I wrote a short whitepaper for my idea:
Plebbit: A serverless, adminless, decentralized Reddit alternative
Abstract
A decentralized social media has 2 problems: How to store the entire world’s data on a blockchain, and how to prevent spam while being feeless. We propose solving the data problem by not using a blockchain, but rather “public key based addressing” and a peer-to-peer pubsub network. A blockchain or even a DAG is unnecessary because unlike cryptocurrencies that must know the order of each transaction to prevent double spends, social media does not care about the order of posts, nor about the availability of old posts. We propose solving the spam problem by having each subplebbit owner run their own “captcha server” and ignore posts that don’t contain a valid captcha challenge answer.
Public key based addressing
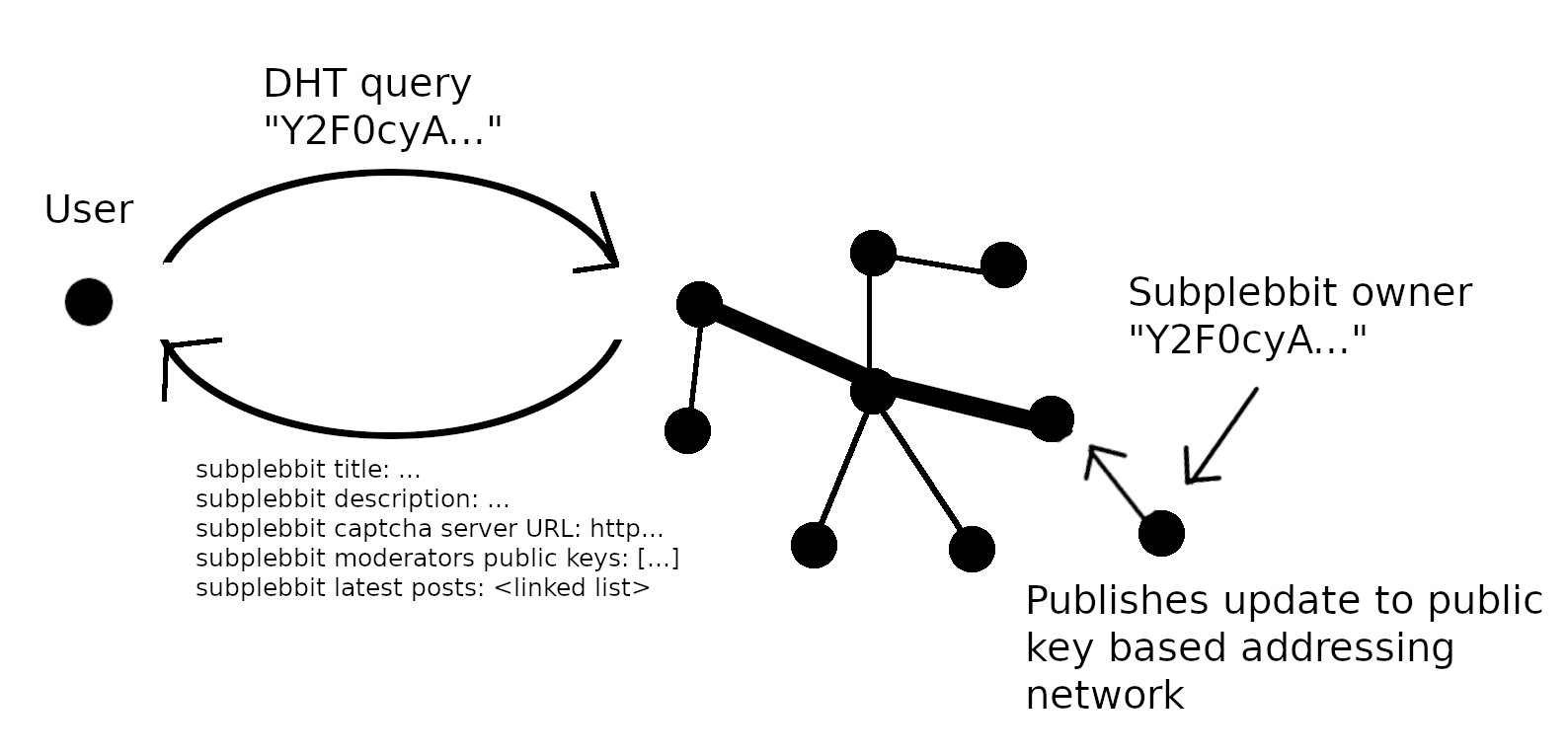
In Bittorrent, you have “content based addressing”. The hash of a file becomes its address. With “public key based addressing”, the hash of a public key becomes the address of the subpleddit. Network peers perform a DHT query of this address to retrieve the content of the subpleddit. Each time the content gets updated, the nonce of the content increases. The network only keeps the latest nonce.
Peer-to-peer pubsub
Pubsub is an architecture where you subscribe to a “topic”, like “cats”, then whenever someone publishes a message of topic “cat”, you receive it. A peer-to-peer pubsub network means that anyone can publish, and anyone can subscribe. To publish a post to a subplebbit, a user would publish a message with a “topic” equal to the subplebbit public key (its public key based addressing).
Captcha server
A “captcha server” is a URL that prompts the user to perform a captcha challenge before a post, then sends him a valid signature if completed successfully. The captcha server can decide to prompt all users, first time users only, or no users at all. The captcha server implementation is completely up to the subplebbit owner. He can use 3rd party services like Google captchas.
Lifecycle of creating a subplebbit
- Subplebbit owner starts a Plebbit client “node” on his desktop or server. It must be always online to serve content to his users.
- He generates a public key pair, which will be the “address” of his subplebbit.
- He sets up a captcha server of his choice. It must also be always online to server his users.
- He publishes the metadata of his subplebbit to his public key based addressing. This includes subpebblit title, description, rules, list of public keys of moderators, and the captcha server url
Note: It is possible to delegate running a client and captcha server URL to a centralized service, without providing the private key, which makes user experience easier, without sacrificing decentralization.
Lifecycle of reading the latest posts on a subplebbit
- User opens the Plebbit app in a browser or desktop client, and sees an interface similar to Reddit.
- His client joins the public key addressing network as a peer and makes a DHT query for each address of each subplebbit he is a member of. The queries each take a several seconds but can be performed concurrently.
- The query returns the latest posts of each subplebbit, as well as their metadata such as title, description, moderator list and captcha server URL.
- His client arranges the content received in an interface similar to Reddit.
Lifecycle of publishing a post on a subplebbit
- User opens the Plebbit app in a browser or desktop client, and sees an interface similar to Reddit.
- The app automatically generates a public key pair if the user doesn’t already have one.
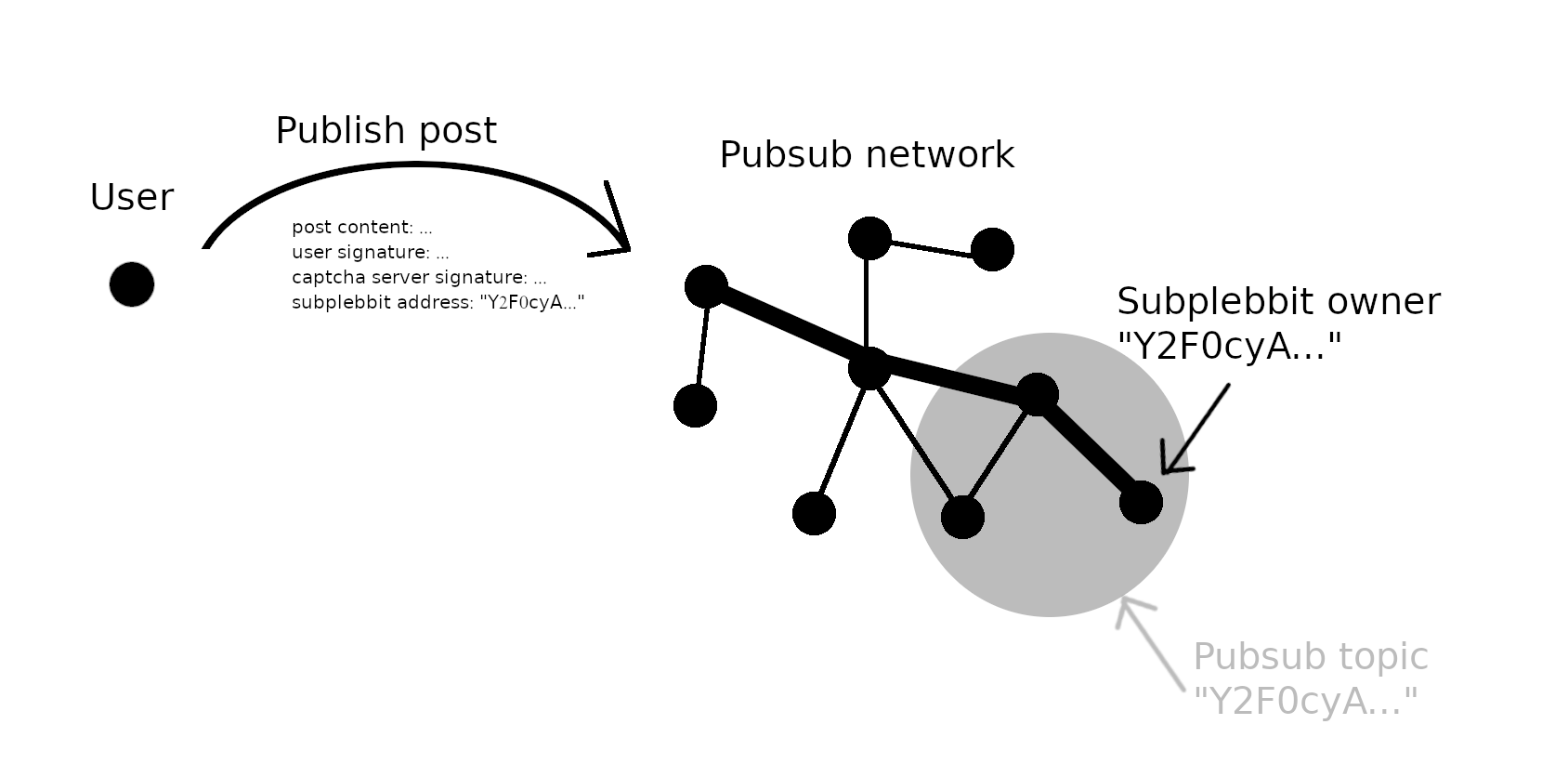
- He publishes a cat post for a subplebbit called “Cats” with the public key “Y2F0cyA…”
- The app makes a call to “Y2F0cyA…” subplebbit’s captcha server. The captcha server optionally decides to send the user a captcha challenge. User completes it and includes the captcha server’s signature with his post.
- His client joins the pubsub network for “Y2F0cyA…” and publishes his post.
- The subplebbit owner’s client gets notified that the user published to his pubsub, the post is not ignored because it contains his valid captcha server signature.
- The subplebbit owner’s client updates the content of his subplebbit’s public key based addressing automatically.
- A few minutes later, each user reading the subplebbit receives the update in their app.
- If the user’s post violates the subplebbit’s rules, a moderator can delete it, using a similar process the user used to publish.
Note: Browser users cannot join peer-to-peer networks directly, but they can use an HTTP provider or gateway that relays data for them. This service can exist for free without users having to do or pay anything.
What is a “post”
Post content is not retrieved directly by querying a subplebbit’s public key. What is retrieved is list of “content based addressing” fields. Example: latest post: “bGF0ZXN0…”, metadata: “bWV0YWRhdGE…”. The client will then perform a DHT query to retrieve the content. At least one peer should have the data: the subplebbit’s owner client node. If a subplebbit is popular, many other peers will have it and the load will be distributed, like on Bittorrent.
Peer-to-peer pubsub scalability
A peer-to-peer pubsub network is susceptible to spam and does not scale well. Pubsub peers who spam messages without a valid captcha server signature can be blacklisted. And captcha server urls can be behind DDOS protection services like Cloudflare, so it should be possible for subplebbit owners to resist spam attacks without too much difficulty.
Captcha server lifecycle
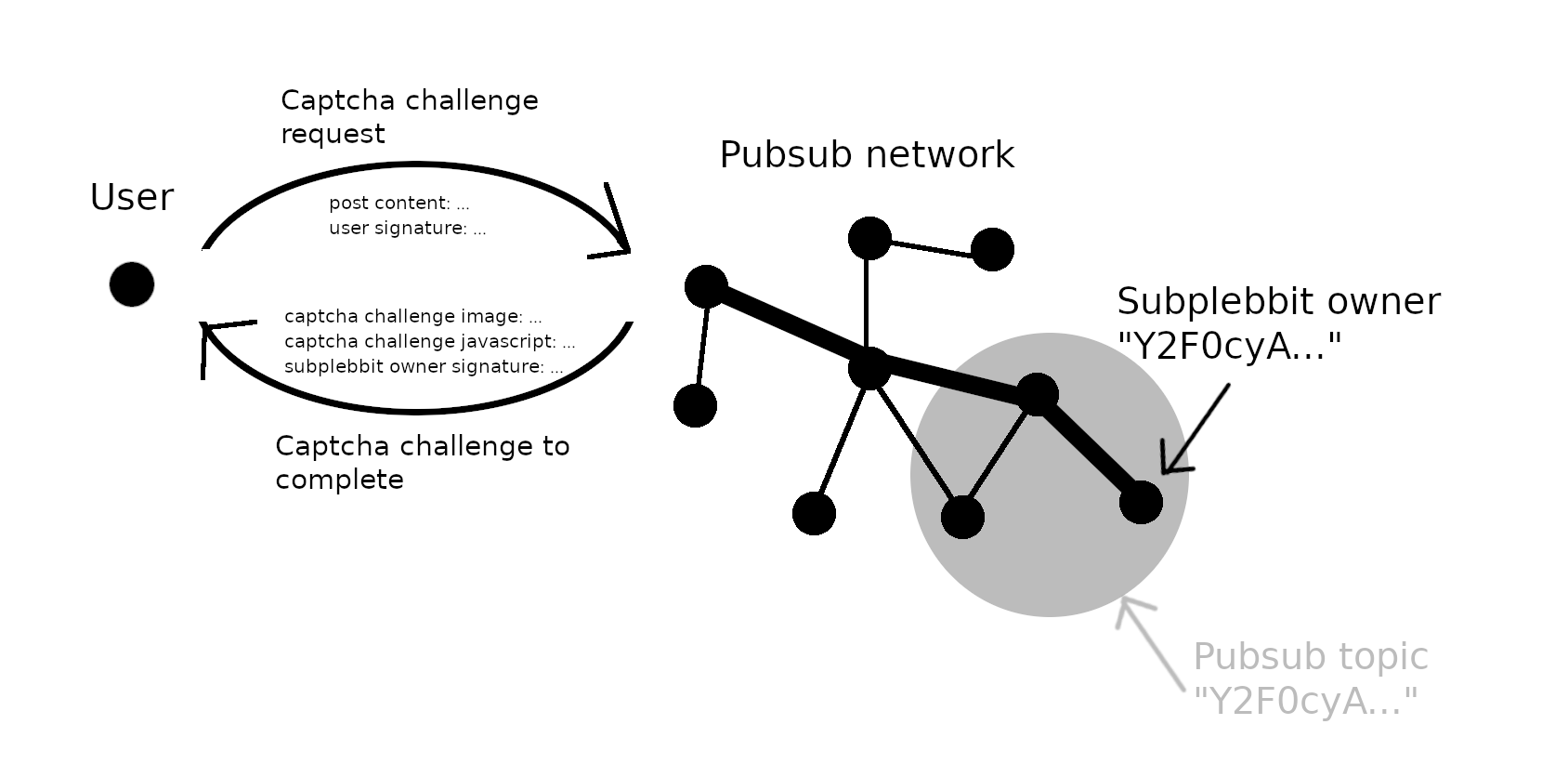
- The app loads the captcha server URL in an iframe before publishing a post. This URL is operated by each subplebbit owner individually.
- The server sends a visual or audio challenge and it appears inside the iframe.
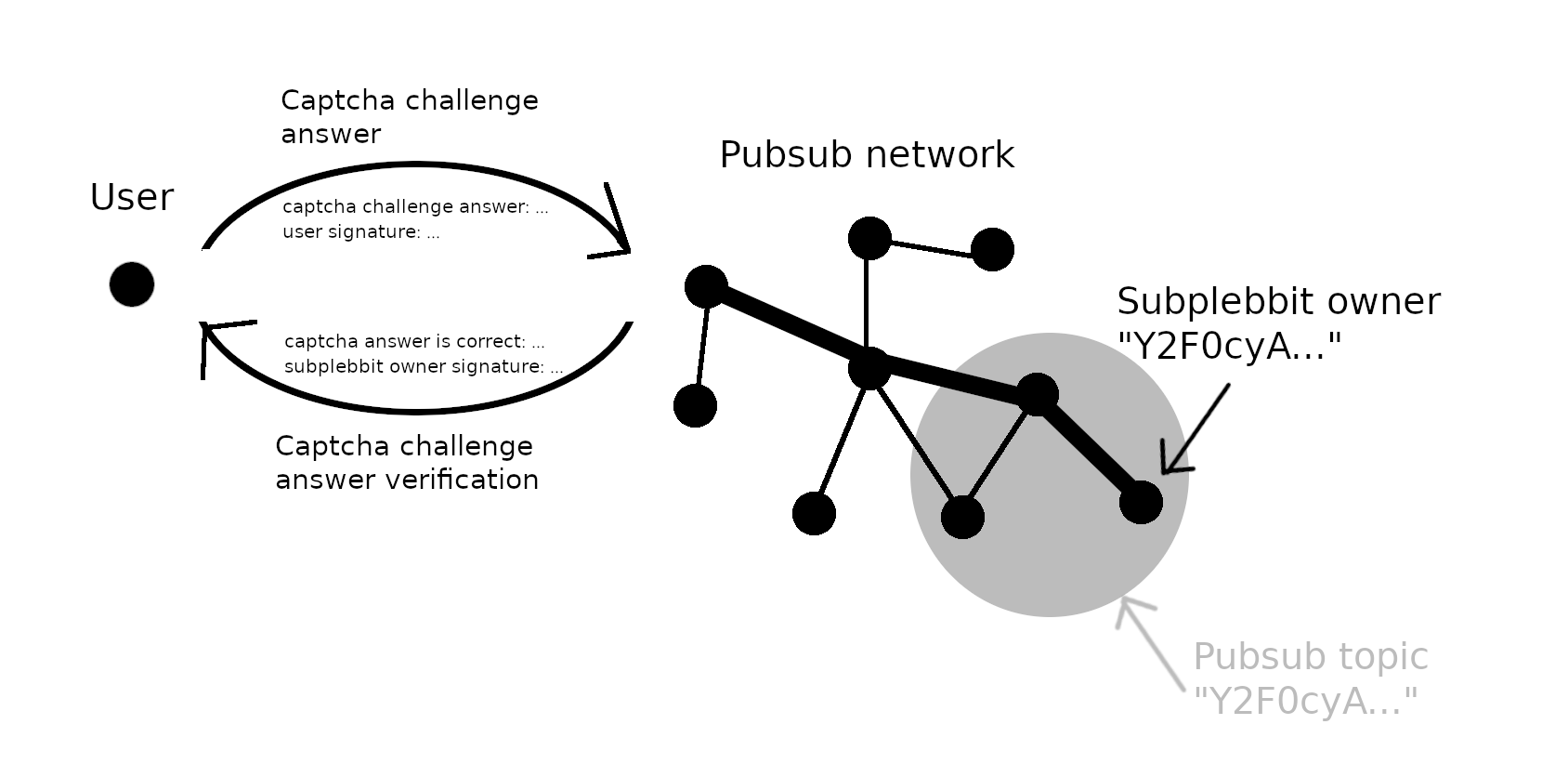
- The user completes the challenge and sends his answer back to the server.
- If the challenge answer is correct, the server sends back a digital signature for the post.
- The user can now include this signature with his post, and when the subplebbit owner encounters that post in the pubsub network, he knows it is not spam.
Conclusion
We believe that the design above would solve the problems of a serverless, adminless decentralized Reddit alternative. It would allow unlimited amounts of subplebbits, users, posts, comments and votes. This is achieved by not caring about the order or availability of old data. It would allow users to post for free using an identical Reddit interface. It would allow subplebbit owners to moderate spam semi-automatically using their own captcha server implementations. It would allow for all features that make Reddit addictive: upvotes, replies, notifications, awards, and a chance to make the “front page”. Finally, it would allow the Plebbit client developers to serve an unlimited amount of users, without any server, legal, advertising or moderation infrastructure.