Introduction:
The Bitcoin blockchain’s initial architecture was a remarkably innovative approach to distributed consensus, but the very nature of the protocol made it operate more like a replicated state machine than a truly distributed multi-threaded system. In fact, the only non-heterogeneous and non-replicated part of the Bitcoin protocol is the proof-of-work consensus mechanism, which leverages the aggregate of the consensus throughput (hashrate) across conceptually infinite ‘consensus threads.’ The execution of the Bitcoin state machine (just a transaction validation engine) is a separate sub-process rooted in this homogeneous consensus mechanism, and is replicated across all consensus participants (miners); the state of the machine itself (the set of unspent transaction outputs) is implicitly available as it’s both needed to execute and to validate transactional throughput.
The paradigmatic separation of the process of chain consensus, execution, and data availability still exists though, just in a less-obvious form due the protocol’s architecture. Ethereum’s proof-of-stake made this separation of execution and consensus more obvious:
- Since proof-of-stake is explicit deterministic consensus, rather than proof-of-work’s implicit probabilistic consensus, there’s a clear separation between the deterministic consensus chain’s root of truth and the execution rooted therein.
- The separation is explicitly programmed in-protocol by the fact that the execution block is encapsulated by the consensus block.
- The advantages of this relationship are now becoming realized through attestor-proposer separation proposals, most notable enshrined proposer-builder separation.
The existence of the third ‘data’ layer comes not from the separation of the consensus throughput from the execution throughput, but from the increasingly multi-threaded sharded chain architecture that removes the implicit guarantees of data availability that exist in the monotheistic Nakamoto-execution model.
Homogenization through sharding
Historically, sharding architectures could be said to “split” the chain into sub-chains that are secured by subsets of validators, with a root chain that acts as a consensus lender of last resort. Innovations in zero-knowledge cryptography, however, completely changed the model: now the sub-shards can be operated by a subset of validators, but verified succinctly by all. The modern form of sharding is the rollup-centric-roadmap which resembles old-style sharding architectures with the exception that the sharded execution is not computed by in-protocol validators, but rather off-chain entities the protocol is agnostic to.
The problem is that the “zero-knowledge” part of the verification of rollups/shards’ execution inherently means that the state data being executed upon is —at least minimally— obfuscated, which removes the implied availability of that data for all. This has realized a third explicit protocol layer, the “data” layer, that can manage the availability of rollup —any maybe one day state or history— data through lightweight data blobs.
Now we have three protocol layers:
- Consensus
- Execution
- Data
Notice that the consensus layer is inherently homogeneous, as the consensus throughput is implicitly aggregated, but verifiable in constant (proof-of-work) or logarithmic (proof-of-stake) time. I make the claim that all real means of scaling aim to bring this homogenization to the execution and data layers; the goal of execution-sharding is for throughput to be relative to the aggregate resources of the network, but verifiable in —hopefully logarithmic— time, and the goal of data-sharding is for the validity of state and rollup data to be verifiable in —hopefully constant— time.
Rollups are effectively a socially-manual way of trying to mimic this effect: the operation of the rollup and thus the creation of a new thread of the world-computer is an off-chain social process where usually L1-unaligned actors seize control, whereas pure sharding architectures program the existence of the entire shard within the purview of the L1. The out-of-protocol delegated scaling of rollups can lead us to some interesting conclusions: the fact that rollups’ execution is delegated outside of the purview of the L1 means not just that the computation is off-chain, but that the specification of what computation is even occurring (what transactions are included) is happening off-chain.
The existence of the fourth “memory” layer:
The entity responsible for choosing the transactions present in rollup computation is known as a sequencer and historically they’ve been a centralized entity that retains total control over the computation, and the sole authority to decide whether or not to censor rollup users. The nature of this problem proves the existence of a protocol layer beyond the aforementioned trinity: the “memory” layer; that is, the protocol layer whereby transactions are sequenced into rollups, where memory pools are formed, where transactions are either censored or forced into inclusion lists, and where many aspects of account abstraction take place.
Arguably many of the issues that have plagued Ethereum in recent times are a direct consequence of our lack of acknowledgement of this fourth layer; MEV comes from the lack of protocol-purview on the nature of the transactions in a block and the hostile nature of the public mempool, censorship comes from builders’ sole authority over transaction inclusion, and centralized rollup sequencing comes from the lack of accountability the L1 holds rollup sequencing to. Encrypted mempools, inclusion lists, based sequencing, virtual/sharded mempools, and attestor-proposer separation are among potential solutions to these memory-layer-problems.
The endgame protocol memory layer:
Arguably the future of the protocol lies in bringing the homogenization that execution sharding and data availability sampling deploys to the memory layer: the goal should be to use virtual mempools to decentralize the sequencing of transactions into not just rollups, but mainnet itself, and to deploy mechanisms that ensure fair inclusion (and hopefully ordering and non-inclusion) of transactions into a block, along with a holistic eradication of MEV.
A sharded/virtual mempool, for example, could conceptually turn mainnet into “one big sequencer” sequencing transactions into native-rollup-like execution shards that dynamically allocate execution throughput resources to parallel computation to mimic the effect of rollups in a way that both takes advantage of enshrined inter-shard synchronous compasability across more homogeneous execution sub-shards that are interoperable in realtime, and ensures the transactions are being included in a way that precludes censorship and/or toxic MEV —or in other words is aligned with mainnet values.
Strawmap observations:
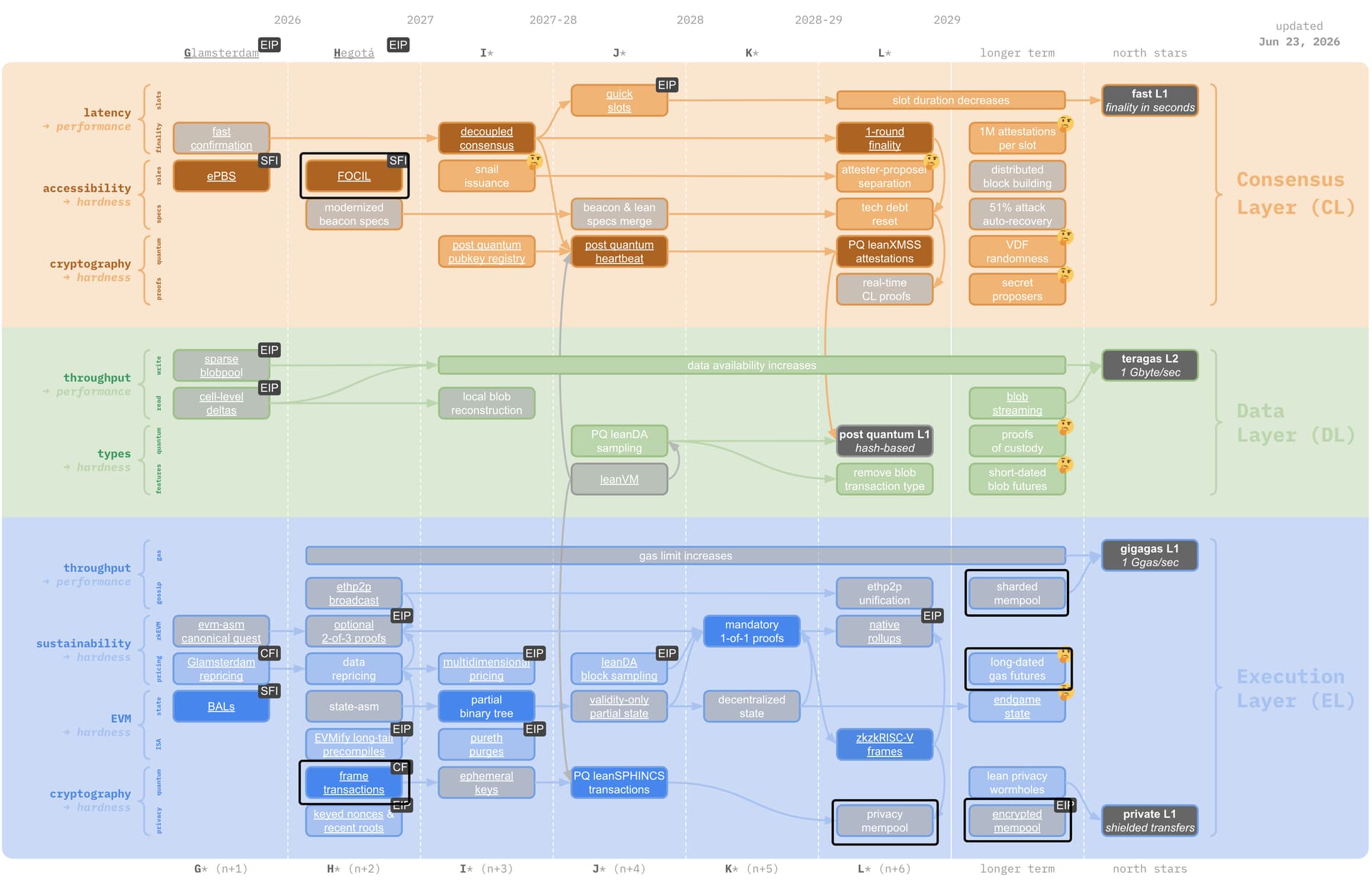
One could argue that the following strawmap items take form within the memory layer:
- FOCIL (inclusion lists)
- Sharded mempools (also based sequencing)
- Gas futures
- Frame transactions (account abstraction)
- Encrypted mempools
- Private mempools
Uniting these mechanisms into a universal “memory layer” research space that more holistically analyzes and reasons about the incentives and technical mechanisms in this area of the protocol would do us a lot of good in ensuring properties like censorship resistance, privacy, permissionlessnes and trustlessness, and decentralization are upheld; not to mention the advantages virtual mempools, based sequencing, and account abstraction bring to the protocol.
“Poison ivy has infected the infinite garden. The memory layer can help remind us of what our real values are, and what kind of CROPS we should really be planting.”