By me, @rishotics and team
Special thanks to Rand Hindi and the Zama team for their feedback and suggestions
Introduction
Blockchain and DeFi systems promote transparency and decentralization but expose user transaction data to the public. This visibility poses significant privacy risks, deterring privacy-conscious users and opening the door to security threats like front-running attacks.
Privacy is a fundamental pillar of the open-source ecosystem, yet it is often overlooked in DApps. This article explains one of our approach to seamlessly integrate privacy into existing applications rather than creating isolated, fragmented ecosystems where privacy is treated as an afterthought. With billions of USD locked in ecosystems like Ethereum, Solana, and Bitcoin, privacy solutions are not even a part of their near-term roadmap. This leaves users with no choice but to engage with these systems without privacy, exposing sensitive financial data.
Several privacy solutions, including shielded pools, hardware solutions, and threshold encryption, have been attempted to tackle these issues but face significant limitations. Shielded pools, while effective at concealing transaction details, create barriers to adoption due to complex user interfaces and regulatory challenges. Threshold encryption solutions suffer from complex key management and scalability issues in decentralized environments. Consequently, these solutions often sacrifice usability and compliance, limiting their effectiveness in real-world applications.
Privacy-enhancing technologies like FHE, TEE, and MPC offer a novel approach by enabling computations on encrypted data without decryption. Thus, they preserve privacy while addressing the scalability and regulatory challenges that have limited previous solutions. The issue is how to use these PETs with existing EVM stacks or Dapps[2].
To make privacy accessible to all users, we need to focus on two key areas:
- Adapting existing application: to be compatible with privacy-enhancing technologies
- If building new application: within existing ecosystems using privacy-preserving technologies
Very few efforts have been made to introduce privacy in existing applications. Our approach tries to tackle the above challenges and provides a generalised way of interacting with current applications.
In this post, we will explore how to incorporate privacy into existing Defi applications on EVM-compatible chains using PETs like FHE. The overall architecture combines off-chain co-processors with on-chain smart contracts. For these off-chain co-processors to interact effectively with on-chain states, we need a framework that enables smart contracts to work seamlessly with encrypted data.
We also discuss the concept of encrypted ERC20 tokens, which provide a privacy-enhanced alternative to standard ERC20 tokens. As, Recently, Circle and Inco published a report delving deeper into the topic of encrypted ERC20s. To be precise, Our framework is not tied to any specific encrypted ERC20 standard, making it adaptable for use across multiple standards.
Background and Related Work
Current Transaction Flow
The current transaction process—from a user’s wallet → mempool → block is entirely transparent. This transparency aligns with the core purpose of a public blockchain, where data included in the ledger should be visible to all participants. However, this openness deters many people from entering the space, as not everyone wants their data to be visible to the entire world.
There are various stages in the execution process where privacy can be introduced, and each stage comes with its own set of complexities. Encrypting the transaction as soon as the wallet signs it makes the most sense, as valuable information can then be hidden on the client side.
The challenge lies in modifying the existing infrastructure and achieving community acceptance for these changes. Solutions include encrypted mempools, encrypted solving, private RPC providers, and block building within TEEs, among others. Let’s explore some of the solutions that other teams have worked on in the past.
Some Previous Privacy Solutions
Encrypted Mempools
Teams are already working on encrypted mempool solutions. Threshold-encrypted mempools use threshold encryption to protect transaction details in the mempool until they are ready to be included in a block. This prevents unauthorized parties from viewing transaction details (e.g., sender, receiver, or amount) while the transaction is still pending, addressing issues like front-running in MEV situations. Users can submit transactions with the assurance that their details will remain confidential until the block is confirmed.
However, encrypted mempools has high barrier to entry due to it’s unique cryptographic (Time lock puzzle, Threshold encryption / decryption) or hardware requirements (TEEs).
Most threshold encryption schemes require an initial setup phase that involves distributed key generation, which can be costly in terms of time and resources. In large, decentralized environments, this setup can be challenging—especially when committee members join or leave, requiring key re-shares or even a complete rerun of the setup.
Shielding Pools
Current solutions that provide protection for on-chain interactions often lack user-friendliness from a UX standpoint.
Using shielded addresses and pools introduces significant complexity to achieving on-chain privacy. Shielded pools enable users to store and transact assets without revealing transaction details—such as the sender, receiver, or amount—on the blockchain. Zero-knowledge (ZK) proofs facilitate these shielded transactions by validating their legitimacy without disclosing any actual data. This ensures that network participants can verify the validity of a transaction without knowing who sent or received the funds or the amount transferred.
When a user transfers assets into a shielded pool, those assets are “shielded,” with transaction details (amount, sender, receiver) encrypted and hidden from the public ledger. ZK proofs are then used to confirm that the user holds a valid balance and is authorized to spend it, without revealing any specifics. Users can transfer assets between shielded addresses without exposing details within the shielded pool. All transactions remain hidden, with ZK proofs ensuring compliance with transaction rules, such as maintaining balance integrity and confirming valid ownership. If a user chooses to move assets back to a transparent (non-shielded) address, they can withdraw funds. However, this typically results in a “privacy break,” as the withdrawal amount becomes visible unless transferred to another shielded pool.
Without proper checks, shielded pools also raise compliance and regulatory concerns, leaving users uncertain. These pools obscure transaction details, complicating the tracing of funds and the identification of involved parties. Regulators are concerned that shielded pools could facilitate money laundering by concealing illicit funds. Financial institutions and regulated entities must comply with anti-money laundering (AML) regulations, which require the detection and reporting of suspicious activities. Shielded pools limit transaction visibility, making it challenging to verify the origin of funds and adhere to AML standards.
Some Preliminaries
Differential Privacy
Differential privacy is a mathematical framework used to quantify and ensure the privacy of individuals within a dataset [1].
The core idea of differential privacy is to ensure that it is difficult to determine whether any specific individual’s data is included in a dataset, even when analyzing the output of an algorithm applied to that dataset. A randomized algorithm is said to satisfy (ϵ,δ) - differential privacy if the inclusion or exclusion of an individual’s data changes the probability of any specific output only slightly.
In the context of differential privacy, ϵ controls the privacy loss, quantifying the maximum difference in output probabilities for neighboring datasets (datasets differing by only one individual). δ represents the probability of a small relaxation in the privacy guarantee, allowing for a slight chance of greater privacy compromise. This framework ensures that the algorithm’s output remains nearly indistinguishable for neighboring datasets, thereby limiting the information leakage about any single data point.
Differential privacy has become a widely adopted standard for privacy-preserving data analysis, offering robust privacy guarantees while enabling valuable statistical insights.
Torus-based Fully Homomorphic Encryption
TFHE is a FHE scheme optimised explicitly for fast binary gate computations. Unlike traditional FHE methods that rely on more complex lattice structures, TFHE operates over the torus, efficiently performing encrypted computations with lower noise accumulation and faster bootstrapping times.
As a result, TFHE has emerged as a promising solution for secure, privacy-preserving computation in real-time applications.
Solution
Encrypted ERC20 Tokens
Encrypted ERC20 standard for privatizing user token balances. Any token balance intended for homomorphic computation on-chain would need to be wrapped within this encrypted ERC20 standard. This approach can serve as a foundation for building various privacy-focused solutions, such as private payments, private auctions, dark pools, and more.
This standard implements necessary interfaces which is used to implement necessary compliance checks, which include selective disclosure of specific ciphertext requested and a few other checks.
To learn more about Encrypted ERC20 you can read this article by Circle [3]
Differential Privacy with Order Aggregation and Batch Settlements
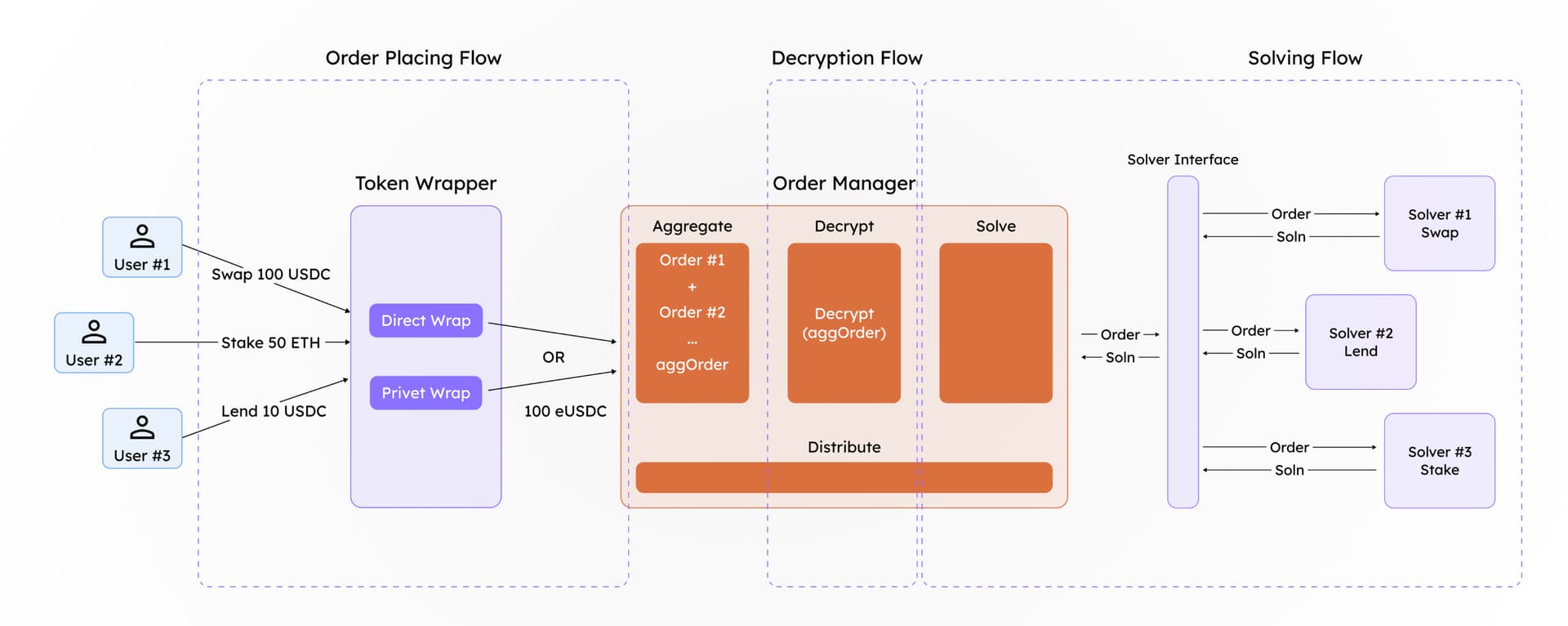
We propose a solution leveraging differential privacy to enable order-solving for encrypted orders. This allows users to place encrypted orders (orders with encrypted tokens) and have them processed on-chain without revealing their details. External parties cannot determine the exact order details associated with a specific user.
Batching is a core component of this solution. The challenge with processing a single encrypted order directly through the protocol is that once decrypted, the amount the user intended to hide becomes visible. To mitigate this, we aggregate multiple orders using the additive homomorphic properties of certain privacy-enhancing technologies (PETs), such as Fully Homomorphic Encryption (FHE). The encrypted amounts are summed and deposited as an aggregated value with a designated manager. The manager’s role is to decrypt this aggregated value via a secure wrapper (obtaining the decrypted tokens amountIn values) so that the resulting assets can interact with the appropriate solver protocol.
By batching encrypted orders, we introduce a level of noise into each order, effectively preserving the privacy of individual users’ order details.

The design is inspired by Zswap DEX of Penumbra [5], which uses sealed-bid batch swaps. The price at which these orders are settled is identical, as there is only one transaction per epoch.
Once the order is solved, the return token amount belonging to the user is calculated homomorphically using the ratio of the input amount to the output amount (the amount received upon solving the order). This calculation is performed homomorphically in the encrypted space, ensuring that no one can fully determine how many tokens a particular user will receive, thereby preserving privacy.

End to End flow Order placing → Order Aggregation → Order Solving → Distribution
Mathematical Formulation
We are proposing two methods for mitigation for the privacy in applications:
- Encrypting Assets: Assets held by the user is encrypted via publicly verifiable encryption scheme.
- Batching Orders: Choosing a size of n of orders to batch prior execution.
Individually these solutions don’t provide enough privacy guarantees from an adversary POV but together it introduced differential privacy which provides probabilistic indistinguishability for a particular user’s order.
Most DeFi action on-chain can be defined as a Tokens going in ( T_{in} ) and tokens coming out ( T_{o} ), which means that any solving action \pi can be written as
By changing the domain of interaction for the user with the protocol with we can introduce a middle smart contract M which does this interaction on the users behalf. Now M has the task of receiving orders from n users and aggregating them i \in [1,n]
We can write the encrypted value of T_{in} for a user i as C^{i} where C^{i} can be represented as
The above representation is how a lattice based homomorphically encrypted plaintext looks like.
Now since encryption is homomorphic in nature we can simply sum the individual ciphertexts to form the aggregate ciphertext C^{\pi_M}
In this process we need to perform programmable bootstrapping multiple times which reduces the noise which is getting accumulated in every addition.
The decrypted amount is now used further for interaction with the DeFi protocol.
Conclusion
Privacy in blockchain and DeFi ecosystems is becoming increasingly crucial to protect user data and secure transaction processes. While various solutions—such as shielded pools, threshold encryption, differential privacy, and fully homomorphic encryption—offer unique approaches, they also present challenges in terms of usability, compliance, and technical implementation.
Exploring these privacy-preserving techniques highlights the potential for integrating privacy into existing blockchain applications while balancing transparency and regulatory requirements. As privacy solutions continue to evolve, they promise to foster a more inclusive, secure, and user-centric blockchain ecosystem, empowering users to engage confidently in decentralized platforms.
References
[1] Differential Privacy in Constant Function Market Makers by Tarun Chitra and Guillermo Angeris and Alex Evans
[2] Zama’s fhEVM co-processor
[3] Unveiling the Confidential ERC-20 Framework: Compliant Privacy on Public Blockchains using FHE
[4] TFHE: Fast Fully Homomorphic Encryption over the Torus by Ilaria Chillotti and Nicolas Gama and Mariya Georgieva and Malika Izabachène
[5] ZSwap Penumbra