Contract execution can be parallelized perfectly (ie. maximum Amdahl’s speedup) under the transactional memory model as a purely implementation-level optimization, however that would make current block gas limits ineffective: it would be possible to create two blocks with ostensibly identical total gas, but one with no possible parallelism (ie. purely sequential) and another where every storage access + calls are independent from other transactions. The former would take a much longer time to execute.
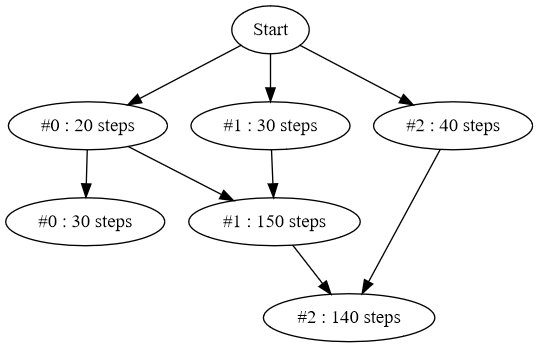
This can be solved by requiring block creators to provide an execution schedule tree and compute a sequential gas limit from it. For example for a block with 3 transactions (#0 - first transaction etc):
Each node can only be executed after all its parents are done. The sequential gas used is defined as maximum use from all execution paths. Assuming for simplicity that step = 1 gas, used sequential gas for a block with this graph is 30+150+140 = 320 as that’s the most expensive path.
A block is considered invalid if results are different from the (current) purely sequential execution model. This can be checked by tagging every state change (storage+contact creation/destruction) with a changing transaction’s index (only temporarily in ram and per-block). Invalid ordering results in a transaction #x that accesses state changed by #>x.
It’s also possible to define ‘parallel gas used’ as a maximum concurrent gas consumption per step. For the previous tree (and step = 1 gas) that would be 3: for the first 20 steps three instructions are executed in parallel. Thus a ‘block parallel gas limit’ could be added. At a minimum it must be equivalent to the current highest priced possible individual operation.
The parallelization algorithm used during block creation stays completely out of consensus and is optional: a list is a valid execution schedule too.
All these changes are invisible to everyone else: nothing changes as far as contract writers and users are concerned. The only difference: transactions that are cheaper to parallelize would likely be accepted with a lower gas price.
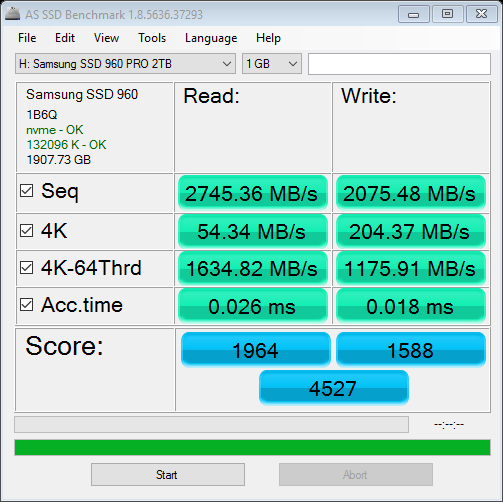
Even with a single-threaded execution this would help due to parallel db access. A single random read is slow even on a high-end hardware, while throughput for many parallel reads continues to rise - for 960 it’s 30x faster:
Thoughts? Would you support adding this?
2 Likes
Yep, this is definitely the right direction to be thinking. http://github.com/ethereum/EIPs/issues/648 had a somewhat similar mechanism, though simpler and limited to N CPU cores for some specific N.
Copying the relevant bits (“range” ~= “access list” as we use it here):
We keep track of a starting_gas_height and finishing_gas_height for each transaction. We define the starting_gas_height of a transaction T to be the maximum of all finishing_gas_heights of all transactions T’ before T such that either (i) T’ is more than MAX_THREADS behind T (ie. txindex_of(T) - txindex_of(T') > MAX_THREADS) or (ii) the ranges of T and T’ intersect. We define the finishing_gas_height of T to be the starting_gas_height of T plus the amount of gas consumed while executing T.
The current rule that a transaction is invalid if its start_gas plus the current total_gas_used exceeds the block gas_limit is removed, and replaced with a rule that a transaction T is invalid if: T.starting_gas_height + T.start_gas > gas_limit. Notice that in the case where all transactions use the entire address space as their range, this is exactly equivalent to the current status quo, but in the case where transactions use disjoint ranges, this increases capacity.
EIP 648 seems less efficient to me.
(1) It treats transactions as units. Imagine a transaction that has a conflicting call as literally the last instruction with the rest totally independent. A schedule tree would be able to parallelize all preceding instructions with other transactions. EIP 648 would execute it sequentially in full.
(2) Transaction as a unit limits i/o latency hiding. With a schedule tree one expensive SSTORE that costs 20k GAS would allow free (for sequential limit) and almost free (for parallel) inclusion of hundreds of cheap opcodes, even if in the range model they would be all from conflicting transactions.
(3) Ranges are coarse grained.
(4) Ranges are pessimistic. They would prevent parallelization eg. in case of an ICO reaching its cap and reverting after a simple comparison, as people’s transactions would expect a successful entry.
With exception of the MAX_THREADS limit, a schedule tree allows EIP648’s strategy to be utilized by a block creator. Range-based parallelization can be used as a simple strategy for generating a schedule tree by executing every new transaction and observing what it touches, which is also what a sender would do. Transactions can be scheduled to execute without interruptions (ie. all steps at the same time).
Agree that it’s suboptimal, though keep in mind that most machines only have 2-8 cores, so having more than 8x parallelizability doesn’t really help much. I think ranges are actually orthogonal to the parallelization technique; in general, what you need is a scheme that determines whether or not two transaction executions conflict.
You can then have the miner/proposer commit to a schedule tree, and have the execution process check whether or not any transactions in the schedule tree ended up conflicting (specifically: do there exist indices M and N (assume N > M), such that in the actual execution, tx N read something that tx M wrote, and tx N was executed in the schedule with a pre-state not taking tx M into account), and if any did make the entire block invalid. That kind of scheme can take in many definitions of “conflicting”, of which ranges are one but I am sure there can be others.
Ok, so I take it you like the general idea of a instruction-level (ie. steps) schedule tree? Leaving the question of how to compute parallel limits.
Relevant only for compute-bound transactions. For others, hiding i/o latencies should give easy >10x speedup even on one core.
Every operation should have a separate compute time cost and a latency (i/o) cost. A compute parallel limit according to a reasonable core count (8?) and one core compute performance, and a parallel i/o limit according to the throughput difference between one random access and batched access (30?).
Or in other words, if on a 8-core desktop it’s possible to execute 8000 ADDs while waiting for completion of 30 SLOADs, and any subsequent additions, whether compute or i/o, start to increase sequential time, the limits should reflect this.
This would align a block creator’s scheduling incentive with the actual time it takes to verify the block much closer.
This means that SLOAD should be the most i/o expensive opcode, with SSTORE having i/o and compute cost equivalent to that of MSTORE. That’s because writes are easily cached but loads are random.
These costs would concern parallel limits only; SSTORE’s sequential cost would still be paid.
Fortunately none of this changes the simple ‘gas price’ mechanism from the user’s perspective so there’s lots of freedom. That’s because if the ‘market price’ for i/o (parallel) gas is ioGasPrice and computeGasPrice for compute, then it’s enough to pay a gasPrice that fulfills:
usedGas*gasPrice >= ioGasUse*ioGasPrice+computeGasUsed*computeGasPrice
which means if most blocks are parallel i/o full but have unused parallel compute space then compute-heavy transactions are going to be accepted with lower gas prices.
Not sure if it’s a good idea to go that far. I’d like to avoid digging deep into the VM and treat it as a black box as that allows us to more easily work on optimizing the surrounding protocol and the VM separately, and I do believe that parallelization between transactions is sufficient.
Also, there is overhead involved in checking whether or not the schedule tree supplied by the proposer is correct (ie. whether or not it is actually equivalent to a sequential execution)
For others, hiding i/o latencies should give easy >10x speedup even on one core.
I believe @AlexeyAkhunov did some tests on an SSD, and parallelizing reads achieved only a 2x speedup.
1 Like
The additional overhead is zero as accesses are already cached. Only one additional comparison is needed.
This one? If so, the speedup is only 2x because file is cached by the system. Caching should be disabled for i/o benchmarks.
>10x speedup is for actual i/o. If everything (or almost everything) fits in ram i/o is not a problem in the first place. Partial caching is dangerous to rely on because it results in high variance of latency.
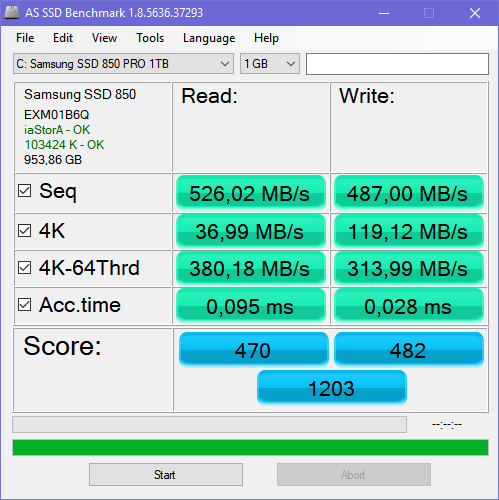
You can check throughput results for yourself with as ssd or any other ssd benchmark software. That’s how it looks on my sata ssd:
1 Like