Thanks to Carlos Perez, Matan Prasma, and Wei Han Ng for their feedback.
Rationale
There has been many proposals for state expiry over the year, and they all faltered because of the perceived (rightly so) complexity of the UX that they would entail.
The approach that is suggested in this document, is to gradually expire “cold” data by first moving them to some kind of cold storage where they would take less space, e.g. a flat file.
This is similar to the concept of “ancient” store, to which older blocks are moved in order to keep the database of “hot” blocks small enough to ensure continued performance. Ultimately, these ancient blocks can be deleted, and eip-4444 (history expiry) enshrined this.
Note on terminology
We use the term “era” to describe a period of 6 months after which is it permissible to expire data that hasn’t been accessed during that period. The term is chosen to avoid conflict with the CL concept of “epoch” and also to hint to the fact that this data could be moved to something similar to an Era file.
ancient accounts (v1)
One of the difficulties of full-fledged state expiry, is the possibility of having a contract storage that is partially expired. Some approaches like eip-7736 handle that elegantly, but they would require a fork. As a result, the chosen initial approach expires entire accounts.
A previous analysis of the state has established that this approach would expire about 20% of the state. While this is disappointing in terms of size, this is still a worthy approach when considering the following aspects:
- Deleting 20% of the state also means deleting 20% of the indices, so the gain is larger than it seems.
- More importantly, this will impact IO performance, which is the main killer in db systems. IO performance in DB scales super-linearly with the size of the database. In other words, the positive impact of this approach extends beyond the mere disk footprint.
- It is forward-compatible with going for stronger granularity, and expiring slots from inside active contracts. The same analysis[1] shows that 80% of the size could be saved this way.
But the major advantage of this approach, is how it informs further efforts like (O.o)psie, without having to worry about the impact of a degraded user experience:
- It creates a space for experimenting with user-stored state solutions like (O.o)psie, thus decentralizing overall state holding and giving users a sense of responsibility at no cost.
- It allows for testing a mitigated impact on user experience, and help anticipate worse behavior than are currently seen or envisioned.
Overview
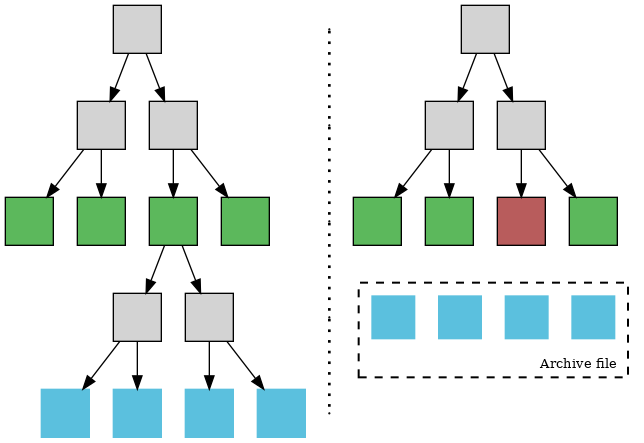
Comparison of the same state data. The left tree doesn’t do any state expiry, and the right one has expired a whole account tree. Green squares represent account nodes, grey squares branch nodes, blue squares slot nodes, and the brick red square represents an expired account node.
The diagram above compares how two nodes save the same state. Let’s suppose that the state contains 4 accounts, and only one of these accounts has a storage tree, which hasn’t been accessed by any transaction in a long period (6 months, 1 year, etc…)
On the left, this is the state as seen by a node that doesn’t implement any state expiry scheme. On the right, the proposed v1 design: the internal nodes are deleted, and the leaf nodes are moved to a file outside of the database. The account node is marked as expired.
- If the node is read again, the expiration marker contains a file offset so that the node data can be read quickly. It is not reinserted into the tree db
- If the node is written to, it is no longer considered expired and therefore needs to be updated and then reinserted. This means the whole state trie must be reconstructed.
We know from our data analysis that the contracts that are expired whole, are quite small. Nonetheless, the bigger ones are having ~2M leaves. For these contracts, some intermediate nodes would also be kept to make recomputation manageable (see v2).
The compression
The expired account has an extra, optional field, which contains a pointer, i.e. a file offset into the archive file. There is one file per era.
The file format is only containing the hashed storage slot numbers, and values.
- Unlike the snapshot, the account address is not stored in there because the account references it directly. This will save some extra space.
- Values are big endian, 32-byte aligned. The expectation is that the heading zeroes will be nullified by compression.
- Slot number hashes are preceding the value, they are 32 bytes as well.
The challenges of expiring nodes
Expiring nodes in the MPT is a harder problem than it seems.
Leaf nodes are already a difficult first step, owing to the side-effect of an insertion: If the new key shares a prefix with an existing leaf node, the trie cannot store both directly under the same path. Instead, the existing leaf is split:
- A branch node is created at the point where the paths diverge.
- The old leaf and the new leaf are each attached to the appropriate branch slot corresponding to their next differing nibble.
- If the shared prefix was previously represented by an extension node, that extension must now point to the new branch node instead of directly to the old leaf.
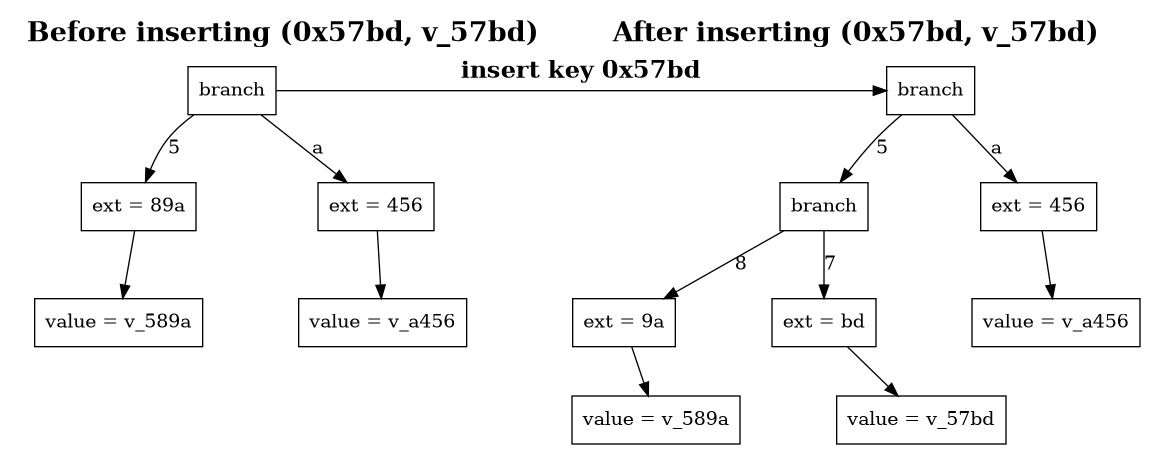
Because this extension node’s child pointer changes, its own RLP-encoded representation—and therefore its hash—also changes. Does this count as a resurrection?
It turns out that, as long as the hash is updated in the new parent branch, the updated leaf can still be “expired”, i.e. left in the ancient store, and the pointer is transferred. But for this to work, the whole key needs to be present in the archive, not just the extension.
Because of a similar issue, internal nodes are unlikely to be expired, although the bottom ones are more likely to be.
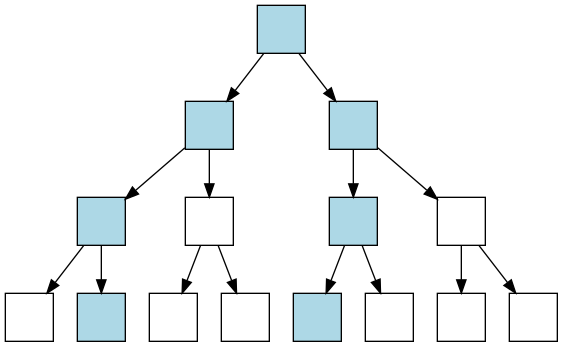
Given a number of writes per block (light blue), the probability of a node to be modified decreases with its depth: 100% at the root and n_{writes}/n_{leaves} at the bottom. (This is a simplified model)
In the v1, storage trees are therefore expired as a whole, but if a bit more complexity is acceptable, a finer-grained expiry is possible. This is the goal of v2.
Resurrecting nodes
When a node is referenced, the compressed store is queried to read its content. If the node is accessed in read mode, there is no need to resurrect it. If it is accessed in write mode, however, then it should be reinserted.
Since only the leaf nodes are stored, the tree must be reconstructed to update the storage root hash of the node.
The tree reconstruction process introduces computational overhead that must be carefully managed:
- For small contracts (which represent the majority of expired accounts according to the data analysis), the reconstruction is relatively quick.
- For larger contracts with up to 2 million leaves, the reconstruction can be computationally intensive. Keeping some intermediate nodes is necessary.
The reconstitution does not imply any gas costs to the user, since the node is choosing to expire some values. As a result, the resurrection costs are to be borne by the client. This induces a potential attack vector, so extra internal nodes could be also saved for larger contracts, so as to quickly and cheaply recover a partial view of the state. This approach would create a partially resurrected tree, which is covered in v2. As a result, large contracts should not be expired in v1. Analyzing usage patterns, it turns out that only small contracts are expireable whole, so this is not an issue.
Finding the data
Until the client starts deleting files, the data is still available. There is therefore no impact on the UX. In fact, and since reading flat files is much faster than reading from a db, it is quite fast to recover.
When the state is deleted, however, this opens the door to attacks targetting missing state. Here are a few strategies, taylored for each actor:
- The block builders themselves can decide to pause any transaction that touches expired code, and download the corresponding state from a cold store. They can also enforce a minimum fee for this resurrection to happen, effectively making this form of state expiry “in protocol” in anything but name.
- Note that this would no longer be an option after shipping FOCIL. This is probably a good reason to relax the FOCIL constraints.
- If anything, a “soft” in-protocol state expiry could be introduced by increasing the cost of state-accessing operations targetting “cold” state. This is too complex to be further discussed here, and will be the topic of a further article.
- Average users don’t have any real-time requirement, so they could simply download the state they are missing from the people they are interacting with, before making their requests.
- It will be more difficult to apply the compression technique directly to RPC providers, as they are expected to provide all the state. For this to work, they need some fallback state-serving nodes - running (O.o)psie or Krogan - that specialize in holding expired state. RPC providers can even use these inexpensive backing stores to delete active state even more aggressively, and potentially provide a secondary RPC service - expired data availability - for other actors to download it from them. We are looking at Krogan for this purpose.
Determining which nodes are to be expired
How does one select nodes to be expired?
In the case of an account, it is possible to write down the last time an account was accessed, and then have a periodical background process that skims outdated nodes. The size of the required data is relatively small:
size = N_accounts_with_storage * era_counter_size
At the time of writing, the Ethereum main state has 350 million accounts. Let’s assume, to find an upper bound, that they all have storage. A 1-byte era counter is enough for the next 64 years[2]. The total extra size is therefore 350 MB. If the compression saves more than this, then this a net benefit, albeit a small one.
Individual slots and internal nodes will be more expensive to track, but are also requiring only one byte. For the current 1.3T slots, it’s ~16GB of storage data if you count the internal nodes. The conclusion is the same: depending on the compression, the size benefit could be worth the tracking.
EL clients are free to choose their expiration granularity, and so the data could take more space if needed.
An alternative is to simply have some nodes do the work of estimating what can be deleted, and publicize a list of expirable locations, for nodes to download and use as a guide for expiring their nodes.
Enshrining into the protocol
Running the expiry algorithm once per “era”, one can define several “stratas” of data. Providing a proof of execution that an account hasn’t been touched in a while could be used to delete expired data. The same proof could be used to resurrect a node, if a user is inclined to pay (dearly) for the resurrection.
Doing so, it is possible to smoothly enshrine the state expiry into the protocol, since that execution proof could be provided by anyone, to instruct clients to delete all the data.
Note that splitting state by era comes with a significant benefit: it becomes possible to maintain a dedicated data store for the expired state of each era, which remains unchanged at least until the next one. This serves as a low-resolution archive node, as users can still retrieve expired data from the same era. It also means that the files can remain as an immutable store until the start of the next era, with the “hot” state remaining in the database.
A word of caution: data availability
Even though some data is cold and will never be needed again, there is a very specific instance in which those cold accounts are still required: Snap sync.
Snap sync uses range proofs to work, and so the whole data is needed in order to reconstruct the tree. It is possible to not answer a request for data that one doesn’t have, of course. In that case, the machine trying to sync, will move on to another peer.
The risk is that in a world where the vast majority of nodes do not store long-expired state, then a piece of the state will be forever lost. While this is not a problem for its initial owner, this means that no node will be able to sync with snap-sync. This will introduce a centralization factor, because the few nodes holding the data can either extort the network for it, or at the very least be hammered by the requests for that state.
As a result, a new sync algorithm will need to be designed, if only to make it possible not to download parts of the state. While this is not impossible, this a herculean endavor that should not be considered lightly. Note that it is unavoidable, see our previous posts, exposing further problems that will have to be solved[^oopsie] for any partially/fully stateless solution to work.
Expiring with a higher granularity (v2)
In v1, moving the entire storage tree is only possible when the contract’s storage is completely inactive. We know that such storage slots account for about 20% of the total state.
Considering a per-slot granularity, and moving inactive nodes from otherwise active contract storages, the fraction of state that can be moved to the archive can potentially represent around 80%[1:1] of the total state.
In this model, individual nodes could be moved to a file, and replaced with a file offset. Using a 8 bytes pointer, the db would save at least (1 + 1 + 17 + 2 * 32 - 9) = 73 bytes per entry.
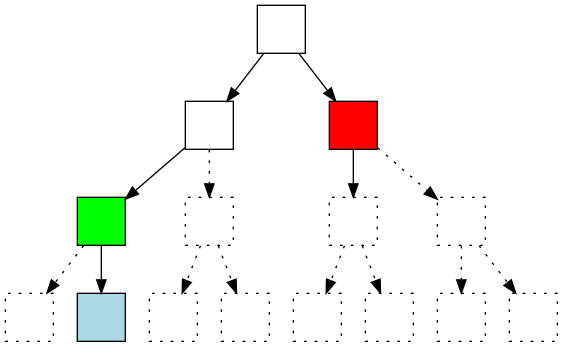
Shows a partially expired tree (expired parts are represented with dotted lines), in which the active blue node prevents the green node from expiring. The whole subtree of the red node is expired, but owing to the time required to recompute the subtree in case any value in that subtree is modified, the red node itself isn’t expired.
Internal nodes up to a given height, would not be saved, as recomputing the subtree would be fast enough. Benchmarks on a minimum spec machine shows the geth hashing performance for a full subtree:
| Subtree height | Entries | Time to Compute Root | Time per Entry | Memory Used |
|---|---|---|---|---|
| 0 | 1 | 1.17 µs | 1.17 µs | 658 B |
| 1 | 16 | 11.68 µs | 0.73 µs | 1,664 B |
| 2 | 256 | 112.36 µs | 0.44 µs | 29,156 B |
| 3 | 4,096 | 1.13 ms | 0.28 µs | 336,044 B |
| 4 | 65,536 | 11.56 ms | 0.18 µs | 4,993,658 B |
A height of 2 or 3 is in the right range, which is the exact height at which savings can happen since internal nodes can be removed entirely - unlike leaves that are only moved to the archive. The table below summarizes how much can be saved, depending on the configuration.
| Depth | Min saving (bytes) | Max saving (bytes) |
|---|---|---|
| 1 | 0 | 530 |
| 2 | 246 | 1590 |
| 3 | 574 | 25970 |
| 4 | 1230 | 416050 |
An implementation is needed to figure out how much data can actually be saved, which will be the topic of a follow-up post.
Next steps
- Measure how much space can be saved by moving things to an external store, and compressing it, depending on how long the expiry grace period is, and what is expired. We know that the theoretical limit as per [1:2] is 80% of the state.
- Implement a simple out-of-protocol version that follows hoodi
- Design a sync algorithm that can handle chunks of the state missing.
https://ethereum-magicians.org/t/not-all-state-is-equal/25508/3 ↩︎ ↩︎ ↩︎
RLP values that are < 128, only require one byte. After 64 years of 6 month-long “eras”, the counter overflows to a second byte,
0x8180. ↩︎