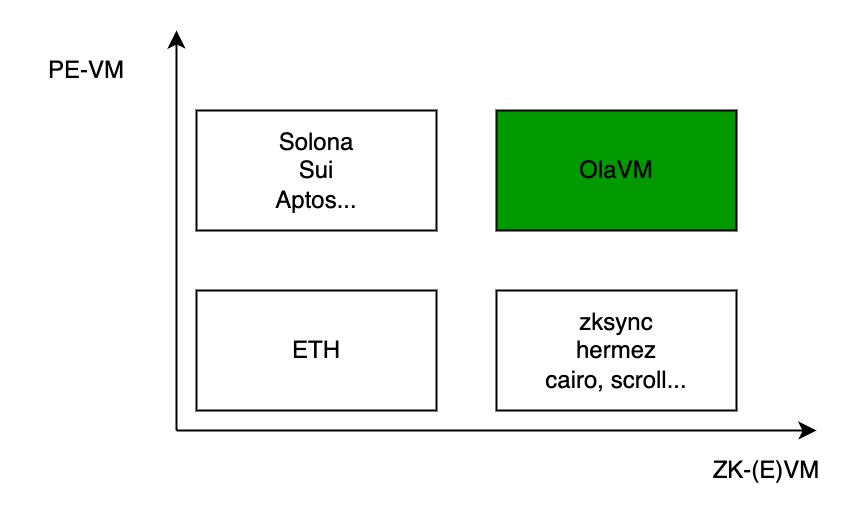
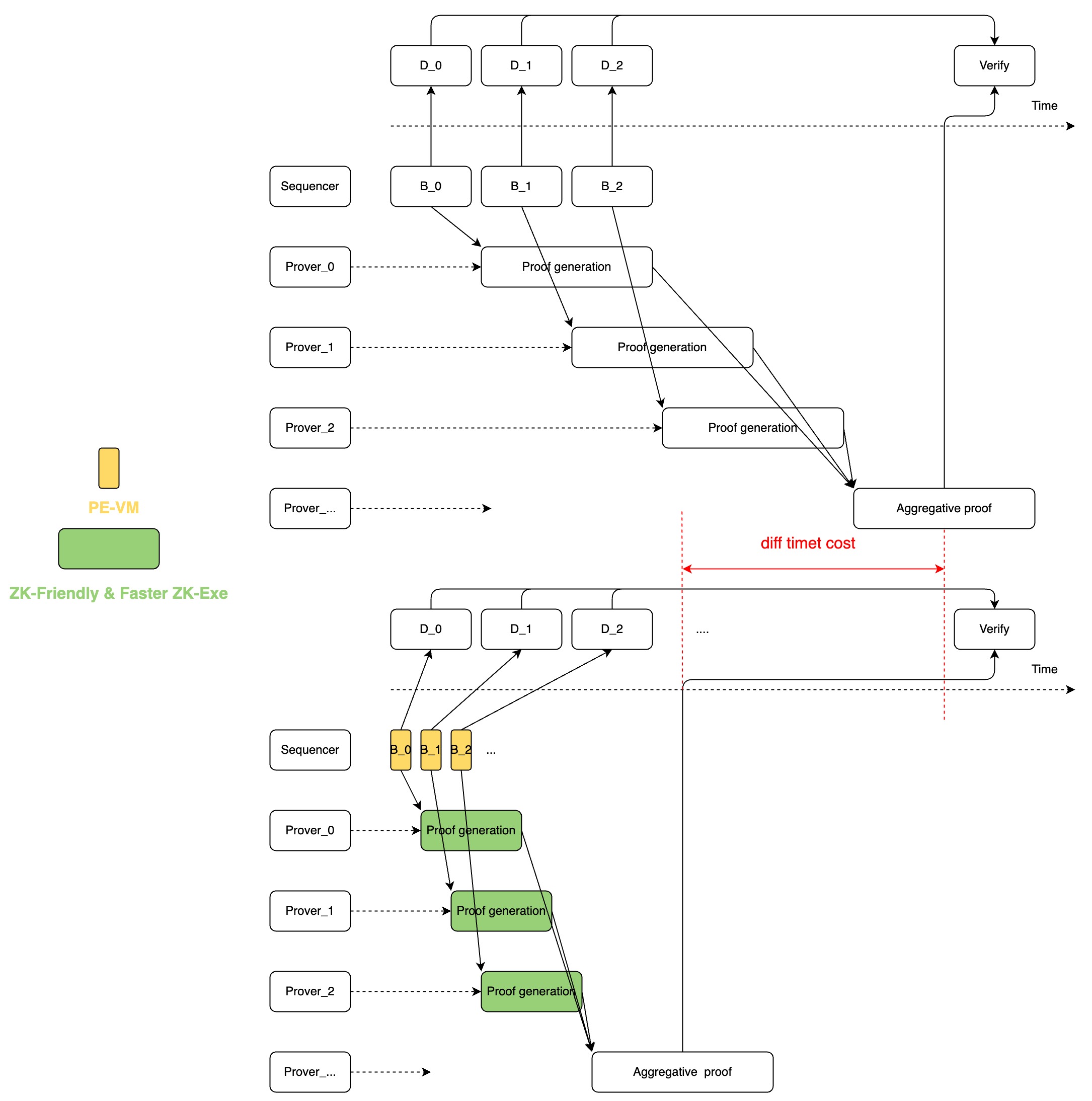
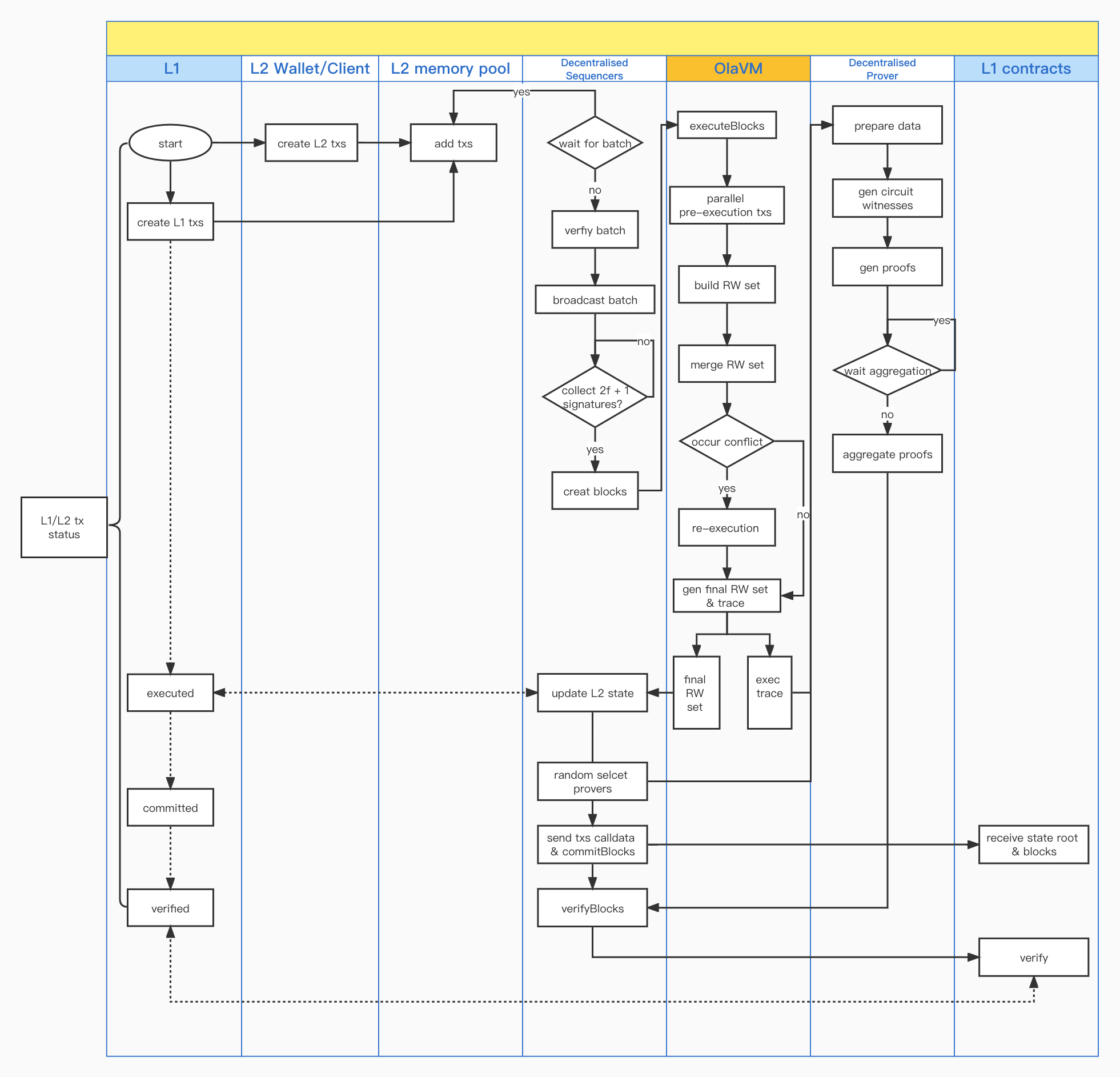
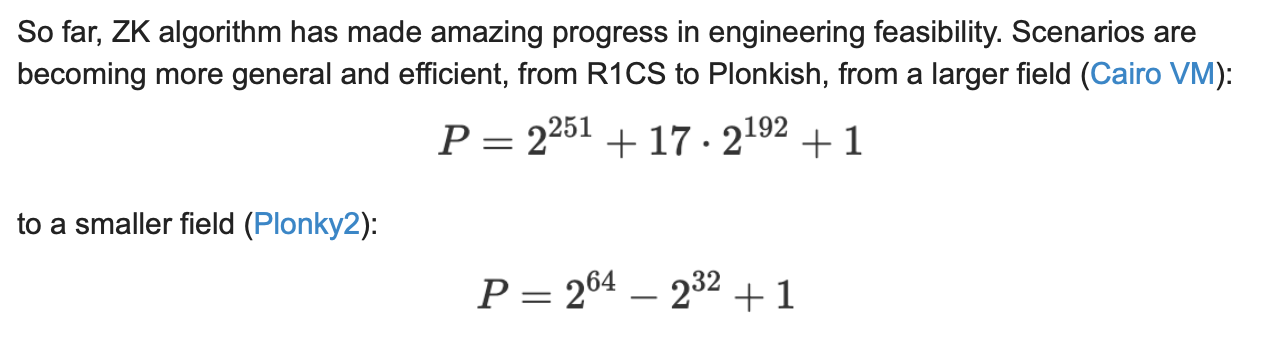How do you improve the systems throughput?
Increasing the speed of proof generation is the single most important aspect to increasing the overall throughput of the system, and there are two means to accelerate proof generation, keeping your circuit scale to a minimum and using the most efficient ZK algorithm. You further breakdown the meaning of an efficient algorithm, as this can be divided into improving the tuning of parameters such as selection of a smaller field, and secondly, the improvement of the external execution environment, utilizing specific hardware to optimize and scale the solution.
- Keeping your circuit scale to a minimum
As described above, the cost of proof generation is strongly related to the overall size of the constraint n, hence, if you are able to greatly reduce the size of the constraint, your generation time will be significantly reduced as well. This is achievable by utilizing different design schemes in a clever way to keep your circuit as small as possible.
- We’re introducing a module we’ll be referring to as “Prophet”
There’s many different definitions of a prophet, but we’ve focused on “Predict” and then “Verifiy”, the main purpose of this module is to, given some complex calculation, we don’t have to use the instruction set of the VM to compute these calculations. Why this is, is because it may consume a lot of instructions, thus increasing the execution trajectory of VM and the final constraint scale. Instead, this is where the Prophet module would come into play, it is a built-in module that performs the calculation for us, sends the results to the VM, which will perform a legitimacy check, and verify the result. The Prophet is a set of built-in functions with specific computing functions, such as division, square root, cube root, etc. We will gradually enrich the Prophets library based on actual scenarios to maximize the overall constraint reduction effect for most complex computing scenarios.
Dealing with complex calculations the Prophet module can help us reduce the overall size of the virtual machines execution trace, however, it would be convenient and preferred if the actual calculations themselves are ZK-friendly. Therefore, in our architecture we’ve opted for designing the solution around ZK-friendly operations(Choice of hash algorithms and so on), some of these optimizations are present in other ZK(E)VMs as well. In addition to the computing logic that the VM itself performs, there are other operations that also need to be proven, such as RAM operations. Given a stack-based VM, POP and PUSH operations have to be executed at every access. At the verification level, it is still necessary to verify the validity of these operations, they will form independent tables, to then use constraints to verify the validity of these stack operations. Register-based VMs on the other hand, executing the exact same logic, would result in a smaller execution trajectory and therefore a smaller constraint scale.