TL;DR
Small-scale Rollups with low L2 data throughput face a cost-delay tradeoff under EIP-4844’s 128KB blob design: either tolerate inefficient blob utilization or endure prolonged submission delays to accumulate sufficient data.
Existing solutions such as Blob Sharing and Blob Aggregation address some of these problems but introduce complexities in cost distribution, incentive mechanisms, and potential delays.
We propose a dynamic Blob sizing solution where the Blob length is no longer fixed, allowing users to pay only for the actual space they use without waiting to accumulate enough data.
Introduction
The advent of rollups has significantly enhanced Ethereum’s scalability by offloading transaction execution while retaining data availability (DA) on-chain. With the implementation of EIP-4844, blobs have emerged as a critical component for rollups to submit compressed transaction data.
Under the current protocol design, Rollups are required to pay for an entire blob, even if their data only occupies a fraction of its capacity. This rigid pricing model leads to inefficient resource allocation, as underutilized blobs drive up per-byte costs—a problem that worsens as the network scales. The fixed 128 KB blob size particularly creates systemic inefficiencies for small Rollups, which typically have low transaction throughput. These Rollups face a persistent dilemma: either pay for underused blob space, resulting in prohibitively high per-byte costs, or delay data submissions until enough data is accumulated to fill a blob, leading to unnecessary delays.
Existing ideas, such as Blob Sharing and Blob Aggregation , attempt to mitigate these inefficiencies by enabling multiple rollups to co-occupy a single blob. While these approaches improve spatial utilization, they introduce new challenges:
Cost Allocation Complexity: Designing fair payment distribution mechanisms (e.g., Shapley value or Nash Bargaining solution) often triggers game-theoretic behavior among participants, complicating cost sharing.
Misaligned Incentives: High-throughput Rollups have little economic incentive to share blobs with smaller counterparts, as their own utilization rates are already sufficiently high.
Coordination Overheads: Cross-rollup data bundling requires synchronization protocols, which introduce additional latency.
Solution
To address these limitations, we propose Dynamic Blobs, a solution that decouples blob size from fixed constraints, allowing participants to pay only for the space they actually use without the need for mandatory padding. This approach eliminates overpayment for unused blob space and removes the delays associated with data accumulation.
Assumptions
Assumption 1: At a given time t, assume that the Blob Base Fee has been dynamically adjusted to a fixed value B_{base}(t) based on the current network load, demand-supply equilibrium, and congestion state. At this point, the fee that users pay when initiating Blob transactions is directly proportional to their gas consumption.
Assumption 2: It is assumed that there is a sufficient number of honest light clients sending requests, and each sampling request is anonymous (i.e., it cannot be linked to the same client). Additionally, the distribution of sampling requests is uniformly random, and the order in which they are received by the network is also uniformly random with respect to other requests.
Detailed Mechanism
Encoding
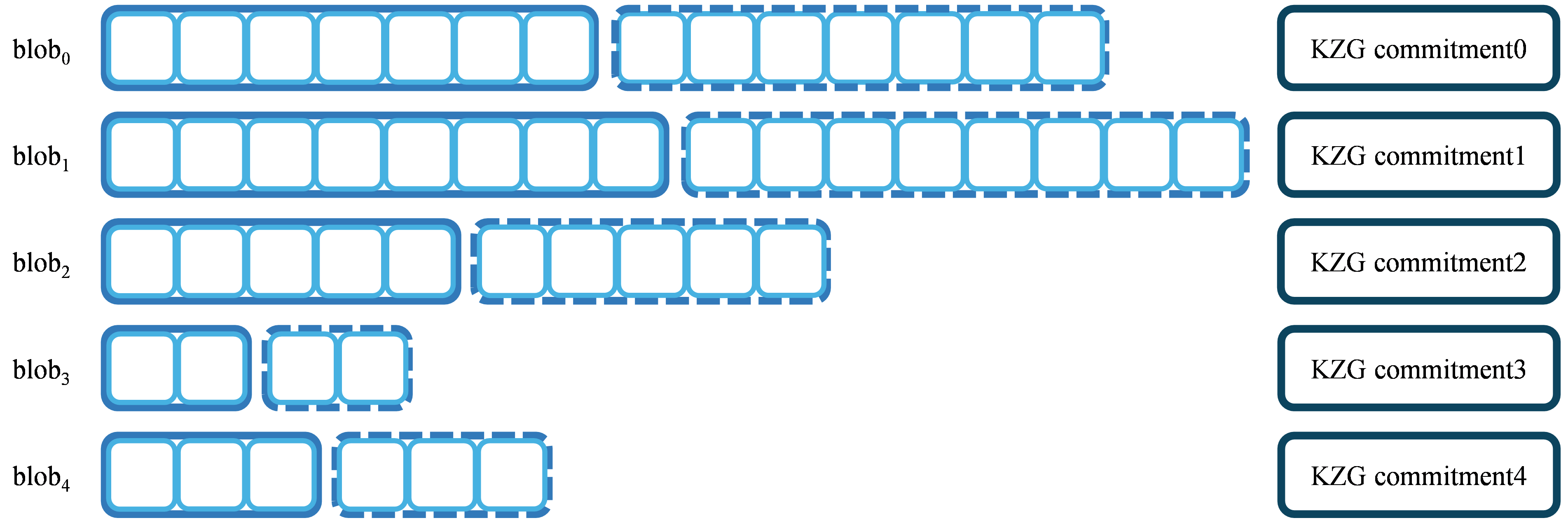
In our dynamic blob scheme, the length of each blob varies due to differences in the amount of padded data. As a result, while the chunk size per row remains consistent, the number of chunks per row differs. Each row of the blob is encoded using 1D Reed-Solomon (RS) encoding. To ensure correct encoding, KZG polynomial commitments are used to commit each row of the blob. As shown in Figure 1, solid-line boxes represent the original data blocks, while dashed-line boxes represent the encoded chunks.
DAS
In the long run, nodes should store or forward only a small portion of the block to support better scalability and accommodate weaker participants. To ensure decentralization, nodes should not bear excessive storage and forwarding tasks, as this could limit the participation of resource-constrained users. To ensure data availability, we use GossipSub for data distribution and the Req/Resp protocol for sampling. The allocation of blobs is sharded, with the number of chunks for each subnet proportionally distributed based on the blob length.
Custody
If there are J subnets, the number of chunks assigned to each subnet for the same blob may differ. To ensure load balancing, a certain number of zero values are padded to each row of the blob, ensuring that the number of chunks assigned to different subnets for the same blob remains equal.
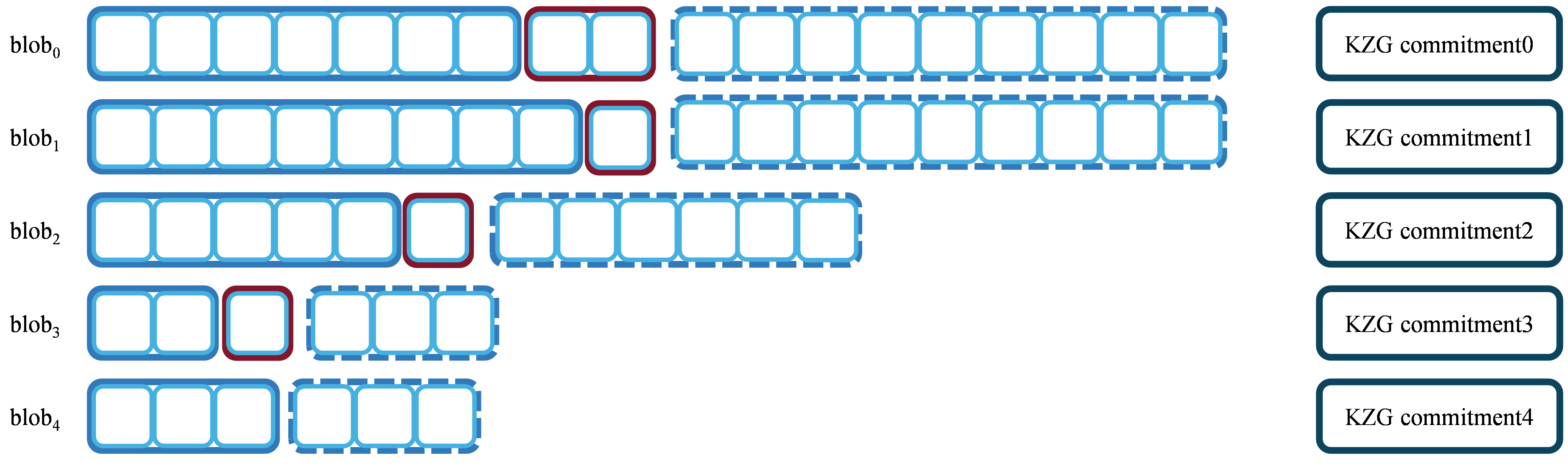
In Figure 2, the red parts in the diagram indicate the necessary zero-padding extension. This operation ensures both load balancing and equal distribution of samples. Our dynamic blob scheme does not completely eliminate the need for zero-padding, but significantly reduces the amount of zero-padding required compared to the original scheme.
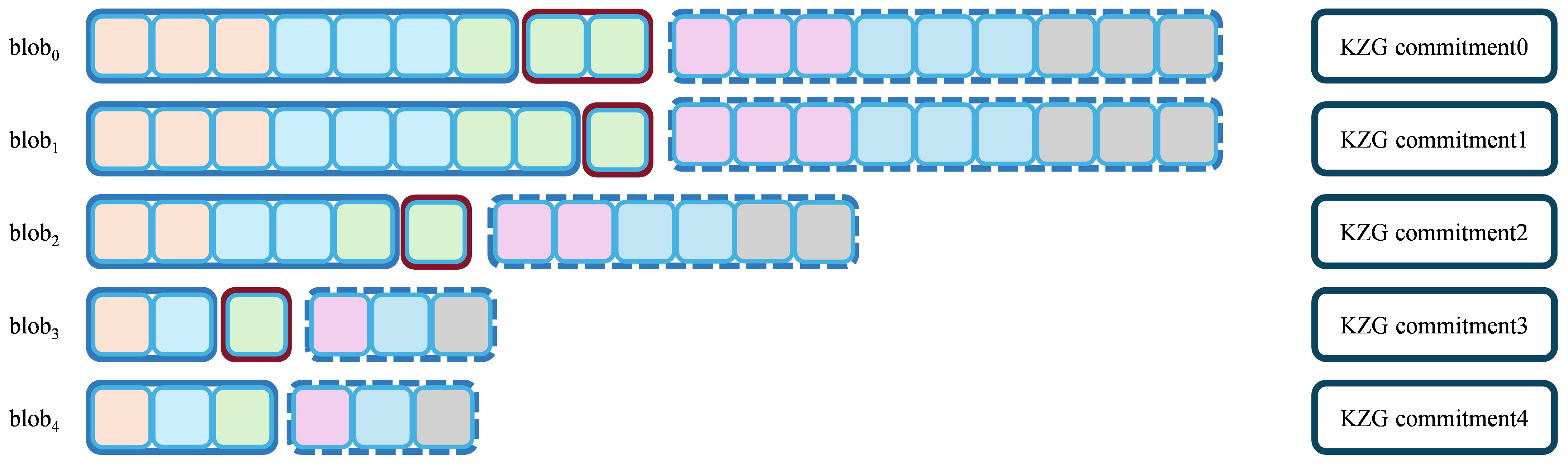
In Figure 3, chunks of the same color form a minimal sampling unit, and a subnet can contain multiple sampling units. This ensures that each blob, regardless of its size, can be sufficiently sampled by many nodes, thereby guaranteeing the reliability of data recovery. The number of subnets in Figure 3 is 6.
In Figure 3, the red areas represent the necessary zero-padding extensions. This operation ensures both load balancing and equal distribution of samples. Let n_i denote the total number of blocks in blob_i. The following expression represents the number of symbols that can be sampled from blob_i:
This formula is adapted from this paper.
The number of symbols that can be sampled from different blobs is proportional to n_i. The subnet count is denoted as J, and for blob_i, the number of symbols stored by each node is given by:
The j-th subnet stores blocks with indices in the range
In a sense, this method achieves column alignment by adjusting the size of the sampled blocks. This ensures that the number of symbols sampled from each blob is proportional to the number of subnets, thereby enhancing data reliability.
When J = n_{max} and the blob corresponding to n_{max} is filled, this scheme reaches its worst-case scenario, which corresponds to 1D PeerDas.
SHPLONK can be used to merge commitments of multiple polynomials at different points, reducing the size of the proof.
Pricing
In EIP-4844, the pricing strategy for Blob transactions is proposed as follows:
Here, \text{GAS_PER_BLOB} is a constant, meaning that each Blob (regardless of whether it is fully filled) consumes a fixed amount of Blob Gas.
The pricing strategy proposed in this paper: Based on the EIP-1559 mechanism, the Blob Base Fee dynamically adjusts according to the supply and demand of the blob. But at any given moment, this Base Fee is fixed. Users pay according to the actual Blob capacity they utilize, i.e.,
where \alpha represents the proportion of Blob capacity used by the user.
Conclusion
The dynamic Blob scheme proposed in this paper decouples data capacity from rigid cost structures, enabling Rollups to achieve fine-grained cost control and latency optimization. Future research directions may explore adaptive adjustments of critical parameters (e.g., subnet count J, zero-padding rules) and investigate the feasibility of implementing two-dimensional encoding for dynamic Blobs, thereby unlocking further efficiency gains.
I would greatly appreciate any feedback, suggestions, or critiques you might have on this proposal. Your insights into the feasibility of the framework, potential improvements, or any concerns regarding its practical application are highly welcomed.
Other Resources
Potential impact of blob sharing for rollups
Blob Aggregation - Step Towards More Efficient Blobs
FullDAS: towards massive scalability with 32MB blocks and beyond
From 4844 to Danksharding: a path to scaling Ethereum DA