In this post we introduce FastEthereumCrawler, a new crawler for the Node Discovery v5 (discv5) network used by Ethereum, the Portal Network, and a few others, allowing the crawling of large portions of the network in less than a minute.
The crawler is a side-product of our DHT performance optimization work at Codex.storage Research, inspired also by discussions about DAS with EF researchers. Of course, this is not the first crawler, see other works from MigaLabs, from Protocol Labs, and from the Geth team. Our crawler is based on the discv5 implementation in nim-eth.
Cutting to the chase
Below is the progress graph of a crawl of the entire network, mapping out approx. 50000 ENRs, while also verifying connectivity to approx. 20000 nodes, in 55 seconds. This is from a fiber connected but otherwise home node. A small NUC, nothing special.
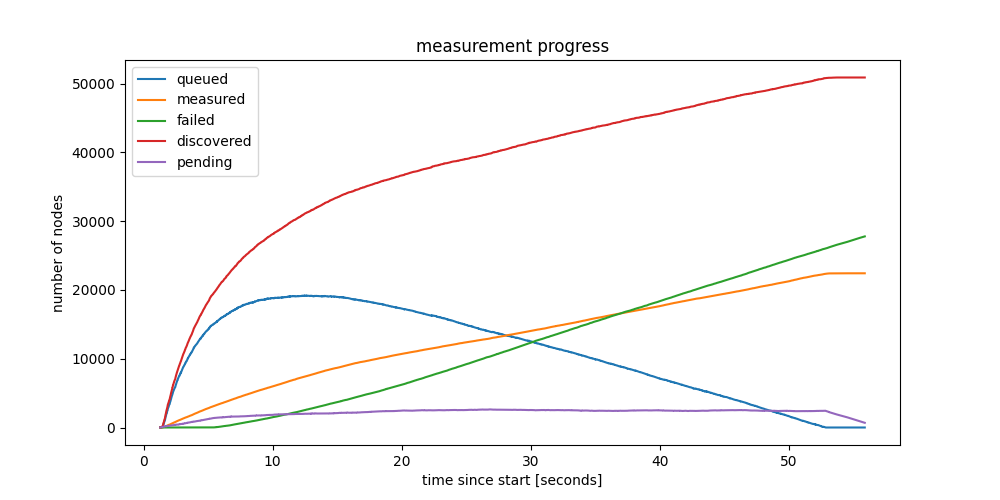
Figure 1: Crawling the Discovery v5 network, progress in time
The crawl started from knowing a single bootstrap ENR, and took 55 seconds, after which eventually new iterations could start. The figure shows the number of nodes discovered as a function of time, in different categories:
- discovered: unique nodes discovered till that point in time. Uniqueness is defined by discv5 nodeID here (although we could also use IP:port pairs, which should lead to similar, although not identical, results).
- measured: nodes that already responded to a direct request message.
- pending: nodes to which we’ve sent a request, but haven’t responded (or timed out) yet.
- failed: nodes to which we’ve sent a request, which already timed-out.
- queued: nodes that are discovered, but we haven’t sent a request yet.
Note that by definition
Interesting to note also how in the first 10 seconds we learn almost 30000 ENRs. Besides identities and IP:port pairs, these ENRs also contain service related metadata published by the nodes. Zooming in on the first 10 seconds shows an interesting perspective on finding nodes providing services, even rare services, surprisingly fast.
Soon, with PeerDAS, the metadata in the ENR will include the custody count required for identifying peers having specific columns in custody. If we are able to get many ENRs fast, like we show here, we can also search for custody nodes for specific rows/columns fast, which was a concern for DAS.
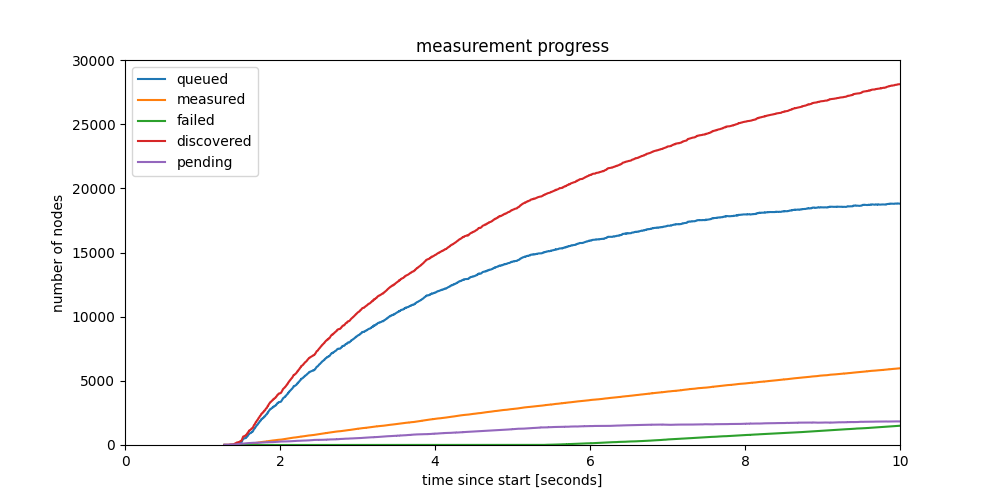
Figure 2: Discovery progress in the first 10 secondds of the crawl
Not all the discovered nodes are Ethereum nodes, and not all are on Mainnet. Below we give the distribution of discovered nodes belonging to different networks, showing only the nodes that we actually managed to contact, the “measured” nodes in the plots above. For Ethereum consensus nodes, we also show the breakdown based on their published forkDigest.
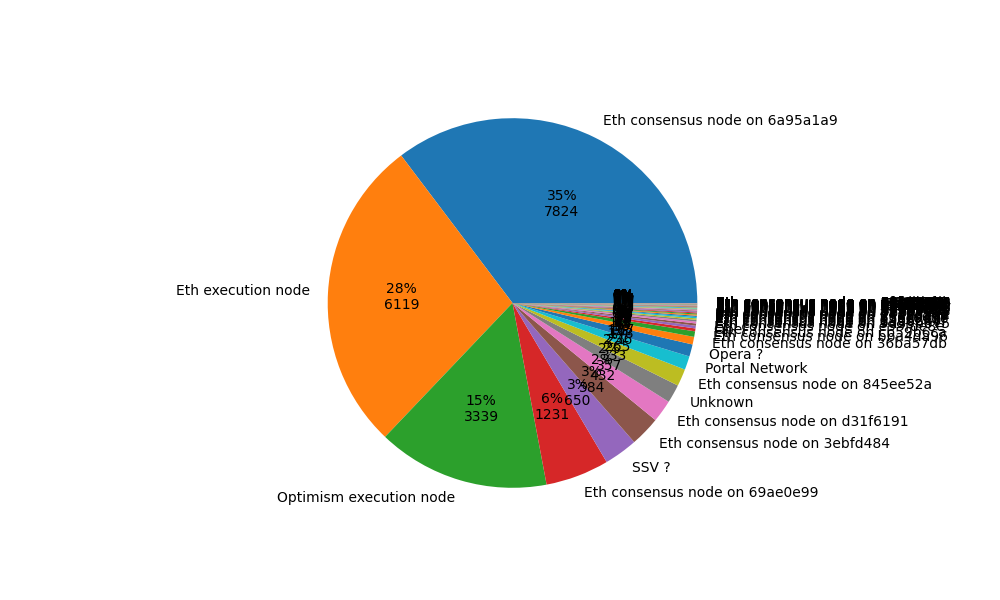
Figure 3: Ratio of connectable nodes belonging to different networks.
Deneb’s fork digest is 0x6a95a1a9, accounting for 35% of the nodes.
Note that we discover all these nodes belonging to different networks in one crawl, since they all use a joint Discovery v5 DHT. Nothing forbids other networks to use this DHT. Some examples are the SSV, C, and Opera categories, each indicating nodes distinguished by publishing fields with these names in their ENR, but not belonging to the Ethereum network. “C”, for example, identifies Portal Network nodes. Services could also start their own isolated discv5 network, in which case we would have to bootstrap the crawl from a node belonging to that network.
Why is our crawler so fast?
Ethereum relies on the Node Discovery v5 protocol for bootstrap and peer discovery. This is a Kademlia-style DHT in which most Ethereum nodes participate, providing their Ethereum Node Record (ENR) to their neighbors, while keeping ENRs of all their neighbor nodes in their Kademlia routing table. We use this DHT to crawl the network.
The typical operation on a Kademlia DHT is a so-called ‘Lookup’, which searches in the DHT for nodes close to a target address, iteratively getting closer-and-closer to this address, until reaching the nodes closest to it. Under the hood, the iterative step uses the FINDNODE request-response pair.
Instead of using high-level DHT primitives like lookups, our crawler directly uses cleverly crafted individual FINDNODE requests to crawl the network fast.
Our first FINDNODE returns a set of ENRs from the bootstrap node. In most cases, 16 ENRs are returned, containing IP:port pairs for 16 new nodes. We can then start new findNode requests to all these nodes, which will similarly return new ENRs. The overlap between these sets will be statistically negligible at the beginning, hence we have a nice exponential start. Of course later, when we have already discovered a large part of the network, we will get less and less new ENRs, however this is not a problem, since we can’t scale our discovery exponentially anyway to avoid using too much bandwidth. We rate-limit FINDNODE requests, while queuing newly discovered nodes for sending requests.
At the end of the process, we’ve sent a single FINDNODE to every single discovered node. By this we verify every single node, checking if there is a real reachable node behind the ENR.
By using FINDNODE requests and queuing discovered nodes, we get both crawling progress (discovering new ENRs) and measurements (verifying that there is a node behind the ENR, but also more) at the same time. Contrary to some other crawlers, we do not try to reconstruct the entire routing table of single nodes. We instead settle for getting only 16 ENRs out of the routing table of a single node, and focus on mapping the whole network fast.
When crafting FINDNODE requests, we also take into account how implementations select the 16 ENRs for their response. This is needed for fast crawling since the discv5 specification does not mandate this behavior, leaving it to the implementation. In more detail, we diversify between the requests sent to the nodes, by flipping one of the first 16 prefix bits. In discv5, where there is no explicit target address in the FINDNODE request, this is achieved by specifying requested distances between 256 and 240. With this logic, we expect to explore sub-spaces belonging to each combinations of the first 16 bits quite fast, which is very likely to provide us the whole network (nodes from each of the 2^{16} sub-spaces explored).
What else can we measure?
When sending a FINDNODE request to a node, under the hood, several things happen. First, discv5 performs a key exchange. Then, the 16 ENRs are sent back, but an ENR is up to 300 bytes long, so to avoid large UDP packets, discv5 sends the response in multiple smaller UDP packets, sending only 3-4 ENRs per packet.
We can use these UDP packets to perform additional network measurements. Even better, these measurements are free, without requiring additional network traffic.
First, we can measure Round Trip Time (RTT). We have modified the underlying code to measure RTT already during the key exchange, with the added benefit of measuring RTT on first contact independent of the actual Discv5 message sent. Below we show the RTT distribution to all the nodes found.
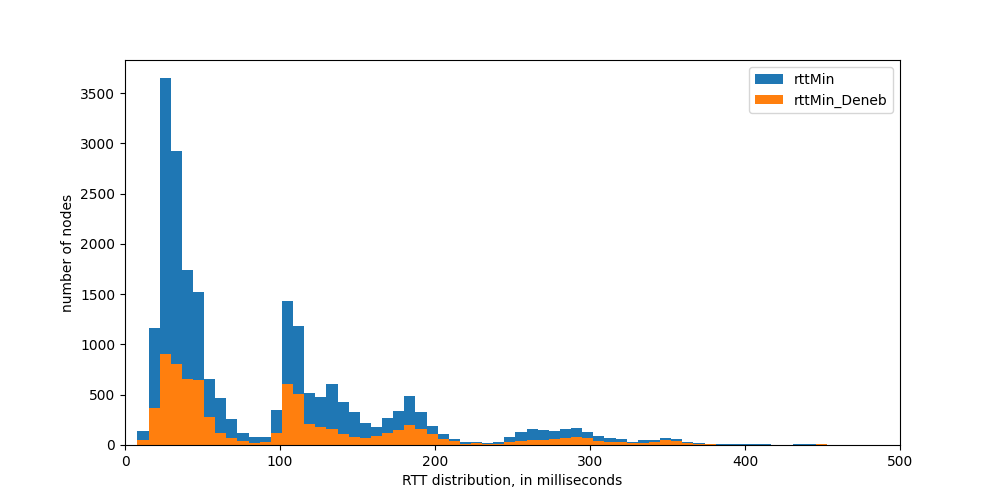
Figure 4: Rount Trip Time (RTT) distribution, measured from Italy, to all nodes, and to nodes belonging to Ethereum mainnet (Deneb)
We can also estimate bandwidth using the packet-pair technique based on the time-difference of received response packets. We have an initial implementation of this, although it needs a bit more work to return reliable results. Below we show what we get now, we plan to update this soon with better results.
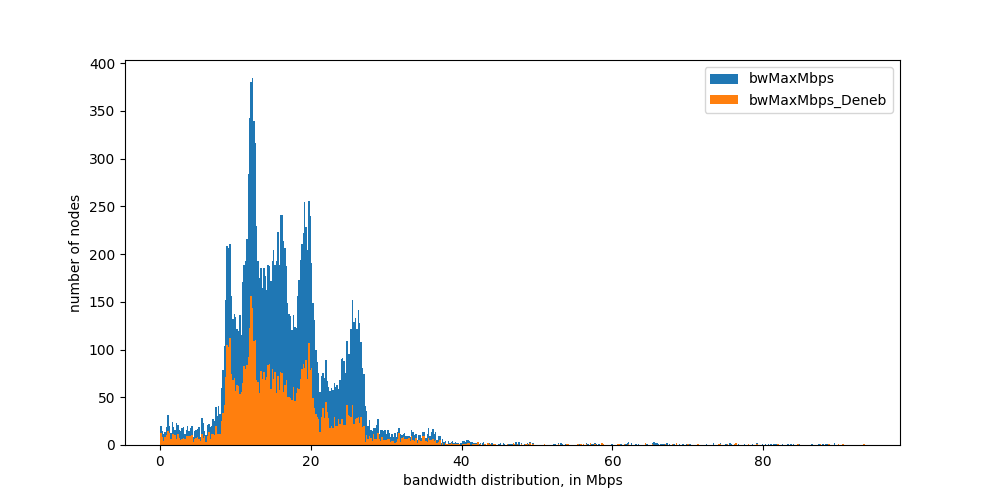
Figure 5: distribution of estimated bandwidth from other nodes to our node, measured from Italy.
How much traffic does this use?
For each findnode, we send 2 packets (one for key negotiation, one with the actual message), and receive 5-6 packets. Approximately 500 bytes egress, 3600 bytes ingress, on average. With 20000 nodes responding and another 30000 not responding, that’s around 87 MB of traffic. Below we show the traffic trace of the crawler, obtained with tcpdump.

Figure 6: Traffic amount consumed by a full crawl cycle.
By rate-limiting FINDNODE requests, we control egress bandwidth consumption directly. Since replies are limited in size, we also keep ingress under control with this. For RTT and bandwidth measurements to be meaningful, it is important to keep these limits well below the uplink and the downlink bandwidth of the crawler node, but as shown above, this is hardly an issue, as the top usage is 20 Mbits/sec downlink and 4 Mbits/sec uplink with the rate we’ve used here.
What about all those failed nodes?
Our crawler checked all discovered ENRs by sending a FINDNODE request, but about half of them failed to respond. This could be due to several reasons:
- Lost UDP packets
- Stale ENRs of nodes long gone
- Connectivity limitations due to NAT and/or firewall
We have added an option to the crowler to have multiple retries, but that did not change much, as it can be seen below. Even if retrying failed nodes 3 times, the “measured” curve showing connectable nodes flatline, showing that we can rule out random UDP losses. Whether these nodes left the network, or just can’t be connected, is something to investigate. The crawler itself can’t distinguish.
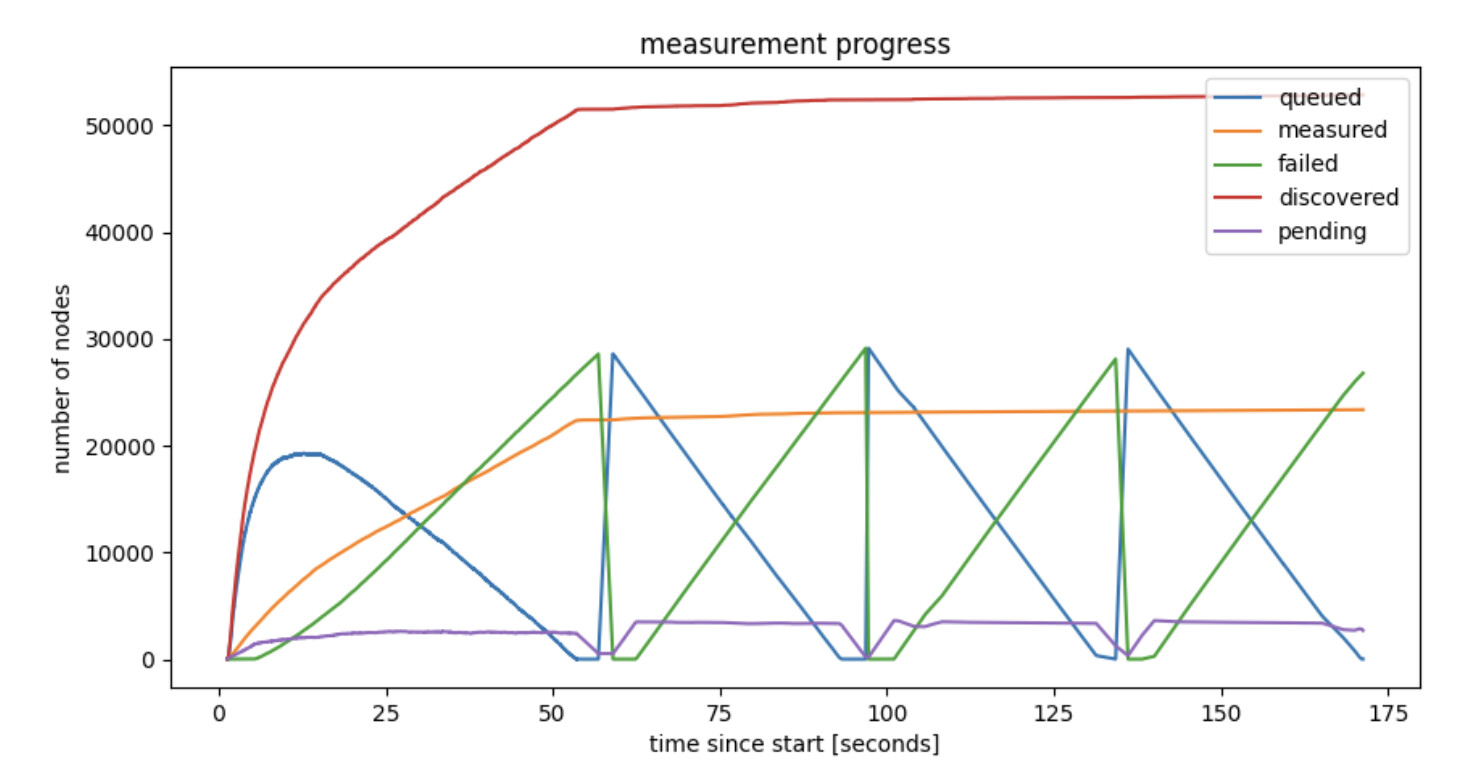
Figure 7: Retrying failed FINDNODE queries 3 times.
It might also happend that nodes avoided responding if they have blacklisted our node for some reason. Our crawler is basically undetectable, since it sends only a single message to every node. However, during development we’ve run it a many times, so there is a slight chance that some of the nodes did not respond because they’ve blacklisted our IP. We tried to double-check this by running the crawler from a different location, and the results matched, so we don’t think blacklisting was an issue.
Do we discover the whole network?
One of the most interesting questions is whether we discover the whole network. It is also a question that does not have a single answer.
The answer is: Yes or No, depending on how we interpret the questions.
Answer from the ENR point of view: No, there are more ENRs to discover
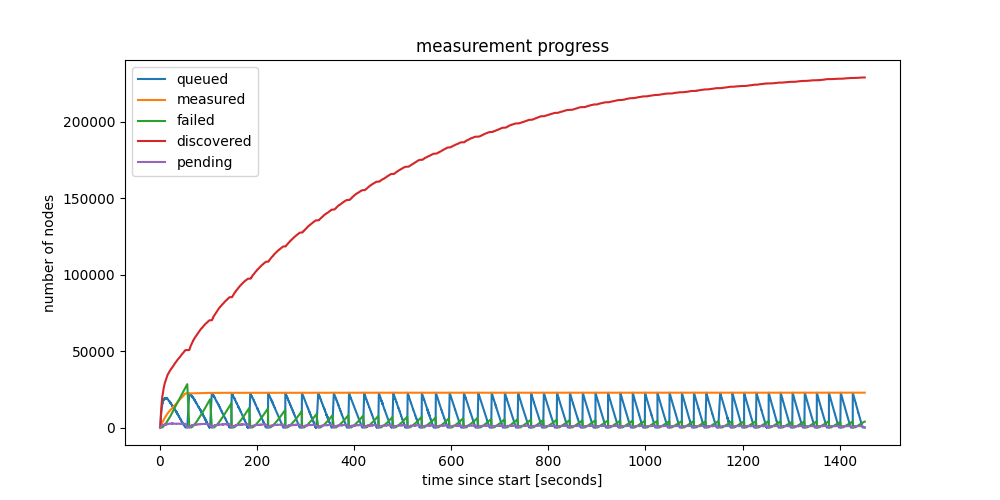
Figure 8: Running 50 crawl cycles while accumulating results.
If we run more iterations, we can discover much more ENRs, as the red line in the figure below shows. After 50 cycles, we discovered almost 230000 ENRs belonging to unique nodeIDs! More specifically, we see 228852 unique nodeIDs, but only 145512 unique IP:port combinations, which is already a bit suspicious.
Answer from the Nodes point of view: Yes, all connectable nodes were discovered in 55 seconds
As the figure above also shows, the “measured” line remains constant after the first cycle. We did not manage to connect to almost any of these ENRs discovered later. We are still investigating whether this is an error in our code, or the reality, but currently it seems our crawler manages to find almost all connectable nodes in the first cycle, in less than 55 seconds.
We could still discover more nodes in a few ways:
- Staying longer in the network, we could wait for nodes behind NAT to connect to us
- We could also try to connect to nodes using other protocols, e.g. libP2P, hoping that that would succeed.
Our crawler is not doing these at the moment, but these are obvious potential extensions.
The relative ratios of discovered ENRs is slightly different, but similar to those of measured nodes.
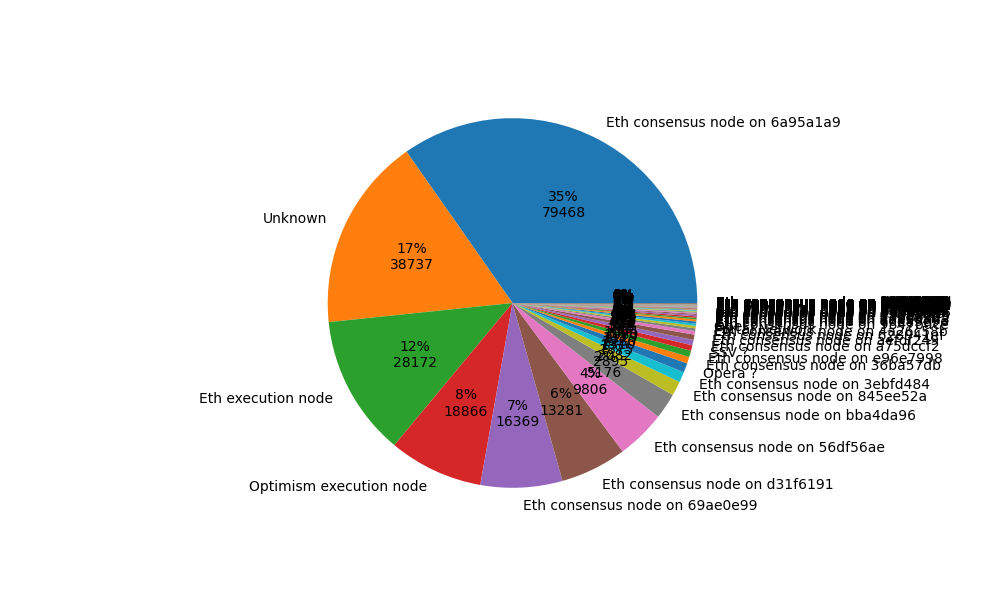
Figure 9: Ratio of ENRs belonging to different networks.
Deneb’s fork digest is 0x6a95a1a9, accounting for 35% of all ENRs.
Can we do the crawl even faster?
There are still a few ways to crawl faster, which we haven’t explored yet. A few that comes to mind:
- The trivial: start from more Bootstrap nodes, or actually from any list of nodes belonging to the network.
- The obvious: allow more requests per second. The fastest we’ve tried is 1000 FINDNODE requests/second, which is far from maxing out our uplink or downlink. However, it is already maxing out a single CPU core. We’ve yet to streamline the code to use less CPU or use multiple cores.
- The UDP level API: As we’ve said, responses to FINDNODE are coming in multiple UDP packets. Yet, we are using the “findnode” API, which waits for all the response UDP packets, aggregates all 16 ENRs into one response, and only then handles it back to the caller. We could clearly be more reactive here.
- The ID space conscious: our crawler explores the node ID space randomly, without looking into the distribution of what IDs we find, and where are the “holes” in the ID space where we could probably find more nodes. If we would store discovered nodeIDs in a Trie, we could explore the ID space in a structured way, probably leading to better crawl performance.
Can we do the crawl slower?
Of course, crawling could also be done slower. In fact, most DHT implementations perform random lookups every now-and-then to explore the network. Slow, or repeated crawls can also be useful to give historical perspective on the lifetime of records and nodes, on node-churn, etc.
Finally, can I try the crawler?
Sure, here’s the code on GitHub. Although written in the Nim language, it is self-contained, building also the compiler itself. Just git clone, and make. Enjoy! Even during Devcon SEA ![]()

Figure 10: RTT distribution from Devcon SEA