The additional overhead is zero as accesses are already cached. Only one additional comparison is needed.
This one? If so, the speedup is only 2x because file is cached by the system. Caching should be disabled for i/o benchmarks.
>10x speedup is for actual i/o. If everything (or almost everything) fits in ram i/o is not a problem in the first place. Partial caching is dangerous to rely on because it results in high variance of latency.
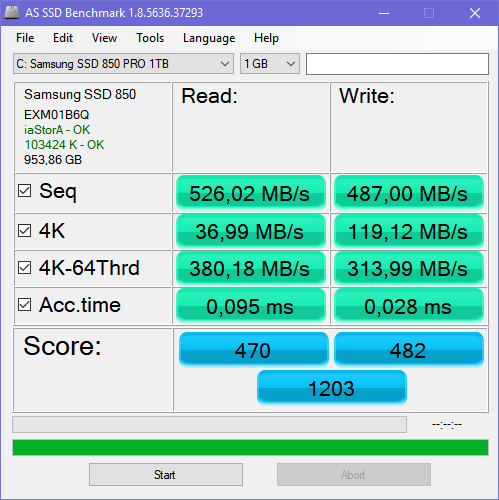
You can check throughput results for yourself with as ssd or any other ssd benchmark software. That’s how it looks on my sata ssd: