Special thanks to Augusto Teixeira and Pedro Argento for reviewing this piece.
Introduction
Ethereum has just suffered the largest theft in cryptocurrency history. It was neither a protocol bug nor a smart contract flaw — everything was working as expected. It was neither a private key leak nor a wallet compromise. It was a social attack: hackers spoofed a front-end, tricking signers into inadvertently transferring $1.5 billion dollars to North Korea.

The main issue is that a transaction’s input data is a binary blob, displayed by wallets as an incomprehensible hexadecimal-encoded string. Interpreting this data requires not only that the user has context about the application and knowledge of its implementation but also substantial bit gymnastics, making the process essentially impossible.
In the Bybit hack, the input data was spoofed. Although the compromised front-end UI indicated that the transaction would execute the expected transfer, it instead stole all the funds. The wallet displayed the data correctly — it was the humans who couldn’t read it.
These signers were certainly experienced professionals with robust protective measures against such attacks. That they were fooled signals that Ethereum’s transaction signing process is currently broken. This is not a new assertion — these signing issues have been known for a while. If we don’t address this readability problem, I believe we will see more hacks like the Bybit incident in the future.
In this post, we outline a possible technique to address these issues. Rather than being a protocol-level solution, this approach operates at the application level and must be implemented individually by each application’s developers. We assume that while the front-end is untrusted, the wallet and smart contracts with which the user interacts are trusted.
First attempt
EIP-712 introduced a new typed data signing standard that leverages Ethereum keys to generate signatures that are both machine-verifiable and human-readable. For more details on its design, see this 2018 thread.
One of the goals of EIP-712 is to transform the signing experience from one where users blindly approve transactions into one where they can clearly verify the details — turning the left-side experience into the right-side one:
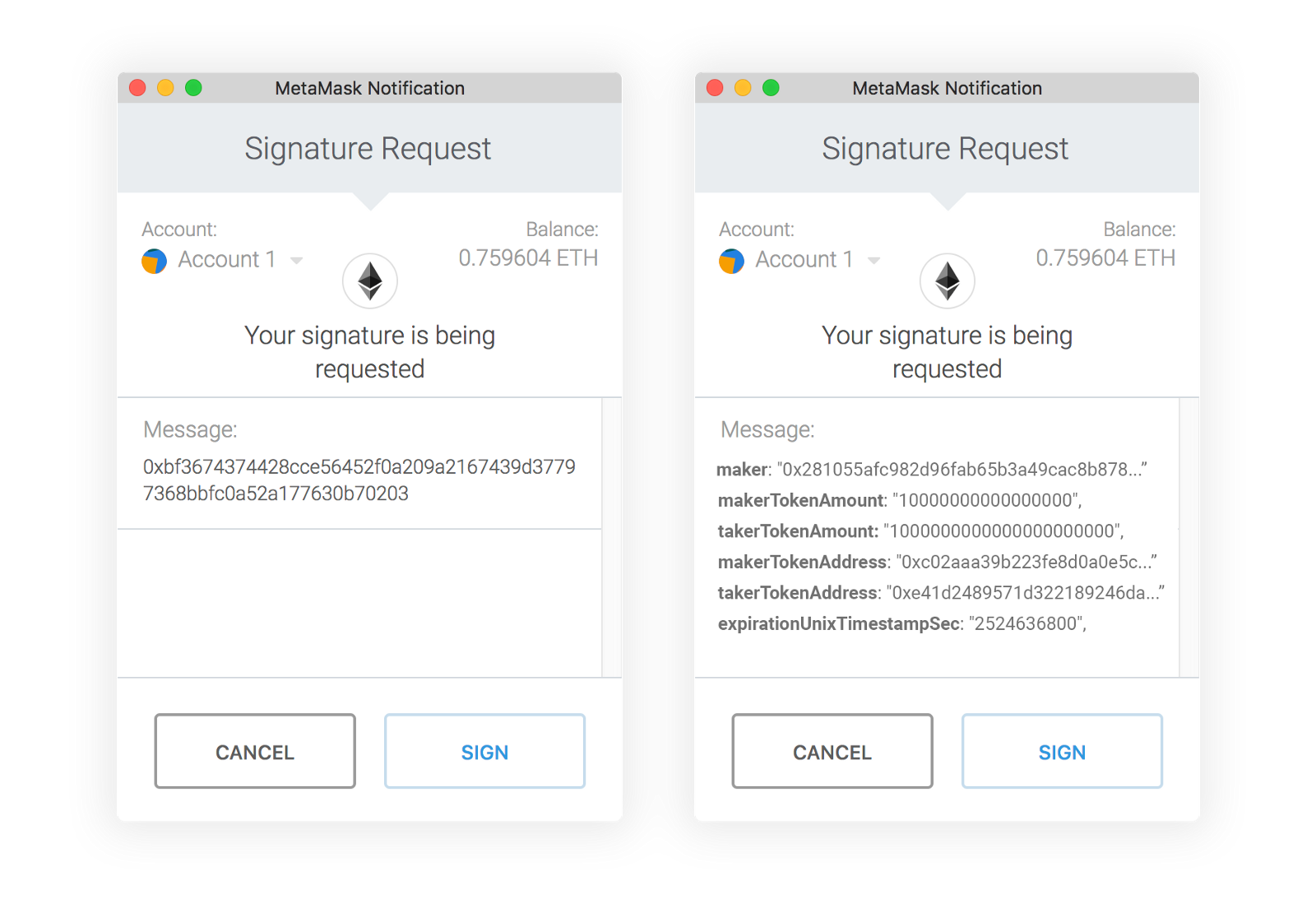
This enables applications to define message schemas with fields that are understandable by humans — a significant improvement over blind signing. However, even with this improvement, the signing process can still be overwhelming. See the image below: it shows a hardware wallet asking the user to verify the 54th field while signing a Gnosis Safe transaction — and that’s not even the last one. No one is realistically going to verify every single field.

The consequence is effectively the same as blind signing, which ultimately caused the Bybit hack.
Proposal
The key idea is to embed an enforceable, human-readable description within the signed message, thereby preventing users from inadvertently signing transactions with unwanted side effects. The goal is to achieve this enforceable description without incurring prohibitive data availability overhead.
Consider an application that uses EIP-712 messages as input. These messages may contain an excessive number of fields — some with arcane names and inscrutable hexadecimal-encoded binary data. Ultimately, an EIP-712 message is intended for programs, not humans. While users can’t be expected to understand the entire message, the target application can understand it perfectly.
For each application, it is therefore possible to implement a pure function that maps the human-unreadable message into a human-readable string. For example, while a Gnosis Safe transaction is internally represented as a cumbersome 54-item tuple — necessary for the application — it is far too detailed for a user. A well-designed decoder can transform this tuple into a description that is both more concise and more informative for humans. Because decoders are application-specific, each application must implement its own canonical decoder and integrate it into its smart contracts, making it accessible both externally and internally.
Finally, we extend the message schema by adding a new text field — the description — to store the human-readable output produced by a canonical decoder. This field is intended for humans, clearly describing in plain language what the transaction will do once executed.
The outline of the technique is as follows:
- Before sending the EIP-712 message to the user’s wallet for signing, the UI queries the application’s canonical decoder and populates the description field with the corresponding human-readable string. Note: Since the UI is untrusted, it may potentially set the description incorrectly (e.g. the description says something innocuous, but the input data steals all the funds);
- The wallet, which is trusted, receives the message for signing and displays both the incomprehensible input data and its human-readable description. The user reads the description and decides whether or not to sign the message;
- The user signs the message, which includes both the incomprehensible input data and its alleged description;
- The front-end compresses the message by removing the description field and submits the compressed message to Ethereum. (Alternatively, the front-end sends the message to a sequencer.) The key insight is that data availability for the human-readable description is unnecessary since the smart contract can recover it from the raw input data using the same decoder;
- Finally, the application receives the signed message and uses its canonical decoder to recover the correct description for the message. It then verifies whether the pair message and signature is correct. If the description is incorrect, the signature verification will fail, and the application will refuse to process the transaction.
Discussion
By signing both the message and its human-readable description, we can later verify that they match and reject any transaction where they do not. This creates a cryptographic guarantee that makes it impossible to spoof a transaction. Moreover, since the mapping from message to its description is implemented as a pure function, the description itself does not need to be included in data availability.
This technique is possible because it is specialized for each application. This specialization allows developers — whom we assume are trusted and who have deep knowledge of their own systems — to address the issue at the application level. As a result, no Ethereum protocol changes are required.
Although the approach does not incur extra data availability costs, it does introduce additional computational overhead per transaction. This overhead might be prohibitive for certain applications, particularly those on Layer 1. In contrast, L2s are a better fit given their greater blockspace — especially application-specific rollups, which offer even more blockspace per application. My intuition is that the extra processing cost will be minor, and certainly preferable to losing $1.5 billion.
One downside of this technique is that it requires two signatures: one for the application and another for Ethereum. In other words, the user must sign an EIP-712 message (including the human-readable description) and then sign a separate transaction to submit that message to Ethereum. The upcoming Pectra fork may help address this issue through account abstraction, allowing someone else to submit a transaction on the user’s behalf so that only one signature is needed by the user. Alternatively, in non-EVM rollups that could already use an EIP-712 message as their transaction schema, users would only need to sign once before sending the message to a sequencer. Finally, while string manipulation in Solidity can be quite cumbersome, rollups with more robust execution environments offer promising ways to mitigate this challenge.
We believe this technique is an excellent fit for implementation on a Cartesi application-specific rollup. An application hosted on a Cartesi rollup benefits from dedicated blockspace. This extra blockspace helps mitigate the additional computational overhead introduced by our proposed technique. Additionally, a Cartesi rollup can already use EIP-712 messages as input, and string manipulation is much easier in this environment.
Conclusion
By adopting this technique, applications eliminate the need for users to delegate trust to front-ends; the Bybit signers would have either seen a sketchy description and refuse to sign, or received an innocuous description that would ultimately be rejected by the application.
As Alfred North Whitehead observed, “civilization advances by extending the number of important operations which we can perform without thinking about them.” In this context, users no longer need to perform complex bit gymnastics or worry about the trustworthiness of front-ends. Instead, they can benefit from what Josh Stark describes as a hard cast.