Written by Jonas & Naman from Chainbound.
This research was funded by the Robust Incentives Group at the Ethereum Foundation. This work is specifically related to ROP-8. Additional information can be found here. We want to thank soispoke, the EF DevOps team, MigaLabs and ProbeLab for their advice and contributions!
Table of Contents
- Introduction
- Anatomy of a validator
- Attestation duties and committees
- Attestation subnets
- Validator footprints
- Methodology
- Architecture
- Result
- Limitations
- References
Introduction
The geographical distribution of a validator set is one of the most critical factors in determining a blockchain’s level of decentralization. Validator decentralization is vital for Ethereum. It enhances network security, resilience, and censorship resistance by distributing control and minimizing the risk of single points of failure or malicious attacks.
It is well known that Ethereum has a very large validator set, but is this validator set geographically distributed? Ethereum has a substantial amount of beacon nodes running on the consensus layer network, with current estimates at around ~12,000 active nodes (source). A beacon node serves as a potential entrypoint into the network for validators, but it is not representative of the actual validator distribution.

Probably not.
In this article, we present the methodology and results of an investigation aiming to address this question. We start with some context about the logical components making up a validator, then proceed with some potential methods of identifying validators on the beacon P2P network. We then expand on our chosen methodology and finally present the results.
Anatomy of a validator
An Ethereum validator is a virtual entity that consists of a balance, public key and other properties on the beacon chain. They are roughly responsible for 4 things:
- Proposing new blocks
- Voting on other block proposals (attesting)
- Aggregating attestations
- Slashing other validators in case they commit faults
A validator client is the piece of software that executes these responsibilities for each of its registered validator keys (which can be many). But a validator client on its own cannot connect to the P2P beacon network to talk directly to other validators. Instead, it connects to an entity known as a beacon node, which is a standalone client that maintains the beacon chain and communicates with other beacon nodes.
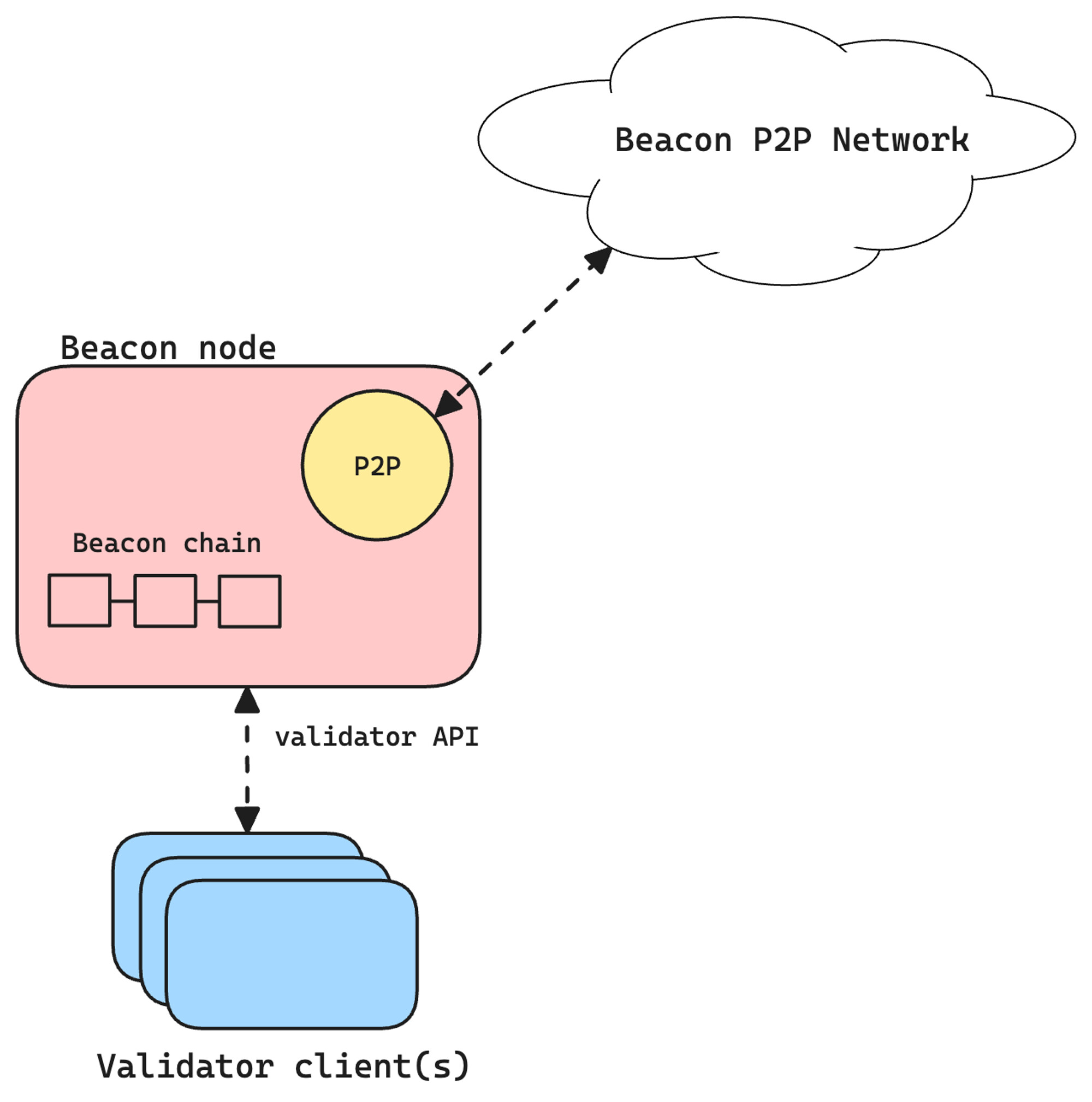
Schematic of validator clients and a beacon node
Beacon nodes can have a number of validators attached to them that ranges from zero to thousands. In fact, it’s been reported that in some Ethereum testnets client developers have been running upwards of 50k validators on a single machine. This separation of concerns makes our investigation somewhat harder: a simple crawl of the P2P network might give us a good overview of the set of online beacon nodes in real time, but this is not representative of the overall validator client distribution at all. Before we address this problem, we’ll take a closer look at validator duties and their footprint on the network.
Attestation duties and committees
As mentioned above, one of the main responsibilities of a validator is voting on blocks by broadcasting attestations. These attestations express the view of a validator about which chain they think is correct. In more detail, they actually cast 2 different votes: one to express their view of the current head block, and one to help finalize past blocks. This is because Ethereum’s consensus is a combination of 2 subprotocols: LMD GHOST, a fork-choice rule, and a finality gadget called Casper FFG.
These duties are assigned randomly every epoch (with some lookahead) with RANDAO as the source of randomness. Validators get assigned to one slot per epoch at which they have to cast their attestation, which is just a message with the votes that is signed over with the validator BLS private key. These votes are then to be packed and stored in the next beacon block. However, if all 1 million validators were to attest for every block, the network would be flooded with messages, and the proposer that is supposed to pack these attestations into their block would have trouble verifying all of those signatures in time. This would make Ethereum’s design goal of low resource validation unfeasible.
To address these issues, the beacon network is subdivided into committees, which are subsets of the active validator set that distribute the overall workload. Committees have a minimum size of 128 validators, and there are 64 committees that are assigned per slot. But how is this achieved in practice? What network primitives do we require to enable such a logical separation?
Attestation subnets
The Ethereum consensus P2P network is built with GossipSub, a scalable pubsub protocol running on libp2p. Being a pubsub protocol, GossipSub supports publish/subscribe patterns and the segmentation of networks into logical components called topics (aka P2P overlays). These are the networking primitives that underpin beacon committees.
One example of a topic is the beacon_block topic, which is a global topic on which new beacon blocks are broadcast. Every validator must subscribe to this topic in order to update their local view of the chain and perform their duties.
The attestation overlays look quite a bit different. For each committee, we derive a subnet ID based on the committee index (0-64). The topic for the respective subnets then becomes beacon_attestation_{subnet_id}. Every validator knows their upcoming attestation duties at least 1 epoch ahead of time and can join the correct subnet in advance. When they have to make an attestation, they broadcast it on this subnet.
As mentioned before, these attestations are eventually supposed to make it into a beacon block. But since upcoming proposers might not be subscribed to these subnets, how does that work? This is where attestation aggregators come in. These are a subset of the beacon committees that are responsible for aggregating all of the attestations they see and broadcasting the aggregate attestations on the global beacon_aggregate_and_proof topic. This topic is again a mandatory global topic that all validators will be subscribed to, thus providing a way for local unaggregated attestations to make it into the global view of the network. Per committee, there’s a target number of aggregators of 16.
Subnet types
These attestation subnets described above are ephemeral and directly tied to the validator duties. We call these short-lived attestation subnets. The problem with these ephemeral subnets is that they are not very robust, and could result in lost messages. To deal with this issue, the notion of a “subnet backbone” was introduced.
This backbone consists of long-lived, persistent subnet subscriptions that are not tied to validator duties but rather a deterministic function of the beacon node’s unique ID and the current epoch. These long-lived subnets are maintained for 256 epochs, or around 27 hours, and each beacon node has to subscribe to 2 of them. They are also advertised on the discovery layer, making it easier for beacon nodes with certain duties to find peers on the relevant subnets.
Validator footprints
Returning to the separation of the beacon node and validator clients, there’s now a clear footprint that validators leave on the beacon node’s network identity: their short-lived subnet subscriptions. This will be the core of our methodology.
Methodology
Generally, the beacon network consists of 3 domains:
- The discovery domain
- The Req/Resp domain
- The gossip domain
Each of these domains provides some information about a beacon node.
Long-lived subnets & node metadata
At the discovery layer (discv5), a beacon node’s identity consists of an ENR with some additional metadata. This metadata can roughly be represented as the following object:
{
peer_id,
ip,
tcp_port,
udp_port,
attnets, // Important
fork_digest,
next_fork_version,
next_fork_epoch
}
This metadata helps other peers connect to peers that are relevant to them, indeed, one of the extra metadata fields are the (long-lived) attestation subnets that this node is subscribed to!
The Req/Resp domain is where the actual handshake happens. This is where nodes exchange Status messages that look like the following in order to establish a connection:
(
fork_digest: ForkDigest
finalized_root: Root
finalized_epoch: Epoch
head_root: Root
head_slot: Slot
)
The underlying protocol used for the Req/Resp domain is (again) libp2p. On the lower levels, additional information like client_version is also exchanged when connections are set up.
It is at this level that peers can also exchange MetaData objects to identify each other’s most up to date long-lived subnet subscriptions. The MetaData object looks like this:
(
seq_number: uint64
attnets: Bitvector[ATTESTATION_SUBNET_COUNT]
...
)
Short-lived subnets
So far, we’ve only seen how nodes exchange metadata and their long-lived subnet subscriptions, which tell us nothing about potential validators. For that, we need the short-lived subnets, which we can only collect on the gossip domain. Our initial strategy was doing just that:
- Listen to incoming topic subscription requests
- Save and index them
However, on an initial review of the data, we saw way too many beacon nodes that didn’t subscribe to any additional subnets besides their long-lived, mandatory subscriptions.
Our assumption was that in order to publish data on a gossipsub topic, one needed to be subscribed to it. It turns out that this is not the case, and many clients have different behaviour to minimize bandwidth and CPU usage. Rather than subscribing to the subnet directly, the peer finds other peers that are subscribed to the required subnet beforehand and shares the attestation with them. The subscribed peers make sure to verify and forward these attestations. Remember that in theory, only attestation aggregators need to be listening to all incoming attestations in order to do their jobs. This is exactly what was happening, and explains why we had so little short-lived subnet observations.
With this understanding, we could now tune our assumptions:
- For each subnet, there’s a target of
TARGET_AGGREGATORS_PER_COMMITTEE=16aggregators per committee - This means that on average, there will only be 16 validators per committee that will be subscribed to an additional short-lived subnet for the duration of an epoch
- This results in a maximum of 16 * 32 * 64 = 32768 useful observations per epoch
With these assumptions in mind, we can start estimating validator counts.
Estimating validator counts
For each observation, we subtract the number of long-lived subnets S_l from all subscribed subnets S_{all} to arrive at the number of short-lived subnets S_s:
Since we know aggregators are subscribed to one additional subnet per epoch, S_s will result in an estimated validator count for a certain beacon node in this epoch. Note that just one observation will not be enough to get an accurate estimate, because of the following reasons:
- It could be that a validator is not an aggregator for this epoch, and thus won’t subscribe to any subnets
- There could be overlap between the long-lived and short-lived subnets
Due to this reason, we continuously try to collect observations for each known beacon node per epoch, and save the maximum estimated validator counts. Note also that the ceiling for validator estimations is at 64 - 2, because that’s the maximum amount of short-lived subnets we can record. This is important! It means that for beacon nodes with more than 62 validators, we can not estimate how many there are, and just record the ceiling. We want to highlight again that this is just an estimation and won’t be a very accurate representation of the total number of validators.
Architecture
In this section we’ll dive a bit deeper into the architecture. All the code for this is open source and can be found in this repository: GitHub - chainbound/valtrack: An Ethereum validator crawler. A lot of the crawler code is based on projects like Hermes and Armiarma. An overview can be seen here:
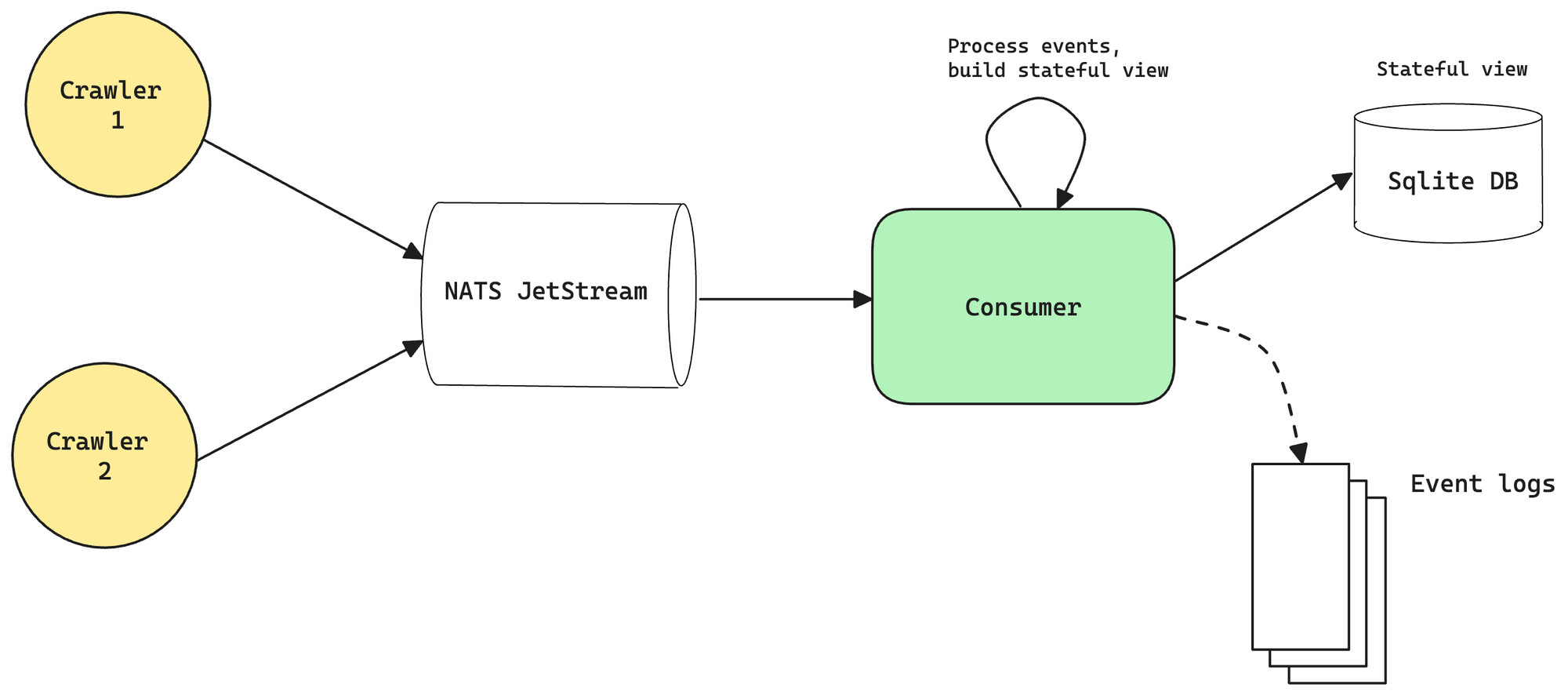
Crawler
The crawler is the core component of the system. It will crawl the discv5 discovery DHT, find nodes that are on the correct network by looking at the metadata in their ENRs, and then try to connect with them. It will keep a local cache of known peers and try to reconnect every epoch to get updated observations.
We outline 2 types of events (observations): PeerDiscoveryEvent and MetadataReceivedEvent. The second one is most relevant and contains the following fields:
type MetadataReceivedEvent struct {
ENR string `json:"enr"`
ID string `json:"id"`
Multiaddr string `json:"multiaddr"`
Epoch int `json:"epoch"`
MetaData *eth.MetaDataV1 `json:"metadata"`
SubscribedSubnets []int64 `json:"subscribed_subnets"`
ClientVersion string `json:"client_version"`
CrawlerID string `json:"crawler_id"`
CrawlerLoc string `json:"crawler_location"`
Timestamp int64 `json:"timestamp"` // Timestamp in UNIX milliseconds
}
Along with some metadata, this contains all of the fields required to apply the previously described methodology: SubscribedSubnets contains the actually subscribed subnets, obtained by listening on the GossipSub domain, and MetaData contains the peer’s long-lived subnets.
All of these events are then sent to a persistent message queue, where they are stored until they’re read by the consumer.
Consumer
The consumer turns the event logs into a stateful view of the network by implementing the methodology described above. It parses the short-lived subnets from the metadata events to get the estimated validator counts, and updates any existing entries in its stateful view. This stateful view is saved in a local sqlite database, which we expose over an API. The table schema roughly looks like this:
validator_tracker (
peer_id TEXT PRIMARY KEY,
enr TEXT,
multiaddr TEXT,
ip TEXT,
port INTEGER,
last_seen INTEGER,
last_epoch INTEGER,
client_version TEXT,
possible_validator BOOLEAN,
max_validator_count INTEGER,
num_observations INTEGER,
hostname TEXT,
city TEXT,
region TEXT,
country TEXT,
latitude REAL,
longitude REAL,
postal_code TEXT,
asn TEXT,
asn_organization TEXT,
asn_type TEXT
)
We then join this data together with an IP location dataset to provide more information about geographical distribution.
Results
Chainbound runs a GitHub - chainbound/valtrack: An Ethereum validator crawler deployment that pushes all data to Dune every 24 hours.
Dune table link: https://dune.com/data/dune.rig_ef.validator_metadata.
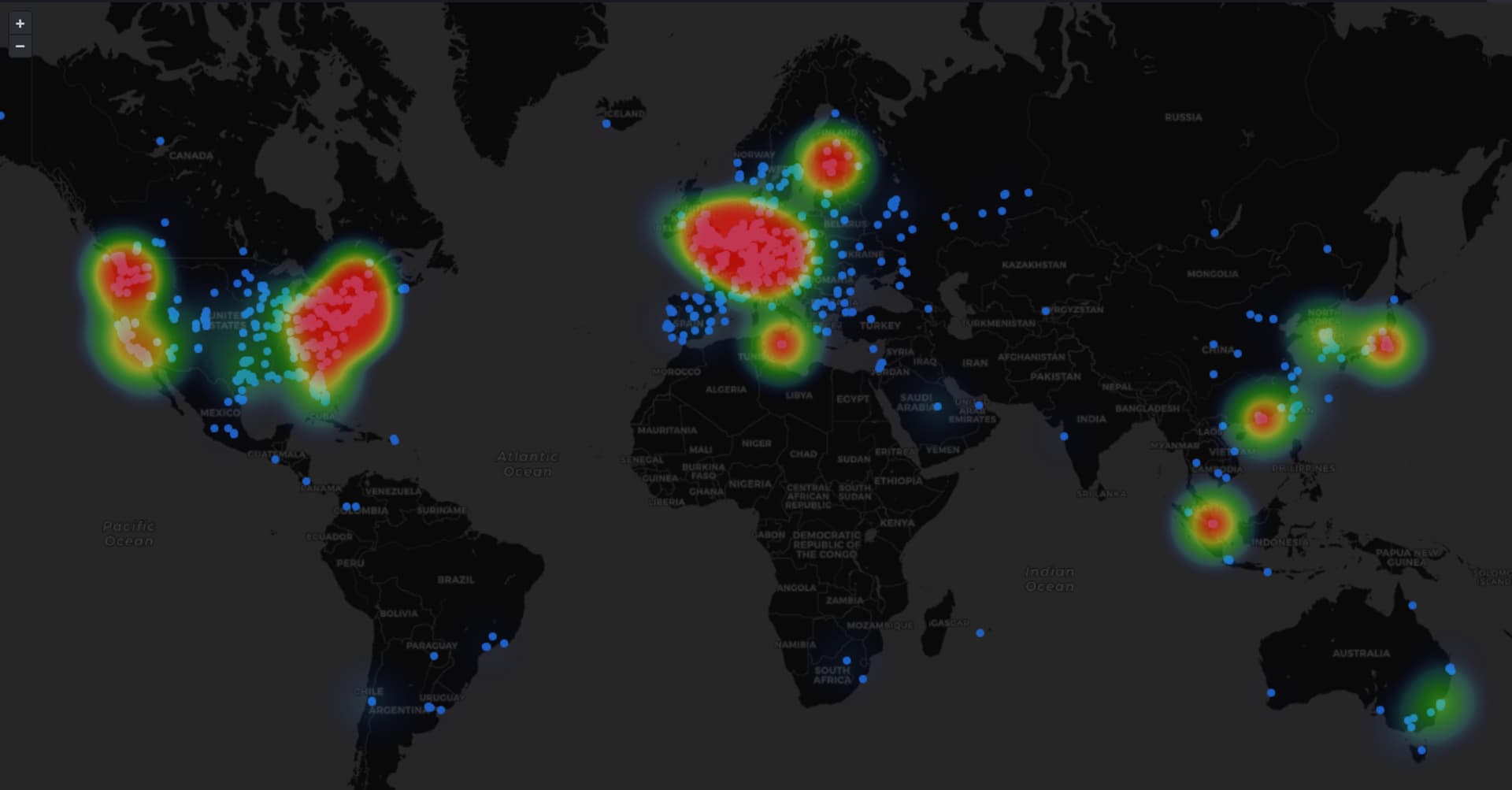
This data has been stripped of sensitive information such as IP addresses and exact coordinates. However, it retains information like city, coordinates with a precision of a 10km radius, and ASN information.
An example dashboard leveraging this information can be seen here.
We also store the individual event logs, like PeerDiscoveryEvent and MetadataReceivedEvent. These are available on demand by sending an email to admin@chainbound.io.
Limitations
- The maximum number of validators we can estimate with this methodology per beacon node is 62, due to that being the maximum amount of short-lived subnet subscriptions. This will result in a significantly underreported total number of validators, but should still be able to provide a reasonable estimation of the geographical distribution.
- We failed to gather any meaningful data on Teku nodes over the 30-day period, which could signify an error in our P2P implementation and impact the results.
- These results will be skewed towards validators attached to beacon nodes that have opened P2P networking ports in their firewall, which will mostly be beacon nodes running on cloud providers. The reason for this is that our crawler can more easily connect to nodes that have exposed ports.