(This is a continuation of discussions that I’ve had with many participants in the past weeks around Web3 Privacy Now and Protocol Labs’ “Cypherpunk Retreat”.)
The issue
Right now, if a wallet or app queries eth_getLogs from a production Ethereum client, there’s a real chance it will silently miss events. The result is simple and devastating: balances don’t add up, transaction histories show funds being spent before they are ever received, and applications cannot give users a trustworthy account of what happened. Consensus may still be intact, but the interface developers actually rely on is corrupted.
This is worse than a loud consensus bug, because it is a silent one. It erodes trust invisibly, makes results unreproducible across clients, and drives developers toward a few “blessed” infrastructure providers who can guarantee correct answers. That, in turn, accelerates centralization. And this is not an isolated bug: it is a symptom of a gap in Ethereum’s testing culture and in its standards around RPC behavior.
Concrete examples of this problem have been reported across at least Erigon, Nethermind, and on Gnosis Chain as well as Ethereum mainnet (1, 2, 3, 4, 5, 6, 7, 8). This is systemic.
Why eth_getLogs matters
For users, the most basic questions are “Where did my money come from?” and “Where did it go?” The RPC endpoint that answers those questions is eth_getLogs. Every serious Ethereum product depends on it. Wallets use it to display ERC-20 transfers; DeFi applications rely on it to check pool states; DEXs track liquidity with it; accounting tools reconcile balances against it; the HOPR mixnet uses it to map its payment channel topology.
Consider the case of a wallet displaying a USDC balance. A simple eth_call to the storage trie might tell the app the user holds 500 USDC. To explain that number, the app then queries all past Transfer events from the contract filtered for the user’s address. If those events are complete, the history might show +100, –23, +423 = 500. If, however, the initial deposit of +100 is silently missing, then the app is irretrievably corrupted. The transaction history no longer sums to the balance, the user seems to spend money before ever receiving any, and the application cannot resolve the inconsistency.
When correctness at the RPC boundary is optional, every product built on Ethereum inherits this brittleness.
Hive is not enough
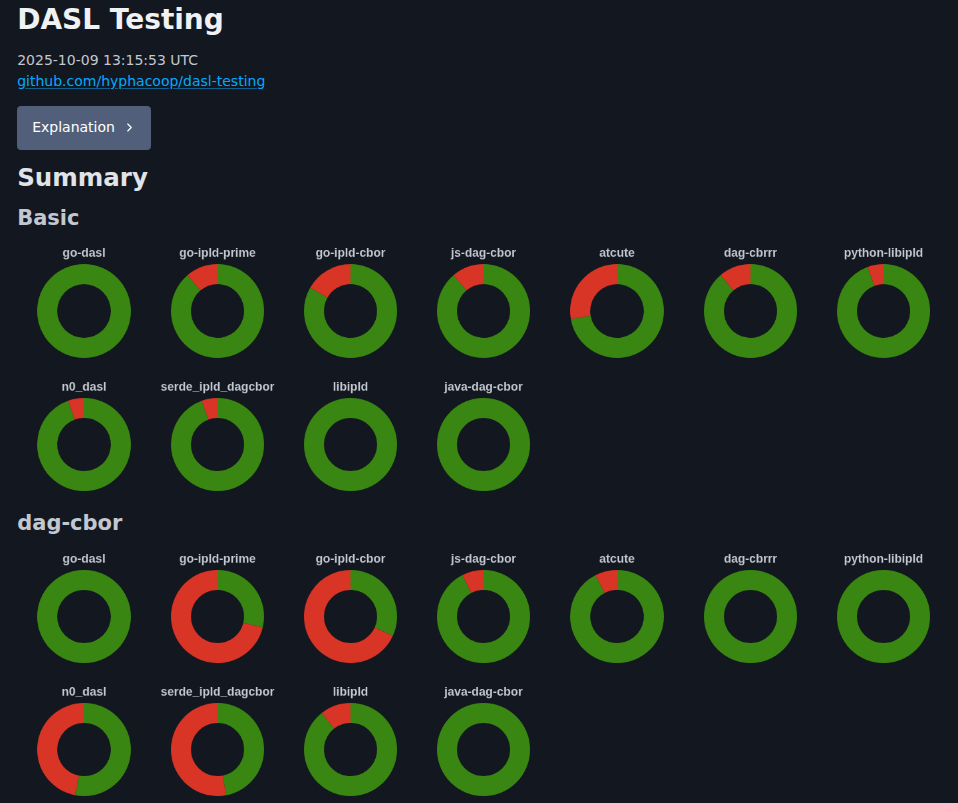
Ethereum does have Hive, the client compatibility test suite, and it is valuable. But it is scoped too narrowly and it carries no enforcement power. Out of roughly 190 RPC compatibility tests, only four cover eth_getLogs, and about half of those have been failing for months. Clients dispute the results and feel little pressure to resolve them. Passing or failing carries no consequences for release readiness or funding.
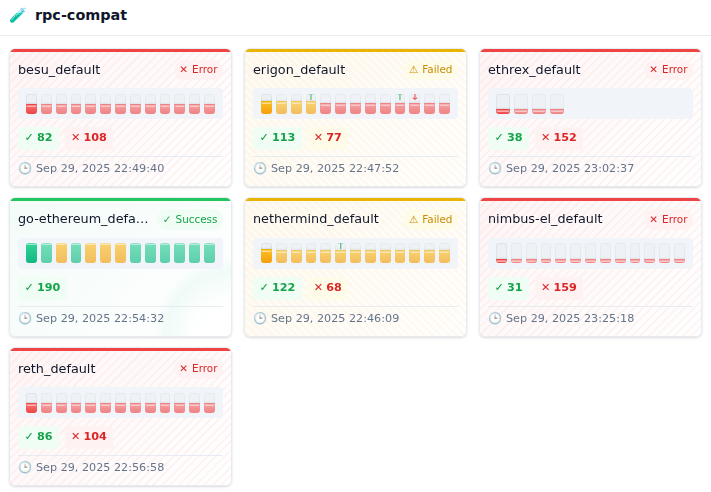
Current Hive test results show many of the 190 RPC compatibility tests failing (in red).
The contrast with the web is striking. The web-platform-tests suite now includes over two million tests across HTML, CSS, JavaScript, and APIs. Browser vendors run them in continuous integration, gate releases on them, and rely on them to settle ambiguities in specifications. If Chrome and Firefox disagreed on whether document.querySelector() returned the correct node, the modern web would collapse. Ethereum is in an analogous situation today with eth_getLogs, but without the equivalent testing culture or governance.
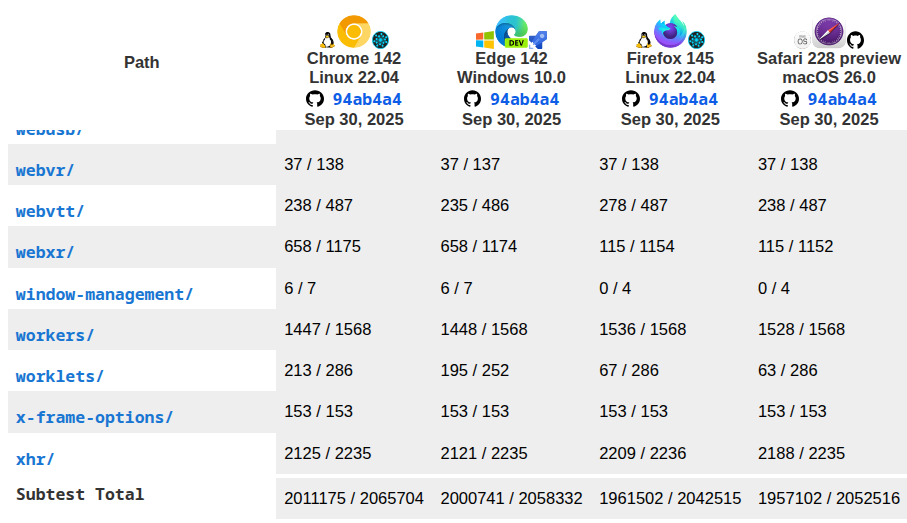
Web Platform Tests show compatibility of major browsers on over 2 million tests.
What Ethereum needs
Ethereum needs to adopt the same combination of standards and conformance that allowed the web to scale. That begins with standards. An execution-layer RPC standards and conformance group should be established, with eth_getLogs as its first focus. The group’s task would be to write normative, versioned specifications for RPC semantics, including edge cases and error handling, and to define clear processes for change management and dispute resolution.
It also requires tests, not in the hundreds but in the hundreds of thousands. We should have canonical fixtures for history-sensitive calls, large-range differential testing across clients, and continuous runs at scale. That way, missing events or nondeterministic behavior can be surfaced quickly, rather than discovered months later in production.
Finally, it requires accountability. Conformance must matter. Client releases should not go out if they consistently fail RPC tests, and Ethereum Foundation funding should be tied to meeting these standards. Public dashboards and compatibility tables should make discrepancies visible, just as they are in the browser world. When everyone can see which clients are falling behind, incentives to fix regressions change.
Conclusion
Ethereum’s credibility rests on deterministic answers at the RPC boundary. At present, correctness is optional, coverage is shallow, and divergence carries no real consequences. That is not sustainable.
The web nearly collapsed under the weight of interoperability failures, and only escaped by investing in clear standards and massive, respected test suites that vendors ran and respected. Ethereum can avoid the same fate — but only if it does the work now. Otherwise the reliability vacuum will continue to be filled by centralized API providers who monetize around correctness gaps, and the diversity of clients will cease to matter.
Ethereum needs standards-punk.