Here is an update on the testing status of this project. First and foremost, I can’t stress enough the amount of time, energy and even money that was put forth by the @EthPandaOps team. They dedicated over a week of several back and forth to set up a devnet to measure this.
Here’s a short summary of the results.
- We tested with very large block sizes, up to 6MB blocks (created with spamoor).
- There were 1000 nodes each carrying 1000 validator keys, distributed geographically.
- Block broadcast was delayed 2 seconds to set a common baseline for broadcasting.
- Block arrival was measured at 145 sentry nodes.
- No blobs were sent during the experiment (Prysm’s implementation does not support them)
The RLNC implementation had the following parameters:
- Blocks were divided in 10 chunks.
- Each node submitted 40 chunks to their peers.
Computational overhead
Results were not as expected at first, but the RLNC implementation on Prysm was a proof of concept that was not optimized. We had not accounted for the fact that the computational overhead of creating the commitments becomes dominant in these large block ranges. Without parallelization benchmarks of producing blocks of 6MB, 2MB and 200KB on a Ryzen 3600 are:
goos: linux
goarch: amd64
cpu: AMD Ryzen 5 3600 6-Core Processor
BenchmarkChunkMSM_6MB-12 1 2692349646 ns/op
BenchmarkChunkMSM_2MB-12 2 727631407 ns/op
BenchmarkChunkMSM_200KB-12 14 72044668 ns/op
Thus, in the large block scenario, the RLNC branch was broadcasting blocks no earlier than almost 3 seconds into the slot, which gives almost an entire second difference with the gossipsub blocks of the baseline.
Different mesh size
Besides the computational overhead that was not parallelized, the other issue is that the RLNC devnet had an effective mesh size of half the gossipsub devnet, as nodes broadcasted 40 chunks, totaling 4 blocks, instead of the 8 chunks broadcast by the gossipsub devnet. This effectively shows that the RLNC devnet was using much less of the available bandwidth.
Results
In the regime of up to 2MB the results are shown in the following graph:
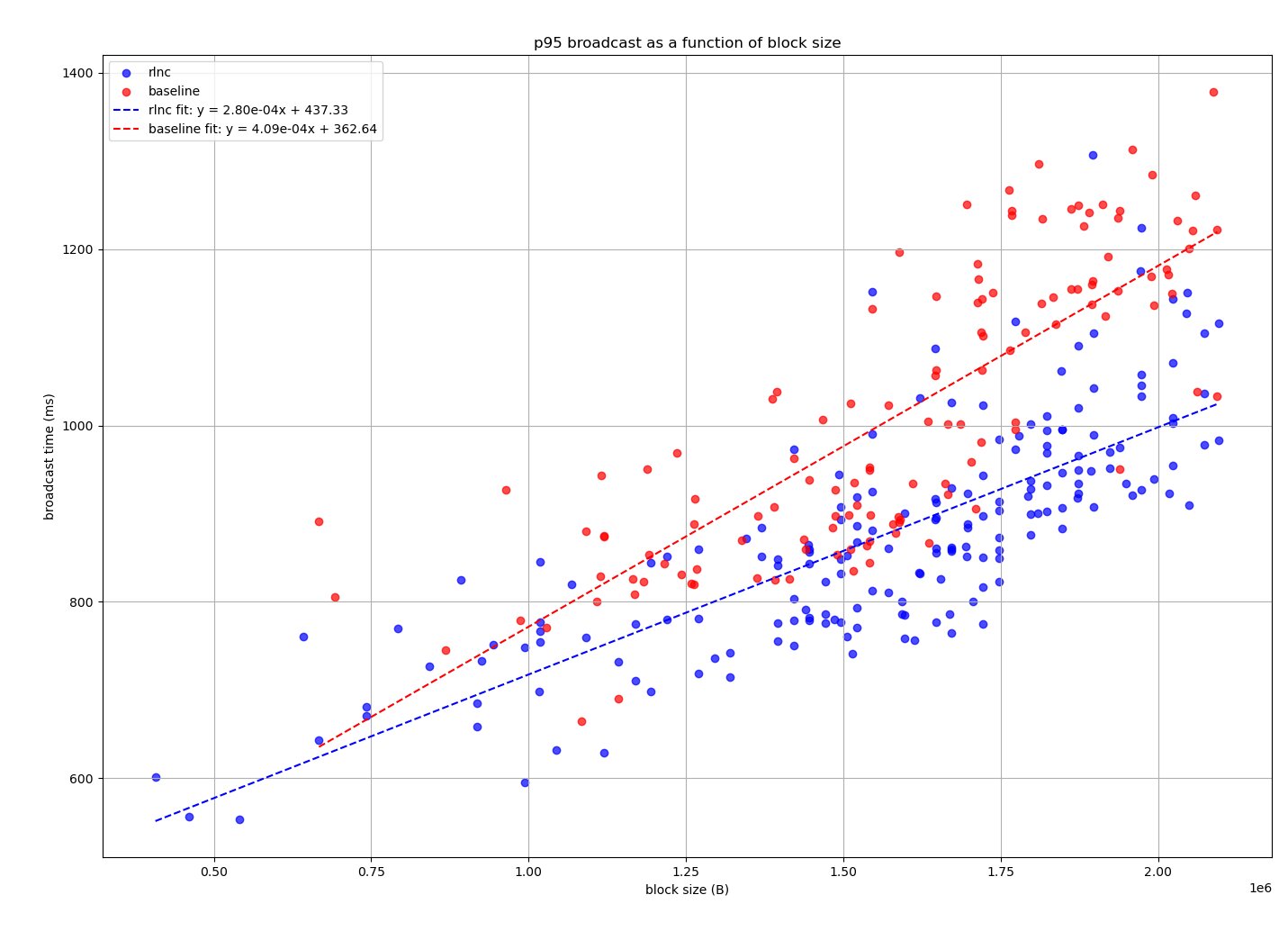
Which shows that RLNC without any optimizations and broadcasting half of the data, results in a big improvement, given that gossipsub takes 46% more time to broadcast the blocks in the limit.
In the regime of very large blocks the results are shown in the following graph:
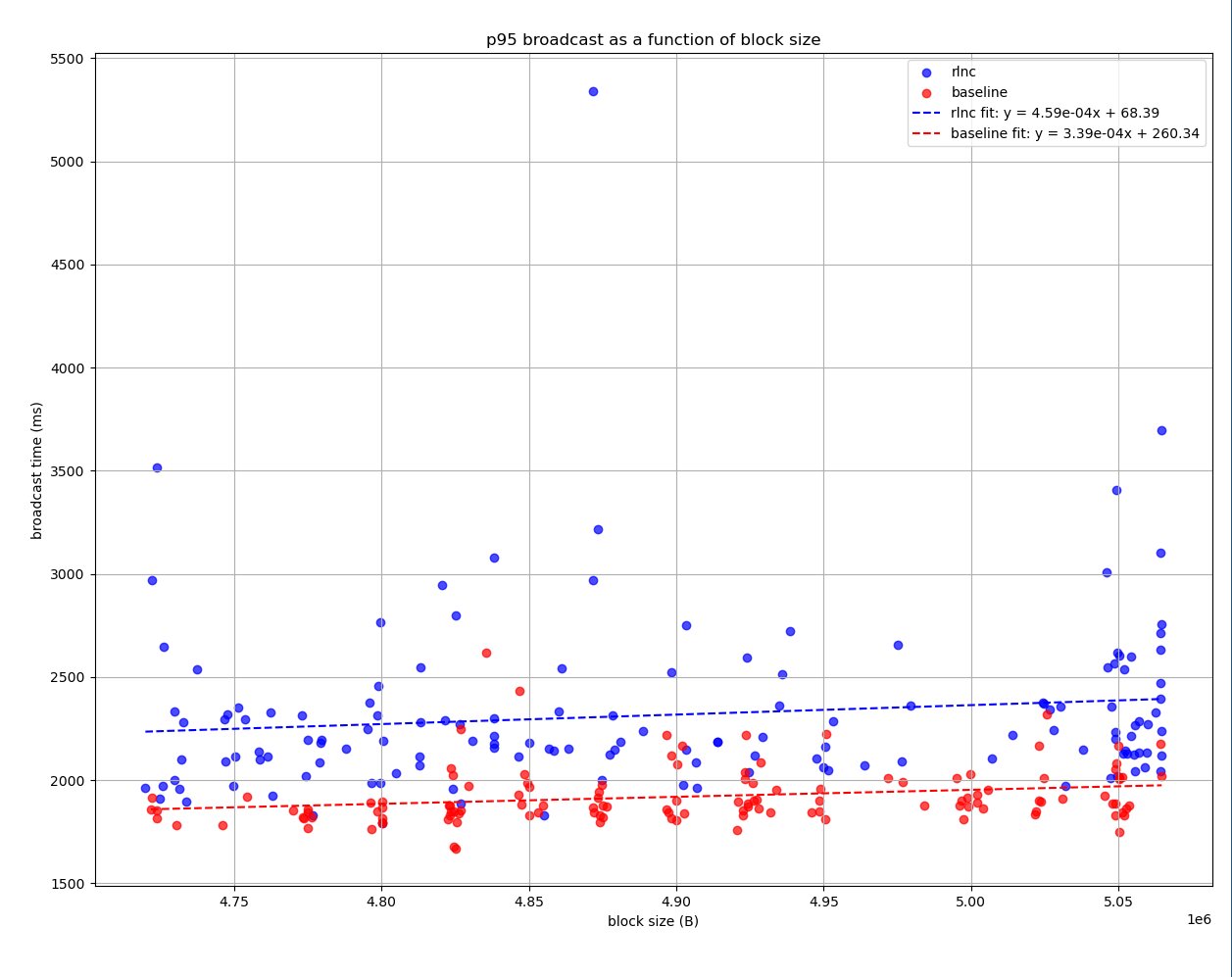
Which shows that the constant computational overhead is dominant. The RLNC devnet showed also instability in this range since blocks were being broadcat close to the attestation deadline.
What we learned
The results show a strong improvement in the block size range of up to 2MB (ten times the current average) but the data is not really compatible with real life applications. Since we produced this data the following improvement have been made to the Prysm implementation
- We parallelized the commitment computation, reducing it to less than 300ms in the 6MB block range and less than 10ms in the 200KB range.
- We made the number of chunks and the mesh-size user-configurable so that these tests can be repeated without recompilation of the client and with just a configuration change in the validators.
- We should gather data also in the 100KB–200KB block size range, since these are the sizes that are more common in Ethereum mainnet. The very large block range would give some insight into blob propagation, where the cryptographic CPU overhead of RLNC would be compared against KZG or RS computations that are absent in block propagation.