Capacity oracles
by maryam and mike; april 23, 2026.
tl;dr; An emerging pattern in blockchain protocol design is delegation-verification, where a set of specialized nodes performs a computationally intensive task and a much larger set of parties verifies the output. This pattern exploits the cost asymmetry between doing work and verifying that it was done correctly. ZK proofs are the obvious example of this, but other, more general workloads fit into this paradigm. For example, a TEE running AI inference can be verified by validating the attestation generated by the hardware. These systems face an information elicitation problem. Potential users may want to know that there is sufficient additional capacity for their workloads, but they don’t have visibility into the available throughput of the workers. In particular, the only signal of the capacity of the nodes on a chain would be the ex-post view of the workloads that were executed, which doesn’t say anything about how much additional work could’ve been handled. This post presents a simple model capturing this problem.
Contents
(1) Intro
\quad(1.1) Understanding network capacity
(2) Model
\quad(2.1) Comments on the model
\quad(2.2) Naïve solution in a non-sybil environment
(3) Sybils
\quad(3.1) Approach 1: Correlating the payments
\quad(3.2) Approach 2: Adding staking and slashing
(4) Sybils, slashing, and the price of truth
\quad(4.1) Linear rewards are still vulnerable
\quad(4.2) Convex rewards
(5) Summary
1. Intro
A common proposed design pattern for the next generation of blockchain protocols replaces the original version of the replicated state machine, where every node replays the history of state updates, with a “replicated verifier” model. Under this model, tasks are executed once and verified many times, which leverages the fact that verification of many tasks is easier than executing them. The canonical example of this is the proposed ZK-EVM scaling for Ethereum mainnet, where instead of each block being re-executed by each node in the network, the block is accompanied by a proof that succinctly verifies the correctness of the contents without needing to re-run the full list of transactions.
The vanilla instantiation of the enshrined ZK-EVM asks that the full proof of each block be generated by a single prover within the 12-second Ethereum slot. This has two fundamental limitations. First, it doesn’t leverage the resources of many provers in aggregate (i.e., it is a winner-take-all). Second, it only accommodates workloads whose execution and proving can be done within a single slot. A more general approach allows for multiple provers to work on different tasks in parallel and ideally extends the timeline for the completion of a task to be configurable by the user rather than constrained by slot times.
To see why this is necessary, consider the goal of enabling AI inference onchain. In that world, each transaction may invoke expensive AI operations with different requirements. Rather than relying on a single party to batch prove everything in the block, which would result in further centralization of the builder market, it is more natural to distribute the execution of the tasks to a wide set of supplier nodes to be completed asynchronously and eventually verified onchain.
This is the approach Ritual is taking. They envision tasks with different resource requirements (e.g., hardware, model access, bandwidth, latency, etc.) and propose a two-sided marketplace (Resonance) to find an efficient matching of tasks and suppliers while providing guarantees of correctness through eventual onchain verification (Symphony).
This evolution of blockchain scaling inspires our model.
1.1 Understanding network capacity
In the multiple-supplier model, a natural question users may have is: What is the current capacity of the chain? The answer to this question may inform whether or not a user chooses this platform (over centralized cloud providers), because users need reliability guarantees. Consider a basic first-come-first-served procurement mechanism, where whoever performs the task first receives a payment. FCFS is blind to the true capacity of the chain, because only the winner ends up delivering the completed task, and the losers immediately stop processing and discard their partially completed task to avoid wasting any more resources.[1]
Alternatively, we may solicit bids through an auction in hopes of a better capacity indicator, but not all auctions will result in a good quality signal. For example, it is well known that first price auctions don’t result in truthful reporting, meaning the bids may misrepresent the true capacities. This motivates the idea of a “capacity oracle,” in which the procurement mechanism is designed with the goal of providing a better signal of the chain’s available capacity. For example, if the procurement mechanism is strictly dominant-strategy incentive compatible (DSIC), then the protocol has a perfect oracle because equilibrium bids will give an accurate estimate of the aggregate capacity of the chain.
However, running DSIC auctions in blockchain contexts is notoriously difficult because, unlike the classical auction design settings, they are prone to deviations such as creating many fake identities. For example, in “On Sybil Proof Auctions”, Pan et al. demonstrate that in the forward auction setting, the only Sybil proof and DSIC mechanism is the standard second price auction, which is difficult to run onchain because the auctioneer is untrusted and may inject fake bids. For reverse auctions (which is closer to our setting), “Beyond Winner-Take-All Procurement Auctions” designs procurement mechanisms that are DSIC but not Sybil-proof, as well as mechanisms that are Sybil-proof but not DSIC, but none satisfy both properties.
This post explores how to construct a capacity oracle in a blockchain procurement setting. Section 2 introduces a basic model and proposes a naïve mechanism that is DSIC under a fixed set of identities, but suffers from a simple Sybil attack. Section 3 extends the model to include Sybils and presents two different approaches to combating Sybils (correlated payments in 3.1 and slashing in 3.2). Section 4 studies a practical instantiation of the capacity oracle and demonstrates the trade-off between protocol cost and oracle accuracy numerically, providing plots and concrete takeaways for practitioners.
2. Model
We consider a set of n suppliers, each with the same linear per-unit cost of production and private capacity c_i \in \mathbb{R}_+, i \in [n]. We denote the capacity vector \mathbf{c}. Each supplier submits a bid b_i to the protocol, indicating the amount of capacity they claim to have. The protocol defines an allocation rule x: \mathbb{R}_+^n \mapsto \mathbb{R}_+^n that maps the bid vector \mathbf{b} to an allocation vector \mathbf{x}. Note that there is no constraint on the amount of allocation that the protocol could make, and the allocations can be fractional. You can think of this as the protocol always having the option of creating “fake” work to allocate to suppliers to certify that they have the claimed capacity. Based on the allocations, the suppliers will make decisions about whether they “deliver” the work that was assigned to them. Let d_i \in [0, c_i] denote the amount of work delivered by supplier i (because they cannot deliver more than their true capacity c_i) and \mathbf{d} denote the full vector of deliveries. The protocol also defines a payment rule p : \mathbb{R}_+^n \times \mathbb{R}_+^n \mapsto \mathbb{R}_+^n, that maps the bid \mathbf{b} and delivery \mathbf{d} vectors to a payment vector \mathbf{p}. The full mechanism is defined by the tuple (x,p). Each supplier i has a quasi-linear utility with per-unit cost of production normalized to 1:
The equilibrium bidding behavior of suppliers can be used to construct a capacity oracle. A capacity oracle is a function F: \mathbb{R}_+^n \times \mathbb{R}_+^n \mapsto \mathbb{R}_+ from equilibrium bid and delivery vectors to a real number, that tries to quantify the total available capacity of the suppliers. A perfect capacity oracle F is equal to \sum_{i \in [n]} c_i. Our goal is to design a mechanism with small expected payments \sum_{i\in[n]} p_i that implements a perfect capacity oracle.[2]
2.1 Comments on the model
A few things are worth calling out explicitly. First off, we are considering the common value setting, where everyone has the same cost of production, but a private capacity. This is already a deviation from the standard literature on procurement auctions, which usually models the private information as the “cost,” known only to the supplier (e.g., “Truthful Mechanisms for One-Parameter Agents”). For our domain, we are more concerned with eliciting the capacity of the network rather than the cost, so for tractability, we keep the cost fixed as public information.
Additionally, the protocol can allocate work arbitrarily in our model, which is also a much different setting than traditional procurement mechanisms, where the total allocatable work is fixed. The bounded allocations make sense in the physical world. Consider the government soliciting bids from contractors to construct a bridge; there is only one bridge that can be built, so they can only allocate one unit of work. In the digital setting, where the “work” being done is computational, a protocol can arbitrarily construct tasks for suppliers to do. In the same spirit of Proof-of-Work, creating puzzles that can become arbitrarily difficult, a protocol can make synthetic AI workloads and construct ZK challenges specifically for demonstrating capacity. Indeed, this technique has already been explored by Aleo, albeit for a different goal of attracting an initial set of suppliers. Of course, there is no free lunch, and by individual rationality, if the protocol allocates k units of work, it must pay at least k to the participants to ensure they are incentivized to join the game in the first place.
Note that the baseline interpretation of our model is that the protocol only creates work to ensure availability, but the more practical interpretation would be only to augment the naturally demanded work. If there are periods where organic demand is sufficiently large to ensure a good capacity oracle, then the protocol would not need to create and subsidize any additional work. However, during periods of lower usage, the protocol could increase the workloads it produces. In this light, the protocol can be seen as a controller that ensures that sufficient work is present to maintain a high-quality capacity oracle and a stable supplier set.
More generally, we can consider different types of workloads based on how costly they are as a basis for a capacity oracle. On one hand, organic demand is “free” since the users are paying for it rather than the protocol. On the other extreme, the synthetic workloads that we consider are maximally costly, since the protocol is responsible for covering their costs. As a middle ground, we can imagine workloads that are somewhat useful to the protocol, but not fully paid for by the users. A good example of this is Ritual’s scheduled transactions, which are cron-like jobs that the protocol knows in advance, so it can execute them ahead of time as part of the availability oracle. However, it might be necessary to re-execute some of them if their execution needs to depend on newer state. As such, they are cheaper synthetic jobs but still not free. For the purpose of this post, we won’t model these explicitly.
Finally, note that this initial version of the model doesn’t capture Sybil reports. We present a warmup mechanism to build intuition and show specifically where Sybil reports can cause damage. In Section 3, we explicitly start accounting for Sybils and how to respond to them.
2.2 Naïve solution in a non-sybil environment
Starting in a non-Sybil environment, consider the following allocation and payment rule.
What we are doing here is a “random audit,” where, with some small probability for each supplier, we allocate them their full claimed capacity b_i. If they were allocated b_i and fully delivered the work that was allocated, then we pay them some “reward” r(b_i) on top of their incurred production cost.
Note that as long as r(b_i)>0, \forall b_i >0 and r is monotone increasing in b_i, we have a perfect availability oracle. Since each allocation is drawn independently, we can consider the utility of one supplier and ignore everyone else’s actions. That supplier is considering what to bid. They know that:
- They are selected with probability \varepsilon no matter what they bid.
- For any bid b_i, if they are allocated, they will only be paid if they fully deliver, i.e., d_i = b_i.
- Their net profit r(b_i) is monotone increasing in the amount they report and deliver, up to their true capacity c_i (beyond which they won’t be able to deliver and thus won’t be paid).
Thus, bidding truthfully strictly dominates other strategies, and we have a perfect capacity oracle. Further, the protocol can set \varepsilon to be arbitrarily small, and thus effectively get this information for free. Notice, however, that the expected profit for each supplier is only \varepsilon r(c_i), which is small. This incentivizes a Sybil attack, where the suppliers can increase their chances of getting selected and thus rewarded.
3. Sybils
The mechanism above works perfectly well for any \varepsilon and any monotone function r so long as people can only submit a single bid. However, there is a basic Sybil attack that completely undermines the goal of having a good capacity oracle.
Consider a supplier that submits many copies of their true capacity [c_i,\ldots,c_i]. (Note that we don’t introduce Sybil identity notation into the model explicitly because it clutters the notation, but the Sybillers are exactly as you would expect: a single supplier can report arbitrary capacity with any number of identities.) Since each identity is independently sampled with probability \varepsilon, the probability that at least one identity is allocated increases. If multiple of their identities are allocated, only one will be able to deliver, but there is no downside because the other identities don’t face any punishment for not delivering. Thus, with high probability, the full profit from this strategy is r(c_i), which is much larger than the non-Sybil baseline \varepsilon r(c_i). Further, the quality of our capacity oracle is now arbitrarily bad, because we see a very large capacity aggregated across the bids without knowing which identities will actually deliver.
Clearly, this most basic form of our mechanism is insufficient, so we consider a few ways to address this.
3.1 Approach 1: Correlating the payments
Now, let’s consider what we can do by correlating the allocations and payments of the suppliers. The protocol is still operating over the bid vector \mathbf{b}\in \mathbb{R}_+^n and now implements the following mechanism:
This is the maximally correlated mechanism, because either everyone is fully allocated and paid or no one is. Notice that now supplier i is only paid for delivery conditional on every other supplier also fully delivering what they bid.
It turns out, this results in a perfect capacity oracle, despite the possibility of Sybils. Again, consider the strategy of a single supplier. They know that if they overreport (i.e., if their aggregate report over their identities exceeds c_i), they are guaranteed 0 utility because they won’t be able to deliver their reported capacity when allocated. Their profit is still monotone increasing in their total reported capacity up to c_i, so the best they can do is report a total of c_i capacity (without loss, they can split it over multiple identities). Therefore, in every Nash equilibrium, the resulting capacity oracle is perfect.
This seems magical! We protected ourselves against the Sybil attack, and again, we can choose any value \varepsilon and any monotone function r and guarantee a perfect capacity oracle at any price. While this is a cute trick, it probably is not practical given the obvious griefing vector it exposes. In particular, as a supplier, I know that if anyone fails to deliver what they reported, then no one gets paid. So a single malicious supplier can ensure that this occurs. Further, being allocated is an extremely unlikely event, which makes both the supplier’s profit and the protocol’s expenditure highly variable.
3.2 Approach 2: Adding staking and slashing
Given the brittle nature of the correlated approach, let’s return to uncorrelated auditing from our naïve mechanism. What went wrong with our original mechanism? Well, there was an incentive to misreport because there was no downside for not delivering. A different way we can address this is by adding staking and allowing our mechanism to potentially slash misbehaving suppliers. These negative payments add a layer of accountability that can disincentivize overreporting.
More formally, assume that everyone who wants to participate has to put up a stake amount S, which can be slashed if they don’t deliver. We are going to focus on the maximally aggressive penalty function, which fully slashes the collateral if the delivery is anything less than the full allocation d_i < x_i. This allows the protocol to maximize the effect of requiring stake.[3]
Then we have the following allocation and payment rule:
This is a lot more palatable from the supplier’s point of view. Because there is no correlation, they don’t have to reason about other suppliers’ behavior, and there is no risk of losing their payments because of the dishonesty of others. Further, they will only receive negative payments if they can’t deliver their bid. They can always behave honestly and ensure a non-negative payment.
Suppliers can choose to submit multiple arbitrary bids as long as they have sufficient capital to stake. However, any allocated reports that they don’t deliver on are costly, so they face a risk if they over-promise and under-deliver.
Intuitively, this risk is increasing in the amount of stake S because each overreporting identity is penalized a larger amount. The natural question is, given a maximum amount of stake, how accurate a capacity oracle can the designer hope for? The next section shows that you get what you pay for: the quality of the oracle depends on the amount of over-allocation by the protocol. The protocol can increase the accuracy of the oracle by allocating more work, but it will have to correspondingly increase expenditure to cover the production costs. The remainder of this post is dedicated to showing this trade-off numerically.
This is the first mechanism we study that has equilibria where the suppliers play non-trivial strategies. They are now trading off the risk of being caught overreporting with the upside of increasing the probability that they are allocated and thus earning a larger reward. Now, the supplier’s decision is highly dependent on the exact shape of the reward function r, which we will explore in the following section. Gone are the days of always being fully honest or being a maximal Sybiller.
4. Sybils, slashing, and the price of truth
Given the discussion above, we restrict attention to the fully uncorrelated[4] allocation rule and the fully slashing penalty function. This leaves just the reward function r as a free parameter in our mechanism. Remember, this is the resulting allocation and payment rule:
Our results so far have been general and only relied on the monotonicity of r. Now we are in a new regime, where the strategic behavior of the suppliers at equilibrium and thus the price of a perfect capacity oracle depends greatly on the shape of r.
4.1 Linear rewards are still vulnerable
One very natural choice of r is a linear function of the bid r(b_i) = \lambda b_i, for some \lambda > 0. Interestingly, this is vulnerable to a Sybil attack, no matter how big -S is! Not only do suppliers split their true capacity into smaller chunks to reduce the variance of their rewards, but they also are incentivized to overreport to increase their expected rewards beyond the honest value of \varepsilon \lambda c_i that would result from a single bid of b_i=c_i.
More formally, for any finite stake S and inspection rate \varepsilon, there exists an N,\alpha>1 such that there is a profitable Sybil strategy with N identities that overreports by a factor of alpha. To see why, we normalize c_i=1, and consider the approach of submitting N distinct identities, each bidding a small fixed amount b_i = \alpha / N where 1 < \alpha <1/ \varepsilon.[5] In aggregate, the supplier is reporting b_i N = \alpha capacity, which is an overreport because \alpha > 1.
By playing this strategy, the number of their identities that are allocated is a random variable X \sim \text{Binomial}(N, \varepsilon), so the amount of capacity that the supplier is allocated is \alpha/ N \cdot X. By taking a large N, the supplier can concentrate their reward distribution on its mean \alpha \varepsilon < 1, while making the probability that they are overallocated arbitrarily small. This is beneficial for them, because they approach a reward of \alpha \varepsilon \lambda > \varepsilon \lambda.
The figure below shows this concentration on 0.97 for increasing values of N. Notice that the probability mass to the right of 1 (which results in slashing) can be made arbitrarily small.
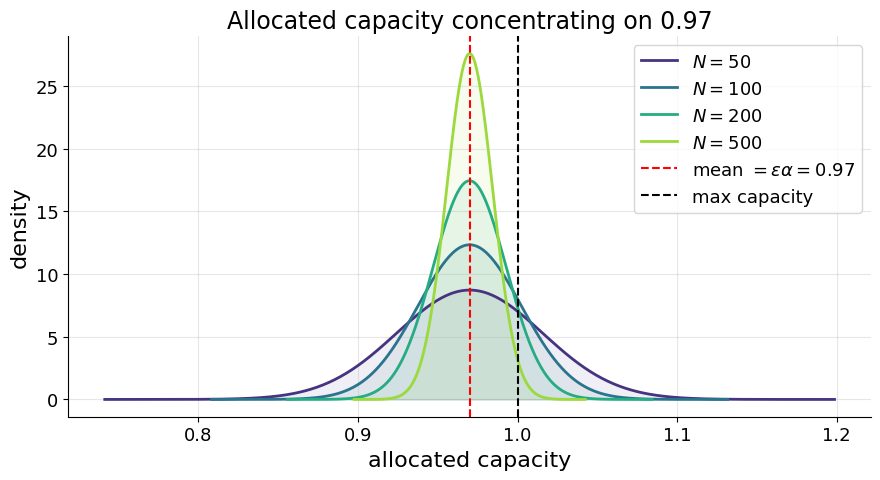
Intuitively, the supplier benefits from splitting into many small identities. Despite overreporting, they can always make the tail probability of getting slashed small enough to be worth the misreport. This result is interesting because the stake doesn’t actually provide any protection. The attacker continues to subdivide, and they are able to minimize their risk of getting caught for overreporting. Further, because the reward function is exactly linear, their smaller reports are paid proportionally to their size.
A pragmatic solution to this problem would be to set a lower bound on the reportable bids b_i. This definitely works, but we are leaving that version of the math out because it is less interesting. A more principled approach is to use convexity of the reward function to disincentivize this infinite splitting behavior.
4.2 Convex rewards
Let’s consider what happens if we make r a convex function. Intuitively, this is helpful because we can disincentivize Sybil attacks directly. For example, assuming the capacity of supplier i is fully allocated, they would always prefer bidding c_i with a single identity as opposed to c_i/2 with two identities because by convexity of r, 2r(c_i/2) < r(c_i).
However, convexity doesn’t guarantee truthful bidding in isolation, because it still might be worth it to split and overreport. The remainder of this article studies a specific family of convex reward functions to illustrate the types of trade-offs the protocol faces when considering the amount of stake to require, the curvature of the reward function, and the resulting cost of a perfect capacity oracle.
We are going to study the general family of convex monomials r(x) = x^p, p >1. The curvature of these monomials is a single parameter p, which we can increase to disincentivize splitting. Further, the monomials have the nice property of r'(0) = 0. As such, we know that the value of bidding an infinitesimally small value is 0 (i.e., r(\varepsilon) \to 0 as \varepsilon \to 0).[6]
We will consider, without loss of generality, a supplier with unit capacity. The supplier doesn’t need to consider other suppliers’ actions, because their allocation and payment are independent of them. We consider the action space where they submit N bids, each with a value of \alpha. This is a homogeneous strategy where they may overreport (by submitting more than 1/\alpha bids), but they do not consider submitting bids of different sizes (\alpha_1, \alpha_2, \ldots). We believe this is without loss of generality up to small rounding errors (e.g., it might be optimal to submit [\frac{1}{2},\frac{1}{2},\frac{1}{2},\frac{1}{100}] where the last small bid only barely increases the expected profit).
The number of identities that are sampled is X \sim \text{Binomial}(N, \varepsilon) and the supplier can fulfill exactly \lfloor 1/\alpha \rfloor of them and pays the slashing penalty for the remaining identities if X - \lfloor 1/\alpha\rfloor>0. This gives the full utility function of this strategy as:
Truthfulness would occur if U(N,\alpha) is maximized at N=1,\alpha=1. There is no closed form for this, so we will compute it numerically. Recall that we are focusing on strategies where the attacker bids \alpha with N Sybils. We now observe that it is sufficient only to consider \alpha \in \{1, \frac{1}{2}, \frac{1}{3}, \ldots \}, because for any \alpha between two points in this set, the supplier can still only deliver \lfloor1/\alpha \rfloor of them, so will chooose the right endpoint of the interval. Further, since the honest behavior earns a utility of \varepsilon, we only need to consider values of \alpha that could result in U(N,\alpha) > \varepsilon. Notice that U(N,\alpha) < \alpha^{p-1}, so
Thus, we only need to check a finite number of \alpha values that satisfy the above condition. It can be shown that the utility is unimodal in N when we fix a value of \alpha (but we will leave out the proof because it isn’t that interesting). Intuitively, this tells us that for each \alpha, there is a unique optimal value N that denotes the optimal number of identities the attacker will use. Thus, we can see if the optimal value of N and \alpha is 1 to determine if truthful reporting is optimal for a given S,\varepsilon.
The figure below shows two examples numerically.
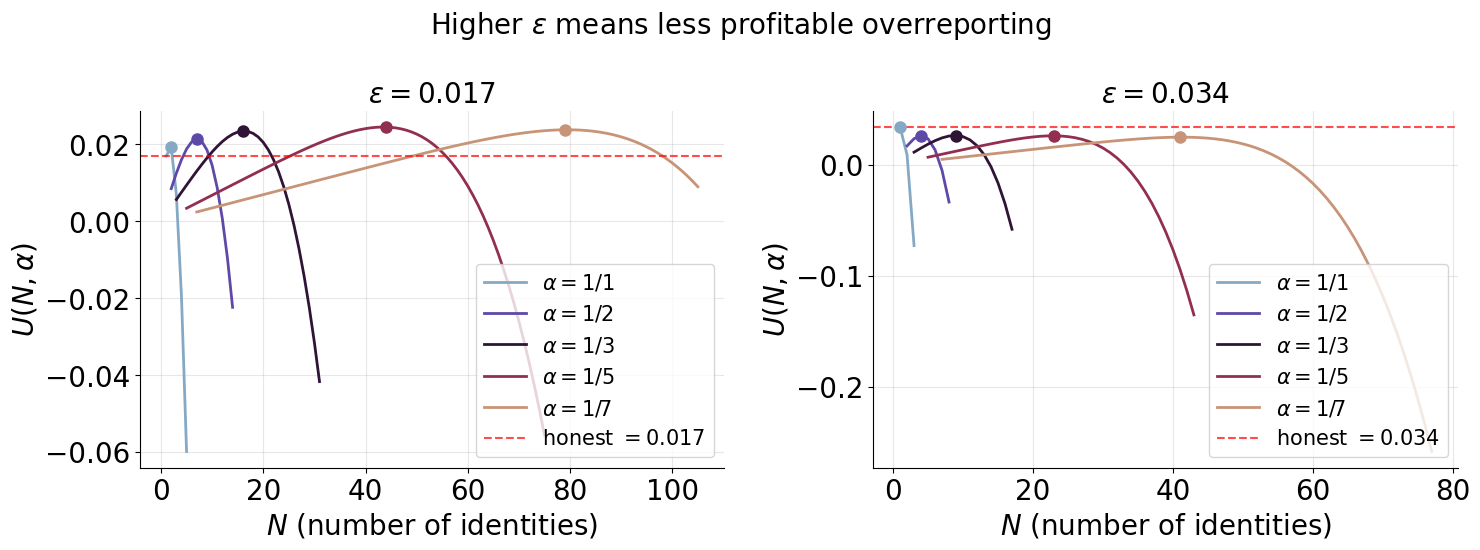
The left subplot of the figure shows \varepsilon = 0.017. For each value of \alpha, we consider each possible number of identities N and denote the maximal utility with a dot. With \alpha=1/5, reporting N=44 Sybils results in a utility of 0.0245, which is much higher than the honest utility of 0.017. On the right, we see how these utilities drop dramatically as we increase \varepsilon. Here, \alpha=1, N=1 achieves the honest utility of \varepsilon=0.034 and all Sybil strategies are worse off. This shows that a higher \varepsilon results in a much more accurate capacity oracle, as expected. However, we do have to pay a large amount due to the higher audit probability.
It is natural to search for the smallest value of \varepsilon such that honest reporting (e.g., \alpha=1, N=1) is optimal. This is because higher $\varepsilon$s require higher payment to compensate. More formally, for a fixed stake S and power p, we want to solve the following:
The utility function doesn’t admit a closed form for the max, so we can use the following iterative numeric procedure to find \varepsilon^*.
- Fix p,S and consider inspection rate \varepsilon.
- For each candidate \alpha, find the N that maximizes U(N,\alpha).
- Check if N is 1 for all \alpha values. Return \varepsilon if so, otherwise continue.
This procedure can be used to find \varepsilon^*. In this unit cost example, the protocol ends up paying 2 \varepsilon^* because the reward function for truthful reporting with a unit capacity is (1+1^p)\cdot \varepsilon^*. For non-unit capacities, the cost to the protocol is linear in \varepsilon^*. The figure below shows a heatmap of numerical calculations for the protocol cost as a function of S,p for the unit capacity example.
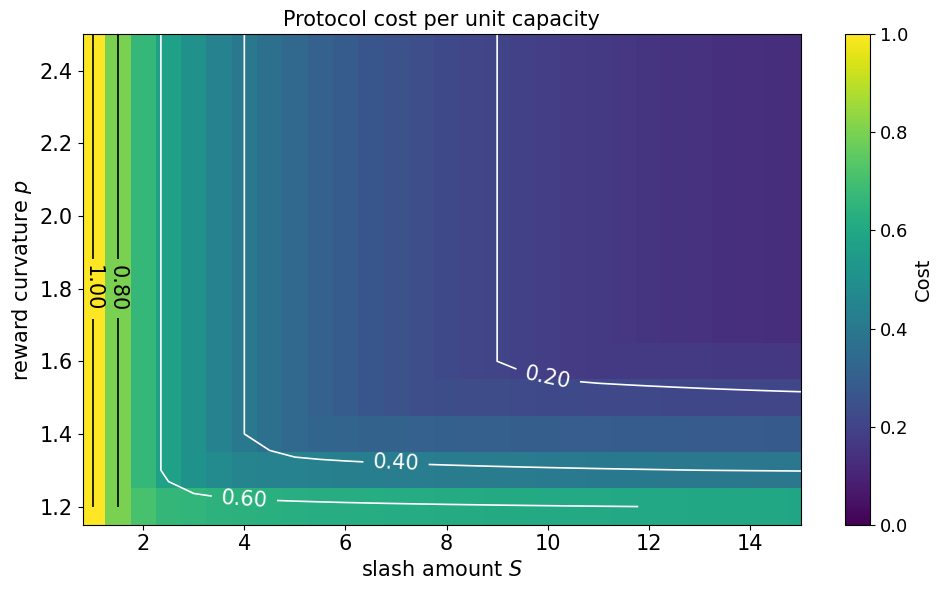
The units of protocol cost are dollars, denoting “the supplier cost of performing a unit of work.” For example, we see that with S=8 and p=2, we have a protocol cost of 0.2, the protocol should expect to pay 20% of the operating cost of the total capacity to elicit a perfect capacity oracle. The units of S are also in dollars. For example, a value of S=8 means that each supplier stakes 8\times the cost of doing one unit of work.
A few notes on the figure:
- You really want some slashing (S\approx 10). With low amounts of stake, the protocol cost converges to 1, which means we have to pay the max capacity to get a perfect oracle. This is the worst case, since the trivial oracle that fully allocates to every bidder is perfect and has cost 1.
- You really want a little curvature (p\approx 1.5). With any lower curvature, the splitting attacks are too powerful, and the protocol cost remains about 0.5, which is quite high. A small amount of curvature in the reward function goes a long way.
- The marginal benefit of stake amounts and curvature decreases quickly. Past the thresholds of the previous two bullets, the protocol cost doesn’t change quickly. This is helpful because it means we don’t have to require too much stake and don’t have to turn the curvature of the reward function too high.
It is also worth noting that the third point above is beneficial for the smaller-scale suppliers. Large stake requirements disadvantage teams with less access to capital. Further, more convex reward functions disproportionately favor high-capacity suppliers and may be a centralization concern. As such, the fact that we can get a perfect capacity oracle with relatively low stake and low curvature is promising. Setting a minimum bid can further alleviate the risk of Sybil attacks and help keep the protocol cost down.
Overall, this analysis is just one natural family of convex payments that the protocol can use. Extending this line of work to make more general statements about the optimal way of designing capacity oracles presents an exciting direction for future work. Further, teams considering implementing capacity oracles can draw on the qualitative analysis performed here to decide how to implement a low-cost protocol for their domain.
5. Summary
We covered a lot! To summarize, we aim to design a protocol that provides a good view of the capacity of its decentralized set of suppliers. We care about the delegation-verification framework, where it is expensive to perform work but costless to verify that it was done correctly. The model operates under the following assumptions:
- Single resource: The protocol is trying to acquire a single type of resource (e.g., compute) from a set of pseudonymous suppliers who can freely create new identities.
- Unit cost: Each supplier has a common, publicly known per-unit cost of production. This assumption makes sense when the resource being acquired is a commodity.
- Free verification: Given that the work is delivered, we assume that the protocol can verify for free that it was done correctly.
- Private capacity: Each supplier has a private capacity (amount of the resource). This is what the protocol is trying to estimate with the capacity oracle.
- Arbitrary allocation: The protocol can augment the organic demand for the resource by allocating any amount of additional work. This is unique to the digital procurement setting.
- Bidding, allocation, and delivery phases: The protocol uses bids to elicit the true capacity of the chain. This allows the protocol to hold suppliers accountable for claiming capacity that they don’t deliver on.
- Protocol objective: The protocol is trying to create a perfect capacity oracle while minimizing its payments to suppliers.
Under this model, we studied audit mechanisms, where the protocol randomly chooses a subset of suppliers to allocate to, and pays them if they deliver fully, while penalizing them if they don’t. From this analysis, we can draw many high-level takeaways for practitioners:
- Random audits work: As we showed numerically in Section 4, under the realistic model we established and reasonable assumptions about the amount of stake the protocol can require, a perfect capacity oracle can be acquired for about 20% of the cost of running at full capacity, even in the absence of organic demand. When true demand is present, user payment can help offset the cost of the capacity oracle.
- Stake amount: Stake is important in the system because it provides a layer of accountability to the protocol. This mitigates the risk of suppliers misreporting their true capacity. Fortunately, the amount of stake needed is relatively mild. For example, if you can require 10\times the cost of running at full capacity as collateral, the slashing is sufficient to disincentivize overreporting in most regimes.
- Curvature of reward function: The protocol can also defend against misreporting through the shape of the reward function itself. We showed that even mild convexity can greatly reduce the protocol cost of getting a perfect capacity oracle.
- Minimum bids: If the protocol can require a minimum reportable capacity, it should. This helps protect against suppliers aggressively subdividing their capacity into smaller and smaller units.
- Correlating the payments: If possible, having some correlation of the payments can also benefit the protocol. For example, if you are able to avoid paying anyone if 50% of the allocated work is not delivered, then the strategy space of the attacker is greatly constrained. With slashing, the correlation can be implemented in an asymmetric way by having correlated allocations but uncorrelated payments: if all of the players are concurrently allocated, then only those who deliver are paid, and those who don’t are slashed. This eliminates the griefing vector that was present in the non-slashing, correlated environment, although it still suffers from burstiness of throughput and high variance of rewards.
- Centralization forces: Another important consideration is how much the protocol favors large suppliers. Obviously, the easiest way to get a perfect capacity oracle and reliable providers is to explicitly restrict the set of eligible suppliers (e.g., Proof-of-Authority) and rely on their reputation and uptime as cloud providers. This is a non-interesting solution. As such, what we described above makes it possible to understand the capacity of a permissionless set of suppliers without too much protocol cost. Still, elements of the design (high stake and curvature) may favor parties with larger access to capital or compute, so protocols should be cognizant of this effect.
We think the foundational model here provides good insights into the theoretical questions around designing good capacity oracles, and the practitioner can take away many qualitative ideas from the numerical results. As detailed throughout the post and in the footnotes, there are many possible ways to generalize this model. From a practitioner perspective, however, probably the most important question is how capacity oracles can scale over non-homogeneous resources. We expect that the set of computational tasks the delegation-verification model will support will be much larger than a single “compute” resource.
Thanks for reading!
-maryam & mike
Notice the similarity to Proof-of-Work here. In the Bitcoin network, it is possible to estimate hash-rate capacity because the puzzle is a simple, well-defined task, and the difficulty adjustment mechanism gives a one-dimensional measurement of how many hashes are needed to find the next block. In heterogeneous environments, where tasks have various computational costs (e.g., running an LLM versus generating a ZK proof) and providers can specialize in different ways (e.g., TPUs vs FPGAs), the capacity estimation problem becomes much less tractable. ↩︎
For the readability of this article, we focus only on perfect oracles, but a natural follow-up question is quantifying how quickly the quality of the oracle degrades and/or the cost of imperfect oracles. ↩︎
Other slashing functions could also be reasonable. For example, if you want to be less punitive, you can only slash proportional to the amount of allocation that is undelivered, which incentivizes partial fulfillment. But for the purpose of maximally deterring splitting, a maximally aggressive slashing function is most effective. ↩︎
The level of correlation is again a design parameter that could be studied in more depth. For example, instead of fully correlating everyone’s payments, you could correlate partially based on a subset of the supplier’s behavior (e.g., payments are made if at least 1/3 of the allocated work is delivered). We focus on the fully uncorrelated version here for tractability. ↩︎
Of course, you have to have the budget to put up stake S for each identity in the protocol. Since we are doing worst-case analysis, let’s assume that the attacker has sufficient capital to make this strategy worth it. ↩︎
There are many other potentially interesting reward function shapes. Characterizing the optimal under different conditions is another interesting theoretical extension to this work. ↩︎