Authors: Thomas Coratger, Tom Wambsgans, Ladislaus, Thomas Thiery, Justin Drake
Credits to Benedikt Wagner and Dmitry Khovratovich for all the theoretical work, ideas, discussions and papers that have been published on eprint and that are linked in this post.
As outlined in the Strawmap roadmap, securing Ethereum against the looming threat of large-scale quantum computers is a top priority. A critical milestone in this transition is migrating our proof-of-stake consensus from BLS signatures to a post-quantum (PQ) secure signature scheme.
This post aims to explore the concepts and design space for a Post-Quantum Public Key Registry. Importantly, the actual transition will happen in phases: the Public Key Registry fork will occur first, enabling validators to register their PQ keys, followed by the actual signature switch several forks later. This gradual rollout gives the network ample time to build state, monitor for vulnerabilities, and finalize the underlying cryptographic primitives. Ultimately, the discussions generated here will mature into a formal Ethereum Improvement Proposal (EIP).
Historical Context and the Need for a Registry
In the current proof-of-stake design, validator public keys (BLS12-381) are registered via the deposit contract on the execution layer and subsequently processed by the consensus layer. BLS signatures are wonderfully efficient for aggregation, but they rely on elliptic curve cryptography, which is completely broken by Shor’s algorithm.
Transitioning to post-quantum signatures introduces significant operational difficulties for the network’s participants. Generating and securely storing these new keys requires validators to access their cold storage, execute new key generation scripts, and interact with their most sensitive cryptographic material. Because this is such a high-friction, high-stakes operational maneuver, we plan to decouple the registration of these keys from their active use in consensus. A dedicated Public Key Registry acts as a critical warmup phase, giving validators a low-pressure environment to securely manage their hardware setups and gradually commit to their post-quantum identities well in advance of the actual protocol upgrade.
Part 1: Foundations — The Cryptographic Core: eXtended Merkle Signature Scheme (XMSS)
When exploring post-quantum digital signatures, the cryptographic community generally categorizes the design space into a few main families: lattice-based, code-based, isogeny-based, multivariate, and hash-based. While solutions like lattice-based signatures (e.g., aggregating Falcon signatures via proof systems like LaBRADOR) are heavily studied, selecting secure parameters for them is highly complex, and their security proofs often rely on techniques with uncertain implications in a post-quantum setting.
Ultimately, hash-based signatures emerge as the strongest candidate for Ethereum. They stand out due to their conceptual simplicity, ease of implementation, and reliance on highly conservative, standard-model cryptographic assumptions (like basic collision and preimage resistance) rather than complex algebraic structures.
Hash-based signatures present two primary challenges: they do not natively support aggregation, and they require strict state management to prevent key reuse. While the aggregation problem must be solved separately via cryptographic proofs, the structured nature of Ethereum’s proof-of-stake consensus gives us a massive advantage for the latter: validators are required to sign exactly once per epoch.
This strict timeline allows us to bypass the significant verification overhead of fully stateless schemes (like SPHINCS+, which requires roughly 10x more hashes at verification) and instead leverage a synchronized (stateful) signature scheme. The eXtended Merkle Signature Scheme (XMSS) perfectly fits this model, tying each signature to a specific sequential position. Note that double signing under XMSS would break the key by leaking enough intermediate hash information to let an attacker forge signatures for that leaf.
How XMSS Works
To understand why XMSS is so effective, it helps to break down its construction step by step, starting from the basic properties of a hash function.
The Building Block: Hash Chains
Because cryptographic hash functions are one-way (preimage resistant), you cannot easily deduce an input from an output. A hash chain leverages this by taking a secret starting value (a private key) and hashing it repeatedly a predetermined number of times to produce a final value (the public key).
If a hash chain has 256 steps, revealing the intermediate hash at step 100 proves you know the secret, because a verifier can simply hash that value 156 more times to see if it matches the public key. This is the foundation of a One-Time Signature (OTS). To sign a message, you convert the message into a number (e.g., 100), and reveal the hash at that specific position in the chain.

Parallel Chains for Security
A single hash chain has a critical vulnerability: if you reveal the hash at position 100 to sign a message, an attacker could just hash your signature one more time to forge a signature for a message mapping to position 101.
To prevent this forgery, the scheme splits the message into multiple smaller chunks, using a parallel hash chain for each chunk, and enforces a strict mathematical constraint: a target sum. For a signature to be valid, the sum of all the chunk values (chain positions) must equal a specific, predetermined number.
Because of this constraint, if an attacker tries to forge a signature by hashing one chain forward (which increases its numerical value), the total sum of their forged signature will exceed the target. To rebalance the sum and produce a valid encoding, the attacker would be forced to decrease the value on another chain. Decreasing a value requires moving backward up the chain (reversing the hash function). Since cryptographic hash functions are strictly one-way (preimage resistant), this backward movement is computationally infeasible, rendering the W-OTS signature completely secure.
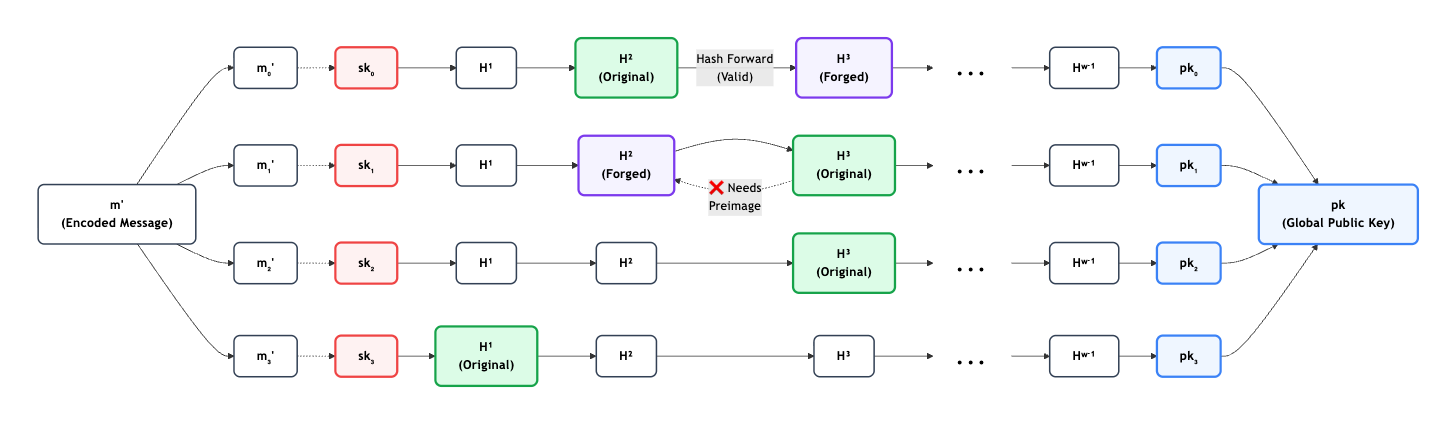
Attempted Forgery Analysis
| Signature Vector | Chain 0 (m_0') | Chain 1 (m_1') | Chain 2 (m_2') | Chain 3 (m_3') | Target Sum |
|---|---|---|---|---|---|
| 2 | 3 | 3 | 1 | 9 | |
| 3 | 3 | 1 | 9 |
Why the Attack Fails
To forge the first chain forward (2 \rightarrow 3), the attacker simply hashes the revealed value one more time. However, this increases the total sum to 10, violating the protocol’s strict target constraint.
To maintain the mandatory target sum of 9, the attacker is forced to decrease a value on another chain (3 \rightarrow 2). Because cryptographic hash functions are strictly one-way (preimage resistant), moving backward up a chain to decrement a value is computationally infeasible, rendering the forged signature invalid.
Scaling to Many-Time Signatures
Because revealing these intermediate hashes inherently consumes the chains, this setup can only be used safely once. To sign thousands of blocks over a validator’s lifecycle, we need a many-time signature scheme.
XMSS solves this by generating a massive sequence of independent One-Time Signature keypairs. The public keys of all these OTS instances are placed as the leaves of a massive Merkle tree. The root of this Merkle tree becomes the validator’s actual global public key—this is the small, compact data point that would be submitted to the Public Key Registry.
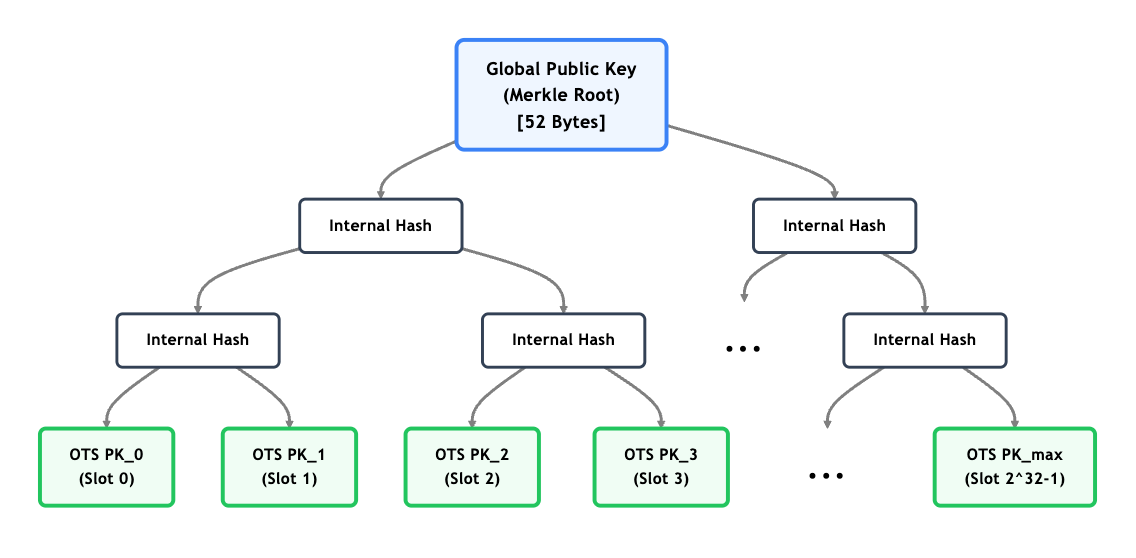
The Signing and Verification Process
When a validator needs to sign a block for a specific slot, they move to the next unused leaf in their tree. The final signature contains:
- The OTS signature for the current message.
- The specific OTS public key for that leaf.
- The Merkle authentication path (the sibling hashes) connecting that leaf to the global Merkle root.
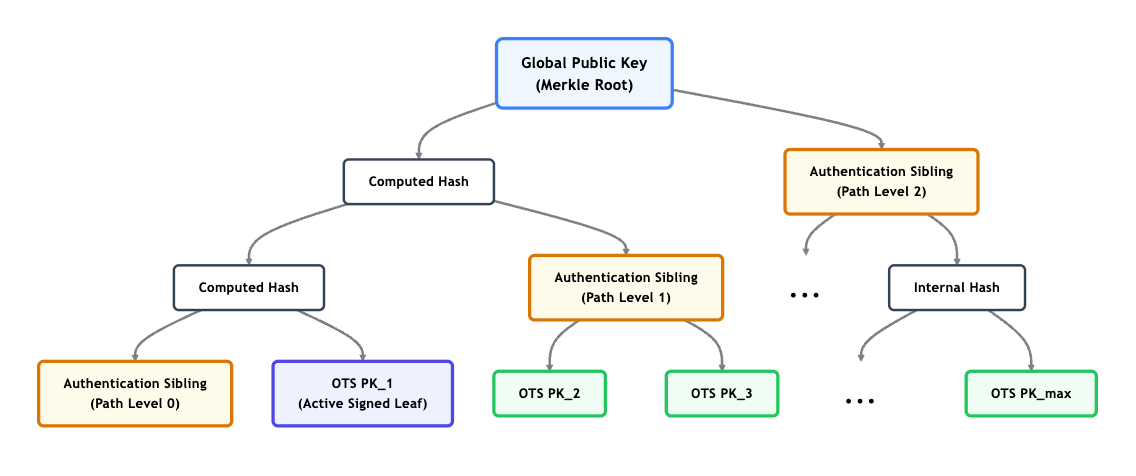
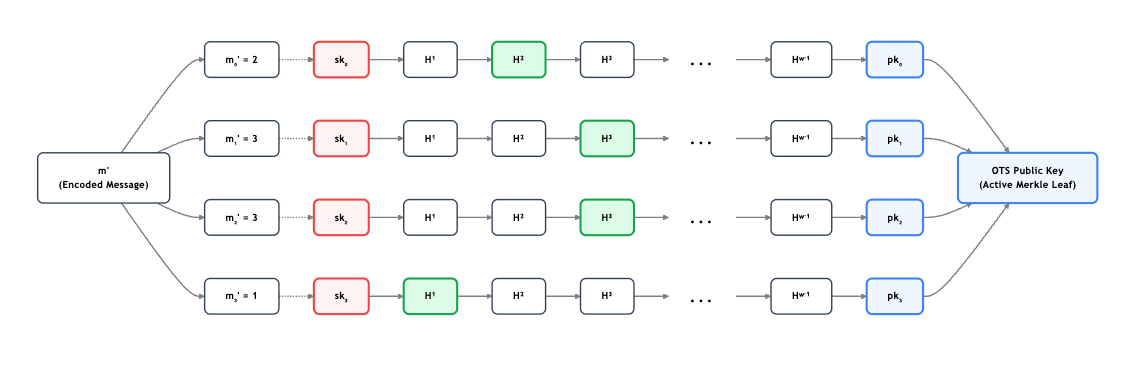
The verifier simply checks the OTS signature against the OTS public key, and then verifies the Merkle path to ensure that specific leaf is a legitimate part of the validator’s registered root.
What Gets Registered: Key Sizes and Practical Impact
Now that we understand the conceptual design of XMSS, the natural question for the registry is: what exactly does a validator need to submit, and how big is it?
Public Key: 52 bytes
Each validator’s XMSS public key consists of two parts:
| Component | Size | Description |
|---|---|---|
| Merkle root | 32 bytes | The root hash of the validator’s XMSS Merkle tree. This single value commits to all 2^{32} one-time signing leaves. It is the only thing a verifier needs to check that any individual signature belongs to this validator. |
| Public parameter | 20 bytes | A random value generated once at key creation time. It is mixed into every hash computation (tree nodes, chain steps, message hashing) and serves two primary roles: it is essential for tight security proofs, and it provides domain separation across users so that an attacker cannot attack multiple validators in parallel when attempting a brute-force attack. |
| Total | 52 bytes |
For comparison, a BLS12-381 public key is 48 bytes. The post-quantum public key is only 4 bytes larger — a remarkable result that means the registry’s per-validator storage overhead is negligible. At scale, registering 1 million validators requires storing only ~52 MiB of public keys in the state.
Signature: 3,112 bytes
Each per-slot XMSS signature contains:
| Component | Size | Description |
|---|---|---|
| Merkle authentication path | 1,024 bytes | The list of sibling hashes needed to reconstruct the path from the used leaf up to the Merkle root. The tree has 32 levels, so there are 32 siblings, each 32 bytes. A verifier re-hashes this path and checks that the result matches the public key root. |
| Encoding randomness | 28 bytes | A per-signature random value that is mixed into the message hash to produce the target-sum encoding. While it allows the signer to resample until hitting the required target sum, its primary purpose is security: without this randomness, the scheme would only provide 64 bits of security, leaving the encoding vulnerable to a birthday attack. |
| Chain hash values | 2,048 bytes | The 64 intermediate hash chain values revealed by the signer — one per parallel chain. Each value is the point in its chain that corresponds to the encoded message chunk. The verifier walks each chain forward from this revealed value to the chain endpoint and checks consistency with the Merkle leaf. |
| Total | 3,112 bytes |
This is significantly larger than a BLS signature (96 bytes), which is a reason why aggregation via SNARKs is essential (see next section).
Secret Key: Manageable on Consumer Hardware
A naive implementation would need to compute and store the full Merkle tree with 2^{32} leaves all at once—requiring terabytes of storage and immense memory. Instead, our reference implementation of the scheme uses a top-bottom tree strategy. It splits the massive tree into a top half (height 16) and 2^{16} bottom trees (height 16 each).
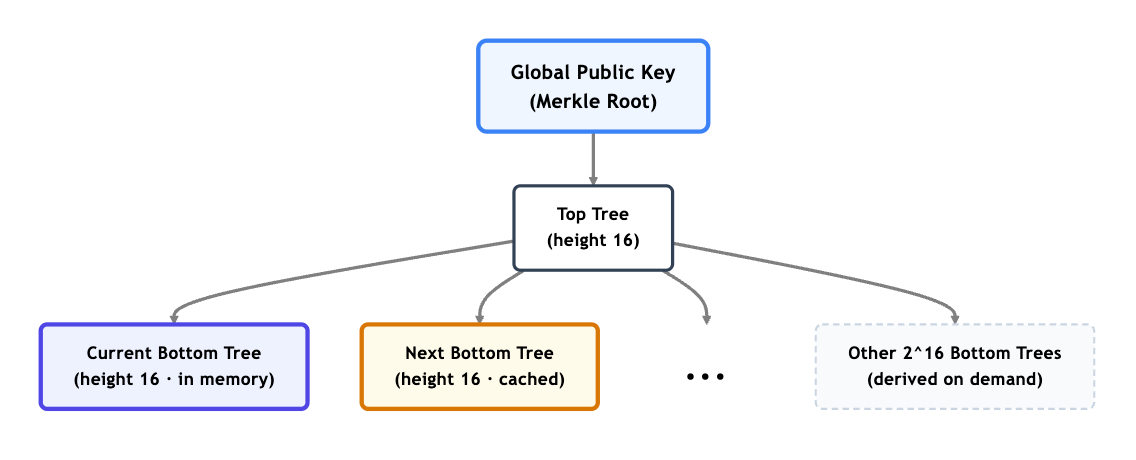
This drops the spatial complexity of key generation and signing to \mathcal{O}(\sqrt{\text{lifetime}}), meaning it only requires a few megabytes of RAM and disk space. Instead of holding the whole structure, the validator only stores the top tree and caches a sliding window of just two bottom trees: the current bottom tree and the next bottom tree. Caching the next tree is a practical necessity; it ensures a seamless transition without missing any attestations when the current bottom tree is exhausted (every ~65,536 slots, or ~9 days).
Crucially, these cached tree structures are not cryptographically sensitive. They are simply intermediate public hashes leading up to the global Merkle root. They can be stored in plaintext on standard disks. The only actual cryptographic secret is the 32-byte PRF seed.
Why KoalaBear?
All arithmetic in the scheme is performed over the KoalaBear prime field, with modulus:
This is a 31-bit prime, meaning each field element fits in a single 32-bit word (4 bytes). The choice of a small field is deliberate and performance-critical. Because the XMSS scheme and the SNARK aggregator are both dominated by field arithmetic, every multiplication and addition must be as fast as possible.
A 31-bit prime has three key advantages:
- SIMD parallelism: Four-byte elements pack tightly into CPU vector registers. On x86 processors, AVX2 instructions can process 8 field elements in parallel (256-bit registers), and AVX512 can process 16 at once (512-bit registers). On ARM processors (including Apple Silicon), NEON instructions handle 4 elements per vector. This means that a single CPU instruction can perform 4 to 16 field multiplications simultaneously.
- No overflow risk: Multiplying two 31-bit values produces at most a 62-bit result, which fits comfortably in a 64-bit register. This eliminates the need for multi-precision arithmetic or carry propagation, making modular reduction trivial.
- High two-adicity: The multiplicative group has order p - 1 = 2^{24} \times 127, giving a two-adicity of 24. While seemingly small, this is not a limiting factor for multilinear polynomial commitment schemes like WHIR when utilizing interleaved Reed-Solomon codes. Furthermore, operations in the degree-5 extension field (\mathbb{F}_{q} where q = p^5) provide the necessary 128 bits of security required by WHIR.
Beyond raw arithmetic speed, KoalaBear was specifically chosen because the cube map x \mapsto x^3 is a permutation of the multiplicative group. This holds because \gcd(3,\; p - 1) = \gcd(3,\; 2^{24} \times 127) = 1. This property is important for Poseidon: the hash function needs an S-box (a non-linear substitution layer) that is a permutation polynomial over the field. Since the cube map is already a permutation, the S-box can use degree 3 — the smallest possible. A lower-degree S-box means fewer multiplications per round, which directly translates to faster hashing and fewer constraints inside the SNARK circuit. For comparison, other fields like BabyBear (p = 2^{31} - 2^{27} + 1) require an S-box of degree 7, and BN254-based Poseidon uses degree 5.
The combination of a degree-3 S-box, high two-adicity, and SIMD-friendly element size makes KoalaBear an exceptionally well-suited field for this workload.
Production Scheme Parameters
The table below lists the full production configuration used until now for our lean consensus devnets. To make it easier to follow, the parameters are grouped by what part of the system they control.
Lifetime and Message
These parameters define the overall scope of a key and what it signs.
| Parameter | Value | Description |
|---|---|---|
| Key lifetime | 2^{32} slots (~1632 years at 12-second slots) | The total number of slots a single key can be used for. Each slot consumes exactly one leaf of the Merkle tree, so the tree has 2^{32} leaves. |
| Message length | 32 bytes | The size of the data being signed. In practice this is a hash of the attestation or block data — always exactly 32 bytes. |
Message Encoding (How a Message Becomes Chain Positions)
Recall from the XMSS overview above that signing a message means revealing intermediate values in hash chains. But first, the message must be converted into a set of numbers that tell the signer where to reveal in each chain. This conversion is called the encoding, and these parameters control how it works.
The message is hashed together with some fresh randomness to produce 46 numbers (one per chain), each between 0 and 7. These numbers are the chunk values. The chunk value for a given chain tells the signer how many steps to walk into that chain from its secret starting point before revealing the value. The verifier then walks the remaining steps to the chain endpoint: with a maximum chain length of 7, a chunk value of 5 means the signer revealed the value 5 steps in, and the verifier hashes it the remaining 2 times (7 - 5) to reach the endpoint.
The critical security constraint is the target sum: the 46 chunk values must add up to exactly 200. This is what makes the encoding incomparable — no valid codeword can be reached from another by moving every chain in the same direction. Since an attacker who has seen a signature can only ever hash the revealed values forward (which increases a chunk value), they would have to decrease some other chunk to keep the sum at 200. Decreasing a chunk means inverting the hash, which is computationally infeasible. The fixed sum plus the one-wayness of the chains is what prevents forgery.
If the 46 chunk values were sampled uniformly, their expected sum would be about 161 (46 × 3.5). The target of 200 is deliberately set above this average: because the verifier only walks the remaining steps of each chain, a higher target sum means fewer hash evaluations at verification — here, 46 × 7 - 200 = 122 chain hashes in total, versus 161 if the target sat at the mean. To make the chunk values uniform in the first place (so the target is hit predictably), the message hash uses an aborting hypercube construction. It rejection-samples the hash output, discarding and re-hashing whenever an output element falls outside the uniform range. The signer then simply draws fresh randomness and re-encodes until the 46 values happen to sum to exactly 200, up to 100,000 attempts; in practice, a valid encoding is found well within that bound.
Note: Because optimizing these hash functions in the SNARK context for signature aggregation is a highly active area of research, the exact underlying encoding algorithm remains a moving piece. The parameters below represent the current working configuration, but specific values may evolve as the cryptography is finalized for mainnet.
| Parameter | Value | Description |
|---|---|---|
| Number of parallel hash chains | 46 | The message is encoded into 46 independent chunks, one per chain. More chains means more security but larger signatures. |
| Alphabet size per chain | 8 | Each chunk value is between 0 and 7 (i.e., base 8). This determines the maximum depth of any single chain. |
| Maximum chain length | 7 steps | The longest possible walk along a chain (alphabet size minus 1). The signer and verifier together never traverse more than 7 hash evaluations per chain. |
| Target sum | 200 | The 46 chunk values must sum to exactly this number for the encoding to be valid. This is the anti-forgery (incomparability) mechanism. |
| Maximum encoding attempts | 100,000 | Upper bound on how many times the signer tries different randomness to find a valid encoding. |
| Encoding randomness | 7 field elements (28 bytes) | The fresh random value mixed into the message hash on each attempt. Included in the signature so the verifier can reproduce the encoding. |
| Message field-element length | 9 field elements (36 bytes) | The 32-byte message re-encoded as field elements and fed (together with the randomness and public parameter) into the message hash. |
Hash Function and Internal Sizes
These parameters control the hash function used throughout the scheme. All sizes are expressed in field elements; each KoalaBear field element is 4 bytes, so multiplying by 4 gives the size in bytes.
| Parameter | Value | Description |
|---|---|---|
| Internal hash function | Poseidon1 over KoalaBear (width 24 and width 16) | The arithmetization-friendly permutation used for all tree hashing, chain hashing, and message hashing. It runs at width 24 (operating on 24 field elements at a time) for tree-node merging and the message-hash sponge, and at width 16 for the per-step chain hashing, which only needs to compress a single value. |
| Message-hash sponge rate / capacity | rate 15 / capacity 9 | The message hash runs the width-24 permutation as a sponge: 15 of the 24 state elements carry input/output data (the rate), and the remaining 9 are reserved for domain separation (the capacity). Tree and chain hashing instead run in compression mode rather than as a sponge. |
| Hash digest length | 8 field elements (248 bits) | The output size of each hash invocation. Every tree node, chain endpoint, and message hash is 248 bits. This targets roughly 128 bits of classical security and 64 bits of quantum security. |
| Public parameter length | 5 field elements (20 bytes) | The random per-validator value that is part of the public key and mixed into every hash to ensure independence between validators. |
| Sponge capacity | 9 field elements | The portion of the width-24 Poseidon1 sponge state reserved for domain separation. Combined with per-call tweaks, this ensures different uses of the hash (tree nodes, chain steps, message hashing) cannot collide across contexts. |
Tree Structure and Key Derivation
| Parameter | Value | Description |
|---|---|---|
| Merkle tree height | 32 levels (split into 16 top + 16 bottom) | The tree has 2^{32} leaves (one per slot). It is split into a top tree of height 16 and many bottom trees of height 16 each, so that only two bottom trees need to be in memory at a time. |
| Key derivation PRF | SHAKE128 (256-bit key) | All secret material (chain starting values, per-signature randomness) is derived deterministically from a single 32-byte master seed using SHAKE128. This means the validator only needs to back up one 32-byte value. |
Signature Aggregation via leanVM and pqSNARKs
Hash-based signatures do not natively support the public aggregation features we enjoy with BLS. With ~1 million validators each broadcasting a ~3.1 KiB signature, the bandwidth requirements for aggregators would easily exceed 3 GiB per slot, which is entirely unfeasible for Ethereum’s slot constraints.
The solution is to aggregate these synchronized many-time signatures using a succinct argument of knowledge (a pqSNARK). To handle this elegantly and efficiently, we utilize leanVM, a minimal, Cairo-inspired zkVM designed specifically for Ethereum’s post-quantum signature verification. leanVM is built on a highly optimized proving stack utilizing SuperSpartan with AIR-specific optimizations, Logup for bus interactions, and WHIR for multilinear polynomial commitments. Crucially, WHIR allows for simple polynomial stacking, avoiding the need to Merkle commit to each individual column and significantly reducing the final proof size.
Instead of verifying a massive batch of signatures simultaneously in one giant circuit, leanVM uses recursive aggregation. The protocol partitions the signers into manageable groups, aggregators verify their XMSS signatures to create sub-proofs, and then recursively run the leanVM verifier inside the program to merge these sub-proofs into a single final proof.
Because the consensus layer must know exactly who participated to process rewards, inactivity leaks, fork choice weight, and slashing, the aggregate payload includes both the leanVM proof and a signer bitfield (similar to the bitlists used in current BLS attestations). The leanVM circuit is explicitly constrained to prove that valid signatures exist for the exact subset of public keys indicated by this accompanying bitfield.
Based on recent benchmarks running on high-end consumer hardware (e.g., an M4 Max CPU), leanVM achieves a proving throughput of roughly 1k XMSS signatures per second. In its proven security regime—offering 123 bits of provable security via a degree-5 extension of the KoalaBear field—a 2-to-1 recursive proof takes less than a second to generate and results in a highly compact final proof size of roughly 128 KiB to 350 KiB depending on the PCS rate. This recursive approach scales well, making on-chain verification and network propagation highly practical for Ethereum’s slot budget.
The Hash Function: An Open Design Space
Because the verification process is dominated by hash function evaluations, the efficiency of our pqSNARK aggregator relies heavily on the chosen hash function.
Initially, Poseidon2 emerged as a leading candidate. It operates natively over finite fields, making it highly optimized for modern arithmetization frameworks and zkVMs like leanVM. However, recent cryptanalysis and attack techniques targeting algebraic hash functions (such as those detailed in eprint 2026/306) are forcing us to reconsider relying solely on Poseidon2.
Because we have not made a final decision, the design of the Public Key Registry must remain flexible. To accommodate this, we may allow the generation of public keys using various hash functions—a design referred to as the multi-hash public key registry.
Current Hash Candidates
| Hash Function | Arithmetization Efficiency | Cryptanalytic Maturity |
|---|---|---|
| SHA / BLAKE3 | Low (heavy bitwise operations) | High (highly battle-tested) |
| Poseidon1 | High (SNARK-friendly) | Medium (subject to ongoing analysis) |
| Poseidon2 | Very High (optimized for modern fields) | Low (recent attacks raise concerns) |
This directly impacts registry design: the registry must be hash-function-agile, potentially storing a hash function identifier alongside each public key so the network can support multiple hash functions during the transition and mandate migration if one is deprecated.
Part 2: Registry Design Considerations
Registration Protocol Mechanics
The registration protocol itself requires concrete mechanics to ensure a smooth, secure, and sybil-resistant transition without overwhelming the Beacon Chain. Because this upgrade fundamentally changes validator identities, the lifecycle of a key registration must be carefully managed. Here is the proposed architecture for how validators will actually register their keys:
-
Delivery and Authorization: To securely bind a post-quantum identity to an existing validator, the delivery mechanism will likely utilize a new consensus-layer operation (e.g., a
PostQuantumRegistrationmessage). This submission must be explicitly authorized to prove definitive ownership of the validator index. For validators with0x01or0x02execution-layer withdrawal credentials, this would involve an L1 signature from the withdrawal address. For legacy0x00credentials, it would require a signature from the currently active BLS key. Crucially, this registration message must also include a Proof of Possession—a single valid XMSS signature over the registration payload. Without this, the protocol would blindly accept 52 raw bytes, meaning a validator with a silently broken key generation setup wouldn’t discover the failure until the actual signing fork years later. Once both signatures are verified, the network accepts and binds the 52-byte XMSS public key to the validator record in the beacon state. To support hash-function agility, this binding is not permanent; the registration message should include a sequence number or version field to allow validators to update or rotate their keys in the future. -
Per-Block Processing Cap and State Growth: To protect the network from state bloat and computational spikes during a mass registration event, the protocol must enforce a strict processing queue. Similar to the existing validator activation and exit churn limits, we propose capping the number of registrations processed per slot (e.g.,
MAX_PQ_REGISTRATIONS_PER_BLOCK = 16). Registrations broadcast to the gossip network will sit in a local memory pool; block proposers will pack up to the maximum limit into their blocks. This ensures that block verification times remain predictably low and the resulting state growth is smoothed out over weeks or months, preventing sudden spikes in node resource requirements. -
Incentives and the Transition Timeline: A major risk of a phased rollout is a last-minute stampede right before BLS signatures are formally deprecated, which could overwhelm the processing queue and leave active validators unable to sign, threatening network finality. To avoid this, the rollout will incorporate mechanisms to encourage early action. Validators who participate in the early warmup phase could be granted priority placement in the eventual post-quantum activation queue. Alternatively, a modest, temporary boost to attestation rewards (e.g., a slight multiplier on the base reward) for early registrants could efficiently drive adoption. Finally, as the hard deadline approaches, the protocol could employ a stick approach—gradually applying an inactivity leak or initiating forced exits for validators who have failed to register a post-quantum key, ensuring the active set consists only of PQ-ready nodes before the final switch is flipped.
Hash Function Agility
Because the hash function is not yet finalized, the registry must be designed with agility in mind. One approach is to allow validators to register keys under different hash function identifiers, meaning each registry entry would carry the 52-byte public key along with a tag indicating the chosen hash function. If a function is later compromised, affected validators would be required to re-register. Alternatively, to ensure robust future-proofing without the friction of future re-registration, the protocol could enforce the use of two or three specific hash candidates (e.g., Poseidon1, BLAKE3, and SHA-256) from the start. In this scenario, every validator would perform key generation for each mandated hash function upfront, and the final value committed to the registry would simply be the concatenation of these multiple XMSS public keys.
Because keygen and registration are frontloaded, if one hash function is compromised, the network can quickly switch to an alternative without validators needing to regenerate keys from scratch. While this approach provides excellent future-proofing, there is a minor trade-off: the registered key size increases from 52 bytes to 104–156 bytes. Fortunately, the computational overhead for key generation is minimal. Since traditional bitwise hash functions (like SHA-256, BLAKE3, or Monolith) are orders of magnitude faster to compute on standard CPUs than algebraic hashes like Poseidon, generating these backup trees adds only a fraction of time to the baseline key generation process. Ultimately, this slight increase in storage and computation is a highly acceptable trade-off for the seamless agility it provides. These two solutions are just ideas with advantages and drawbacks for each, requiring further exploration.
Key Lifetime and Activation Windows
XMSS keys are inherently generated with an explicit activation window: a starting slot and a finite number of active slots dictated by the Merkle tree’s capacity. Because the cryptographic construction ties each signature to a specific sequential position, a key naturally cannot sign messages outside this window. Consequently, there is no need to explicitly record these bounds in the registry or enforce them at the protocol level; once a validator exhausts their available leaves, they simply lose the ability to produce valid signatures.
For memory efficiency, activation slots are aligned to boundaries of 65,536 slots (~9 days). This is transparent to the validator — the key generation tool handles the alignment automatically.
Serialization
All data structures use SSZ (Simple Serialize), the standard serialization format for Ethereum’s consensus layer. The public key is a fixed-size 52-byte value, making it straightforward to include in the existing beacon state validator record alongside the current BLS key.
Practical Considerations for Validators
Registering a post-quantum key is a one-time operation, but it involves generating a massive Merkle tree and securely storing the resulting material. Here is what validators should expect in practice compared to today’s operations:
- Key generation is computationally heavy but memory-light: The validator runs an offline tool that expands a 32-byte seed into the full XMSS tree. Because the tree has 2^{32} leaves, this involves billions of hash evaluations. The reference implementation parallelizes this across all available CPU cores using SIMD optimizations. While this process takes on the order of hours on a modern multi-core machine (e.g., 8-16 cores), thanks to the top-bottom tree strategy, it operates in \mathcal{O}(\sqrt{\text{lifetime}}) space. This means any standard machine with just a few megabytes of free RAM can generate keys. Because it involves the master secret, this one-time operation must be done on an air-gapped or cold-storage machine.
- The secret vs. the operational key: Today, an encrypted BLS validator keystore is roughly a single kilobyte. In the PQ era, the actual cryptographic secret (the 32-byte PRF seed) remains tiny and must be fiercely guarded and backed up. Losing it means losing the ability to sign, with no recovery possible. However, the operational key file—which caches the non-secret top tree and the current bottom tree pair for fast, lightweight signing—is serialized in SSZ format and sits at around tens of megabytes. While significantly larger than a BLS key, this operational file fits easily on consumer SSDs.
- Ongoing signing is lightweight: Once the key is generated and the operational file is loaded into the signing infrastructure, producing a signature for each slot requires only a handful of hash evaluations (walking 64 chains of at most 7 steps each, plus one Merkle path lookup). This is fast enough to run effortlessly on standard consumer hardware well within the 12-second slot budget.
- Community-led tooling: Building the key generation UX requires strong stakeholder engagement from day one. A major learning from the beacon chain launch is that relying solely on the EF to maintain the
deposit-clibecame a bottleneck over time. To ensure sustainable support, security audits, and feature iteration (like consolidations), we envision the PQ key generation tool being an open-source, community-maintained effort from the start, potentially incentivized by EF grants.
What the validator actually submits to the registry is the 52-byte public key along with a single XMSS Proof of Possession signature. This proves end-to-end that the offline keygen worked perfectly. This submission can be done via a standard on-chain transaction, similar in spirit to the current BLS key deposit. The secret key never leaves the validator’s machine.
Open Questions and Future Work
-
Hash function finalization: Will Poseidon survive continued cryptanalysis, or will we need to fall back to SHA-3/BLAKE3 (at significant proving cost)?
-
Registry update mechanism: How should the state accommodate key rotation or re-registration if a validator needs to switch hash functions?
-
Aggregator economics: Who bears the computational cost of SNARK proving? Should aggregation be compensated via protocol rewards?
-
Compatibility period: During the transition, should the protocol support both BLS and XMSS signatures simultaneously?
-
Scaling the registry: The current devnets support only hundreds of validators. Production Ethereum has ~1 million. How does the aggregation tree scale?
-
Polynomial Commitment Optimization: We are currently relying on WHIR for our multilinear polynomial commitments due to its efficiency with small fields and recursive stacking. Can we further shrink proof sizes by refining our Reed-Solomon interleaving strategy or integrating alternative polynomial commitment schemes entirely?
-
Key Generation UX and Tooling: How can we make the key generation process accessible and foolproof for solo stakers? Learning from the
deposit-cli, how do we foster a community-owned, grant-incentivized open-source effort to build this critical infrastructure from day one? -
Standard Model vs. ROM for XMSS: There is an ongoing debate about shifting XMSS parameters from the standard model to the Random Oracle Model (ROM). While relying on the ROM is less conservative cryptographically, it would shrink the signature size below the IPv6 MTU limit and eliminate the need for multiple Poseidon widths (16 and 24). Furthermore, since the SNARK aggregator already relies on the ROM, standard-model XMSS might be unnecessarily strict. Should we lean into a stronger (more rounds) Poseidon and embrace the ROM to simplify the scheme?
-
The Finite Field Choice (KoalaBear vs. Goldilocks): While KoalaBear is extremely fast, its 31-bit size and low two-adicity (24) impose strict limits on proof size—currently capping leanVM at roughly 16M cycles and 2M Poseidons to prevent Logup multiplicity overflows. Migrating to a 64-bit field like Goldilocks would solve these overflow constraints, allow for larger proofs, support native storage of CL balances, and easily hit 128-bit security (via a Poseidon state of 8) with minimal WHIR grinding. The primary trade-off is proving speed, which is currently about 2x slower on Goldilocks. Should the protocol prioritize the capacity and elegance of Goldilocks, anticipating future performance optimizations?