by KD.Conway
TL;DR
-
We propose a decentralized and verifiable cloud service protocol on Ethereum, which can provide computationally intensive service to all web2 or web3 applications, making decentralized ChatGPT, decentralized blockchain explorer reality. By migrating the full stack, including frontend and backend components, to the decentralized cloud, we move toward fully decentralized and verifiable end-to-end Web3 applications.
-
The protocol operates under a minority trust assumption, requiring only one honest node to guarantee service quality. Additionally, the correctness of the cloud service is verifiable on Ethereum.
-
With near-zero on-chain costs, our decentralized cloud service platform can be even more affordable than traditional centralized options.
Protocol Overview
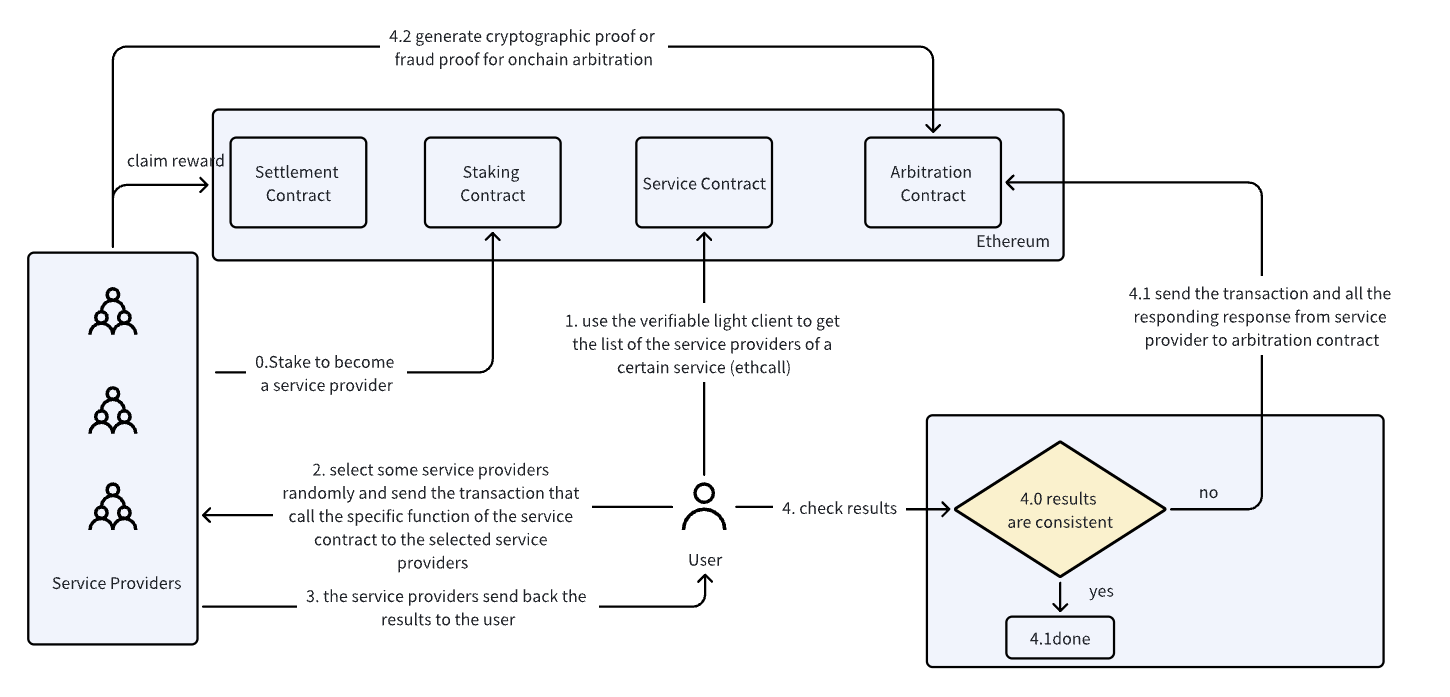
A service contract exists on Ethereum, functioning similarly to a gRPC protobuf. This contract defines the service, and the functions within it specify the methods that can be invoked.
Each service provider must register and stake on the service contract. For each service, multiple providers will be available to offer the service.
When a user initiates a service request, such as requesting an AI inference from an LLM model:
-
The user first utilizes a verifiable Ethereum light client, such as Helios, to retrieve the list of available service providers from the on-chain service contract.
-
The user randomly selects several providers from this list.
-
The user then sends off-chain transactions to these selected providers in parallel. These off-chain transactions are essentially the same as calling the corresponding service function in the smart contract, but they use a different chain ID. This specific chain ID indicates that the transaction is intended to call a cloud service rather than perform an on-chain transaction on Ethereum.
-
The service providers execute the required computations in their local environments according to the program defined in the corresponding function in the service contract. They then return the responses to the user. Each response is signed by the service provider and includes the user’s transaction hash and the results.
-
Upon receiving the responses from the selected providers, the user first verifies the signatures and checks the consistency of the results.
-
If the results are consistent, the service is considered to have functioned correctly, and no further action is required.
-
If there is a discrepancy in the results, this indicates the presence of at least one malicious service provider. In this case, the user submits the providers’ responses to the on-chain arbitration contract. This triggers a process where the service providers must defend the accuracy of their results. The on-chain arbitration process is detailed in the following section.
-
Service Contract
The design of the service contract is akin to the design of gRPC. A new service contract corresponds to a new service in gRPC, and the functions defined in the service contract specify the methods that can be invoked. Due to the constraints of smart contracts, we cannot implement complex computations, such as AI computations, directly within the smart contract. Instead, we define a standard for writing a program, which is then uploaded to decentralized DA services, with the program’s hash stored in the on-chain smart contract.
Following the design principle of “Separate Execution from Proving,” there are two implementations for the service program. One is compiled for native execution, optimized for speed, and can leverage multithreaded CPUs and GPUs to accelerate execution. The other implementation is for proving; the service program is compiled into machine-independent code, allowing us to use zkVM (zero-knowledge virtual machine) or fpVM (fraud-proof virtual machine) to generate proofs. This dual-target approach ensures fast execution, while proving is based on the machine-independent code.
For example, consider matrix multiplication. Native execution utilizes GPU computation (e.g., CUDA) for acceleration. During the proving phase, the service program is compiled into machine-independent instructions, which can be executed in zkVM or fpVM. Both implementations ensure consistent execution results.

When processing user requests, service providers will run the program in the native execution environment and return the results to the users. Only when on-chain arbitration is required will the service providers run the program for proving. This approach allows service providers to handle requests as quickly as possible in most cases.
Additionally, the service program can be configured to read data from trustworthy sources, such as Ethereum or other blockchains, as well as from decentralized, trustworthy data storage providers. This flexibility allows the service program to function as a blockchain explorer, an AI service, or a decentralized search engine.
A demo version of the service contract is shown below.
contract Service {
// address => web2 domain
mapping(address => string) serviceProviderHost;
address[] serviceProviders;
// function selector => programHash
mapping(bytes4 => bytes32) programHashs;
event Request(
address account,
bytes4 functionSelector,
bytes32 programHash,
bytes input
);
function func1(bytes calldata input) public {
emit Request(msg.sender, this.func1.selector, programHashs[this.func1.selector], input);
}
}
Note that func1 specifies the method that can be called. When a user wants to call func1, instead of sending an on-chain transaction on Ethereum, the user needs to send an off-chain transaction directly to the service providers. Besides, the user can obtain the list of service provider addresses, along with their corresponding Web2 domains using Ethereum verifiable light client.
Onchain Arbitration
We support multiple proving systems for on-chain arbitration, including zero-knowledge proofs, Trusted Execution Environments (TEE), and fraud-proof systems. For demonstration purposes, we focus on the fraud-proof system, as it offers lower generation costs compared to zero-knowledge proofs and does not require specific hardware. In previous work, we demonstrated the ability to generate fraud proofs for extremely large AI models. For more details, please refer to opML ([2401.17555] opML: Optimistic Machine Learning on Blockchain).
The on-chain arbitration process using the fraud-proof system proceeds as follows:
-
If a user receives inconsistent results from the service providers, they submit the providers’ responses to the on-chain arbitration contract, initiating an interactive dispute game with all the involved providers.
-
At this point, the service providers must run the proving-version of the service program in their local fraud-proof VMs to generate the fraud proof, which they then submit to the on-chain arbitration contract to defend their results. For more details on the interactive dispute game, refer to the fraud-proof system design.
-
Service providers who supplied incorrect results will lose the dispute game, resulting in their staked amount being slashed. The slashed stake will be distributed to the winners of the dispute game, as well as to the user, as compensation.
This on-chain arbitration mechanism ensures that only one honest node is required to guarantee the correctness of the provided service. As a result, the protocol relies on a minority trust assumption and inherits security from Ethereum. Assuming at least one honest node and the safety of Ethereum, the protocol can guarantee the correctness of the service.
It’s important to note that on-chain arbitration only occurs when some service providers produce incorrect results. In typical cases, no on-chain interaction is needed, which allows the service to operate as quickly as current centralized cloud service providers.
Charging Mechanism
There are several possible charging mechanisms:
-
Subscription Model: This is similar to the Web2 approach, where the charging mechanism can be conducted off-chain. For example, to use ChatGPT via an API for commercial purposes, you would pay OpenAI a monthly fee to access their services. Multiple service providers can offer the service, allowing for competition and choice.
-
On-Chain Payment Mechanism: Paying for each request on-chain can be costly due to transaction fees. Batching and rolling up these requests and payments can significantly reduce on-chain transaction costs. One possible approach is to use payment channels to pay for requests. Alternatively, service providers could generate service proofs and claim fees as follows:
-
A service agreement contract specifies the price for each service request.
-
Users first stake funds into the service agreement contract.
-
Service providers can claim their fees by submitting service proofs to the on-chain service agreement contract. To minimize transaction costs, providers can batch and roll up user requests.
-
The on-chain service proof is a zk-proof, which verifies that the service provider has delivered a certain number of responses to users. The provider can then claim the corresponding service fees according to the agreement contract. This proof ensures the correctness of the user’s request transaction signature, the service provider’s response signature, and the transaction nonce.
-
-
Free Service Model: Another approach is for companies to cover the service fees by the themselves (currently, the web2 companies pay the cloud service fee by themselves), offering free services to users while generating revenue through other means, such as advertising or VIP services.
Advantages
-
This decentralized cloud service can be cheaper than centralized cloud services while maintaining similar speed.
-
Cost-Effectiveness: Decentralized servers can be significantly cheaper than centralized cloud servers. For example, io.net has shown that the cost of decentralized GPUs can be as low as one-third of the cost of AWS. For services with lower security requirements, such as using LLMs for personal queries, using just two nodes is often sufficient. Additionally, a random check mechanism can be adopted, querying one node most of the time and occasionally checking another to verify correctness. This setup can be more cost-effective than centralized platform.
-
Scalability and Speed: This platform can outperform centralized systems, especially for computationally intensive tasks. A decentralized cloud service platform operates on an N-to-M model (N users with M servers, where the number of servers can be infinite), whereas centralized platforms use an N-to-1 model (N users with a single super server). This allows a decentralized cloud service platform to scale more effectively. For instance, a centralized AI platform like ChatGPT may slow down during peak times because it can’t scale its computing power quickly enough. In contrast, decentralized platform can dynamically distribute the load across many servers, ensuring faster response times even during heavy usage.
-
-
Trustless and Verifiable: The protocol operates under a minority trust assumption, requiring only one honest node to guarantee service quality. Additionally, the correctness of the cloud service is verifiable on Ethereum.
-
Censorship-Resilient: This platform contributes to a more robustly decentralized Web3, enhancing censorship resistance.
Toward Fully Decentralized and Verifiable Web3 Application
With this protocol, we can move toward fully decentralized and verifiable Web3 applications.
Decentralized and Verifiable Blockchain Explorer: Currently, blockchain explorers like Etherscan are hosted by centralized entities, and the results they present are not verifiable. If such an explorer were hacked, it could display malicious and misleading information, such as fake transactions or contracts, potentially leading to phishing scams. By migrating the entire blockchain explorer—including both the frontend and backend services—to our platform, we can ensure full verifiability and robust security for the blockchain explorer.
Decentralized, Verifiable, Faster, and Cheaper AI Platform: This protocol enables the creation of a fully decentralized, verifiable, and cost-effective AI platform. By moving the entire stack, including both frontend and backend services as well as AI computation, to a decentralized cloud, we can build an AI platform that is not only more affordable but also potentially faster than centralized alternatives.
Decentralized Cloud Gaming: Some games require high-end hardware, such as powerful GPUs and CPUs, leading game companies to move their games to cloud services, reducing the hardware requirements for customers. We can similarly bring Web3 games to our platform. Since our platform is verifiable on Ethereum, game reward settlements can be easily managed through smart contracts.
Further Discussion
Updating the State
In the previous discussion, the service program operates under a stateless design, meaning it does not modify its internal state. However, the data source used by the service program is upgradable. For instance, if a service program uses Ethereum as its data source, users can interact with smart contracts on Ethereum to update the state. The service program can then utilize the latest Ethereum state as its data source, enabling the implementation of a decentralized explorer.
If updating the internal state of the service program is required, a state machine replication network must be established among the service providers. In this case, each service program would correspond to a layer 2 or layer 3 blockchain on Ethereum. When users invoke a method that updates the internal state, they would send the transaction to the corresponding layer 2 or layer 3 blockchain. The service providers would then reach a consensus on the execution results of that transaction and update the internal state accordingly. Periodically, the layer 2 blockchain would roll up the transactions and its latest state back to Ethereum.
Verifiable FHE
To ensure user privacy, Fully Homomorphic Encryption (FHE) can be integrated into our protocol. In this case, the FHE computation would be incorporated into the service program. Instead of sending plaintext data to the service providers, users would encrypt their input and send only the ciphertext, thereby preserving their privacy. Additionally, if on-chain arbitration is triggered, the FHE service program would be compiled into machine-independent instructions, and a fraud proof or zk-proof would be generated to make the FHE computation fully verifiable.
Related Work and Comparison
Comparison with Web3URL
Web3URL (https://w3url.w3eth.io/) is an interesting project that transforms Ethereum into an unstoppable decentralized web server. Our protocol can be seen as a significant extension of Web3URL. In Web3URL, service functions must be written within smart contracts, which naturally limits large-scale applications. In contrast, our protocol supports complex service programs, such as AI computations, and provides flexible access to large-scale data, making decentralized ChatGPT and decentralized explorers a reality.
Comparison with ICP
The Internet Computer (ICP: https://internetcomputer.org/) hosts decentralized serverless compute, similar to our goal of creating a decentralized cloud service platform. However, we differ from ICP in several key aspects:
-
Ethereum Integration: We are building on Ethereum, allowing us to inherit its security features.
-
Higher Security: We achieve a higher level of security compared to ICP. While ICP operates in a Byzantine Fault Tolerance (BFT) network under a majority trust assumption—requiring that most nodes in the subnet are honest—we adopt an approach similar to rollups, with on-chain arbitration ultimately reverting to Ethereum. This allows us to guarantee correctness under a minority trust assumption, where just one honest node can ensure the integrity of our protocol.
-
Complex Computation: Following the design principle of “Separate Execution from Proving,” we can handle complex computations natively, such as LLM inference or even fine-tuning. In contrast, service programs in ICP always run within canisters, which significantly limits their applicability for large-scale computations.
If you are interested in this project or have suggestions for improvements, please feel free to reach out to me.