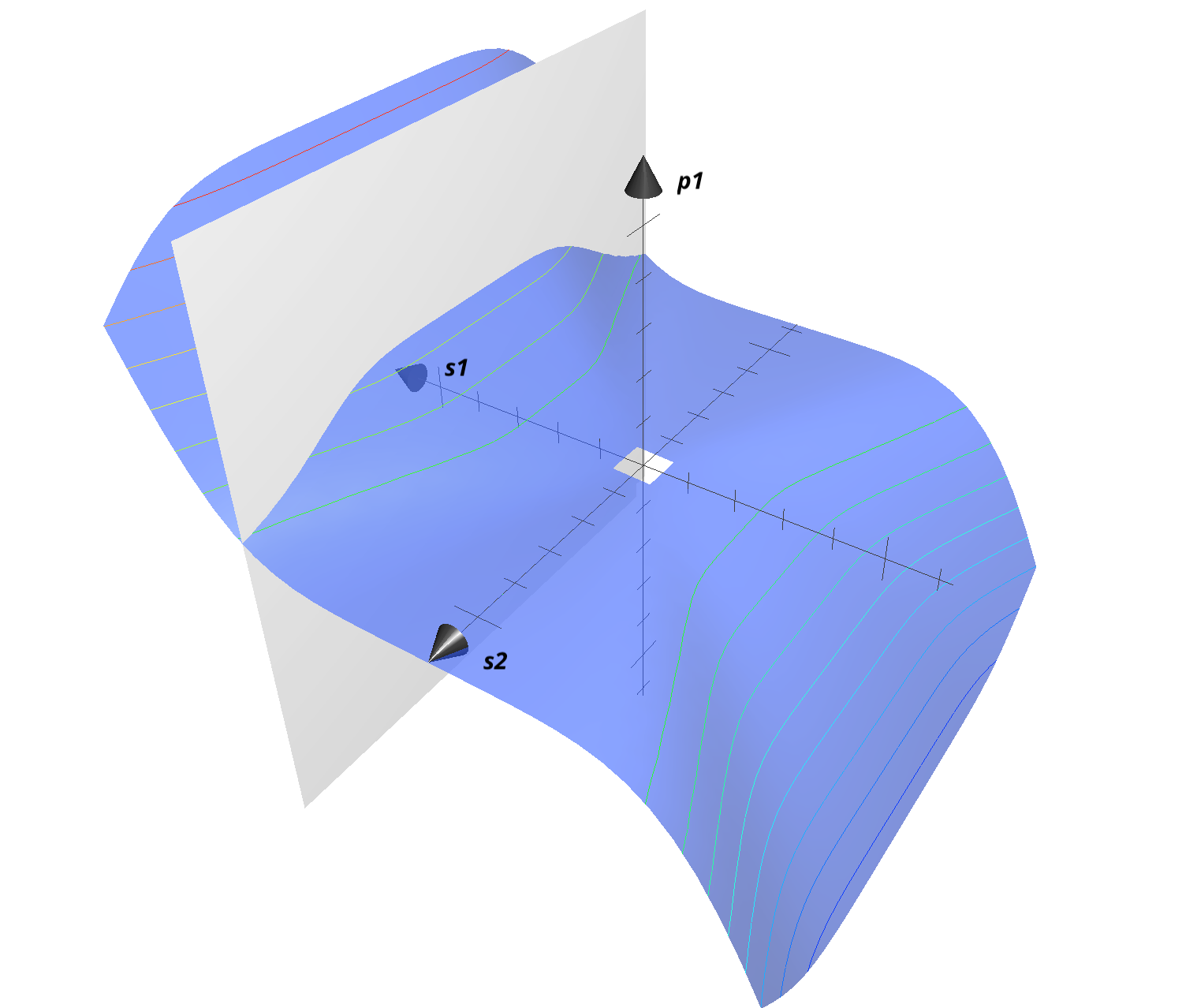
We can now see that p_1 monotonically increases with respect to s_1, approaching p_1=3s_1^2 for s_1>>s_2. More critically, we can see that p_1 monotonically decreases with respect to s_2. Given the Cost Function is symmetric, the same logic applies to p_1.
That is, as more of T_1 is issued, its price increases, and the price of T_2 decreases.
Here’s a plot of p_1 for visualisation purposes. I’ve inserted a plane at s_1=0.2 to make it easier to see the price drop with respect to p_2.
While we are most interested in Coupled Bonding Curves with Two assets, the concept generalises to any number of assets (here we’ve included an extra weighting term):
Here’s a link to a google sheet if you’re interested in playing around with some numbers
Possible Issues
Plutocracy
Like all curation methods that involve commitment of funds, those with more capital available have some capacity to exert more influence. I believe the market-mechanism addresses this to some extent, as depositing a large amount of funds to move a token to a vastly different price risks having another set of traders come in and move the price back, at your expense; the Efficient Market Hypothesis in action. However, this resilience is predicated on the market having sufficient depth and diversity of traders.
Schelling Point Corruption
For the curation process to be effective, the Market needs to have a strong Schelling Point tying token prices to the perceived quality of the associated quality.
it’s very common for Schelling Points to end up effectively measuring hype around an idea rather than the idea’s actual quality (see most of the ICO market). However I’m uncertain of the extent to which a Schelling Point that reflects hype rather than quality per-se would actually be problematic, as I suspect there’s a strong correlation between hype and quality in many cases, especially when the market is natively short-able. Of course, Schelling Points can shift entirely to market-endogenous speculation, as seen with Hertz’s recent stock price, though the Hertz case appears to have been caused by dark-pool trading and a lack of primary market liquidity, which is not a concern with a bonding curve.
Possible applications
I think there are two immediately obvious applications for such a curatorial mechanism:
-
An alternative to Reddit/Twitter where users are incentivised to identify compelling content from normally overlooked sources.
-
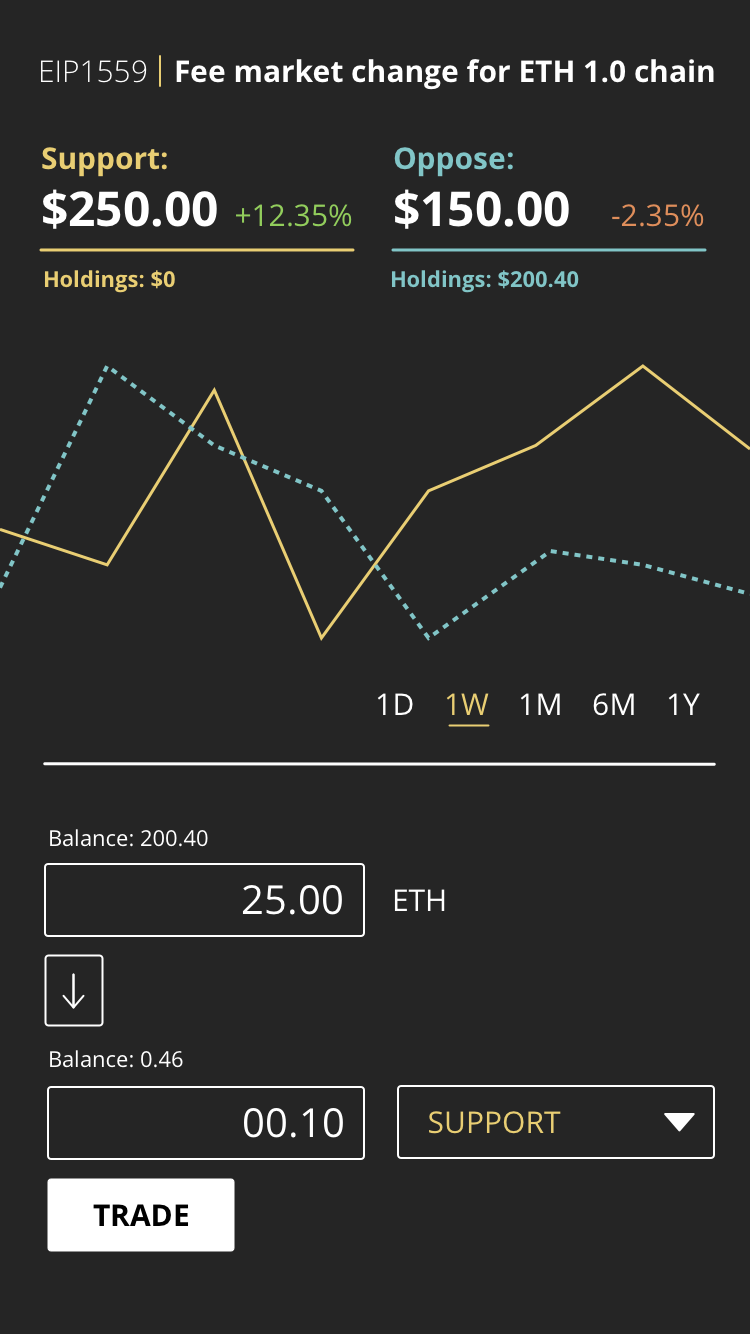
A simple Dapp where people can register their support or opposition to various EIPs. I think this one could be particularly interesting as it wouldn’t be very difficult to build a prototype. I put together a small mockup to get an idea of what it could look like:
That’s all for now. Keen to hear your thoughts.