In this proposal, I present a method to enhance the efficiency of state management in Ethereum clients, allowing for significant gas limit increase. The proposal involves using a Least Recently Used (LRU) cache to maintain approximately 2.5GB of the most recently accessed state, aiming for a total memory usage of around 8GB. State slots accessed that are part of this cache would priced significantly less gas wise than those outside. This would allow clients like Geth or Reth to make strong assumption for their memory usage and would price disk i/o properly.
This would make 8GB of RAM the minimum requirement to run an ethereum full node.
Introduction
Efficient state management is crucial for Ethereum clients, particularly as the chain continues to grow in size and complexity. A common challenge is maintaining quick access to a large set of state data with limited physical memory. Currently Ethereum’s state is about 100GB, far larger than RAM access of most full nodes. This means we need to price all read/writes high enough in case they were read from disk. The proposed solution introduces an LRU cache at the consensus level, a well-known caching strategy that ensures the most recently accessed data is kept readily available, while less frequently accessed data is relegated to slower storage. With a precise agreement on what should be cached, we can price memory i/o and disk i/o independently, making state growth significantly less of a concern.
Why LRU Cache?
Optimizing for Recent Access: LRU caches are excellent for scenarios where the most recently accessed data is also the most likely to be accessed again soon.
Fixed Memory Usage: An LRU cache can be configured to use a fixed amount of memory (2.5GB of state in this case), making it ideal for systems with limited RAM.
Simple and Effective: LRU is a time-tested caching strategy known for its simplicity and effectiveness in various computing scenarios.
Implementation Details
State Slot Size: Each storage state slot is 32 bytes in size.
Number of Slots: With 2.5GB dedicated to state data, the cache can hold the latest 83,886,080 state slots accessed by transactions
New slot access: When a new slot is accessed, the oldest slot part of the LRU will be evicted and the new slot will be added as the most recent slot accessed in the LRU.
Recent slot access: When a slot already part of the LRU is accessed, it will be moved / marked as the most recent state slot accessed.
Old slot access: When an old slot is accessed, the oldest slot part of the LRU will be evicted and the accessed old slot will be added as the most recent slot accessed in the LRU.
Advantages
Quick Access to Recent State: Enhances performance for frequently accessed state data.
Reduced I/O Overhead: Limits the need to access slower storage mediums and price them significantly higher
Predictable Memory Usage: Offers a scalable solution that adapts to the changing state access patterns without exceeding the allocated memory.
Gas limit increase: Allows for significantly increasing gas limit due to making state size growth a non-problem, I suspect by 5x to 10x (with 100% of state in memory, a reth client can reach ~20k TPS)
Simplicity: Significantly simpler than other proposals dealing with state growth like ReGenesis, statelessness, state rent, state expiry (this approach is state expiry in disguise), etc.
Potential Challenges
Implementation Complexity: Managing the LRU cache, especially in a multi-threaded environment, requires careful implementation.
Memory Overhead: Ensuring the total memory usage remains within the desired limit needs precise calculation and memory-efficient
Minimum RAM requirement: Clients would now have a minimum RAM requirement of 8GB for full nodes (which seems fine to me in 2024). This can be easily adjusted if we determined at a smaller cache would yield similar benefits (e.g. 128mb).
Example implementation
Data Structure: A combination of a hash map and a doubly-linked list will be used. The hash map provides O(1) access to the state slots, while the doubly-linked list maintains the order of access.
Overhead Calculation: The overhead for the doubly-linked list and hash map is estimated to be around ~5.5GB for these slots, leading to a total memory usage close to 8GB.
From discussion with Remco Bloemen, Georgios Konstantopoulos and Agustin Aguilar
To clarify, this LRU cache would not necessarily be used by the clients to access this data during execution by itself; it instead serves as an approximation of what the real caching strategy of the node is doing. What I mean is, some nodes may cache more or less; this is not a hard requirement for the node.
I think this value is way too high for Ethereum mainnet, increasing the RAM usage of all clients by ~6 GB seems too disruptive, and most single board nodes would be instantly left out of the network.
2.5 GB could work well for an L2, where node requirements are already expected to be higher. But for Mainnet, I think we should start with a more conservative value. I would suggest something like 128 MB of state or even 64 MB. The required RAM increment would be limited to ~256 MB.
Another important factor is how much state is usually accessed in a single day/week/month in Ethereum. Maybe on a given day, only 5 million different storage slots are changed, and then 90% of the benefits of this proposal could be achieved with a much smaller cache.
Traditional LRU caches are built like this, but I don’t think the proposal should require a specific data structure. The core of the proposal should be (simplifying) something like:
Clients must keep track of the last N accessed storage slots.
Reading/writing these storage slots must have a different gas cost.
I mention this because there are alternative ways of keeping track of this data, for example, using a heap (which would reduce the memory footprint quite a bit, at the expense of more operations when updating the list).
RLU cache would not necessarily be used by the clients to access this data during execution by itself;
Good clarification
Another important factor is how much state is usually accessed in a single day/week/month in Ethereum.
Agreed, possible a smaller cache would deal with the 90% cases well. I proposed larger cache due to lack of data on the topic, but it’s totally arbitrary.
Traditional RLU caches are built like this, but I don’t think the proposal should require a specific data structure. The core of the proposal should be (simplifying) something like:
State slots are 32 bytes in size, but every account has its own independent set of storage slots. So, in reality, this is 20 bytes + 32 bytes. However, I don’t think you need both data points as keys, as the only thing you need to ensure with this LRU is that unique storage slots are priced correctly (without collisions), so a 32-byte hash (of storage slot + address) should be enough.
This optimization should also be left to the clients too. Since using address and slot as key would also work, it would only be more expensive.
I’m curious how this cache would interact with light clients. For instance, would this proposal make it impossible for light clients to do correct gas metering?
Isn’t the problem for all caching strategies that they wouldn’t work if an attacker intentionally makes transactions in a certain way that cannot be cached?
One problem I see with this strategy is that it potentially makes gas estimation much more complicated. Naively, you could have the gas estimator just treat all storage reads as uncached, thus ensuring that it always over-estimates at worst. If you try to do any other strategy you run the risk of gas estimates being wrong if the transaction is not mined quickly for any reason, and thus causing wasted gas on failing transactions (making the problem worse).
I think the naive solution here is fine, but it will be an additional increase in client code complexity, which comes with many hidden long term costs.
Indeed, it’s an annoyance, however I don’t know in practice how frequent this would be because it would only affect the states that are almost evicted. The odds of a user doing a txn containing a slot very close to eviction seems low (especially if the cache is on the larger size), but it would happen once in a while . E.g. if the cache stores ~1 month of state data, you would need to do a txn today for given state and almost exactly 1 month later and then have that state evicted right before your txn is included, but after you submitted it. If cache was tiny, then yes this problem could be more frequent.
A more complex strategy for wallets aligned with this reality would be to detect if state accessed by txn is close to eviction or not and if it is, estimate higher. Doesn’t seem trivial to do client side however.
If you go with the non-naive gas estimation strategy, then you introduce complicated cache flushing attack vectors, where an attacker my do things to cause other people’s transactions to fail due to flushing the cache. While this isn’t necessarily breaking, it adds yet another layer of complexity that needs to be considered when analyzing attacks against/security of Ethereum.
I think there is a middle ground strategy. The node wouldn’t only know if a slot is in the cache or not, but would also know how close to being evicted it is.
Let’s say that we go for a relatively small cache of 5 million slots; the cheapest way for an attacker to evict some slot from the cache would be with an SLOAD. With current gas prices, you could theoretically push approximately 7142 slots into the cache (15,000,000 / 2100) per block. This means that if a slot is among the top 2.5 million (halfway up in the cache), then it would be impossible to evict it in less than an hour, or approximately 350 blocks. In real life, having an hour of blocks that only do SLOADs would be madness, so the real margin is probably around 3 or 6 hours.
So, a good strategy would be to assume that those slots will be in the cache, and slots that are close to being evicted wouldn’t.
An attacker could craft transactions that only access new slots that’re not cached yet. But ok, I was assuming you wanted to generally lower gas cost for accessing slots. But if you still keep the gas estimation for accessing slots at a value that assumes the slot is not cached and then refund gas if the slot is cached it would probably work
Following up our discussion on twitter, I still think LFU (least frequently used) instead of LRU would be better fit, especially for the gas estimation concerns. It would also help with surge periods where there’s many new slots are written. With LFU most highly used apps would be inside the cache (Uniswap, L2 inboxes, etc) and they wouldn’t go out of cache due to surges. It would also greatly reduce evictions.
Problem with LFU is that many old and not used anymore storage slots could stay in the cache for a very long time, while new applications would take a while to get in the cache even if popular when they launch. E.g. Uniswap V1 or old opensea contracts would be cached “forever”.
Also, very popular state slot will stay in the LRU just like an LFU (e.g. Uniswap, L2 inboxes, etc.) since these are touched all the time.
I think the gas improvement is greatly exaggerated. You still have to do writes, you still have to calculate roots, which both also take a long time. Maybe 2x is realistic. Looking at Reth in stage sync (not calculating roots, not saving data to disk!) is not best metric.
Some clients are also using mmap databases that basically would act similar to this kind of cache, while scaling better to available memory. I think this is currently in use in Erigon and/or maybe Reth. In Nethermind we are still experimenting with Paprika, that uses mmap directly to achieve that.
Also keep in mind that having additional few GB’s on the heap puts a lot more effort on garbage collection that is used in Geth, Erigon, Besu and Nethermind.
Overall would like to see real numbers before getting to any conclusions.
I don’t have a great sense after reading this post, which seems interesting on the face of it by the way, what the trade-off curve looks like between the preliminary RAM req numbers you put here vs the expected benefit from such a change?
For example, how much of the benefit outlined would we lose if we took those min RAM requirements down 50%? Is it 1:1, less, more, etc?
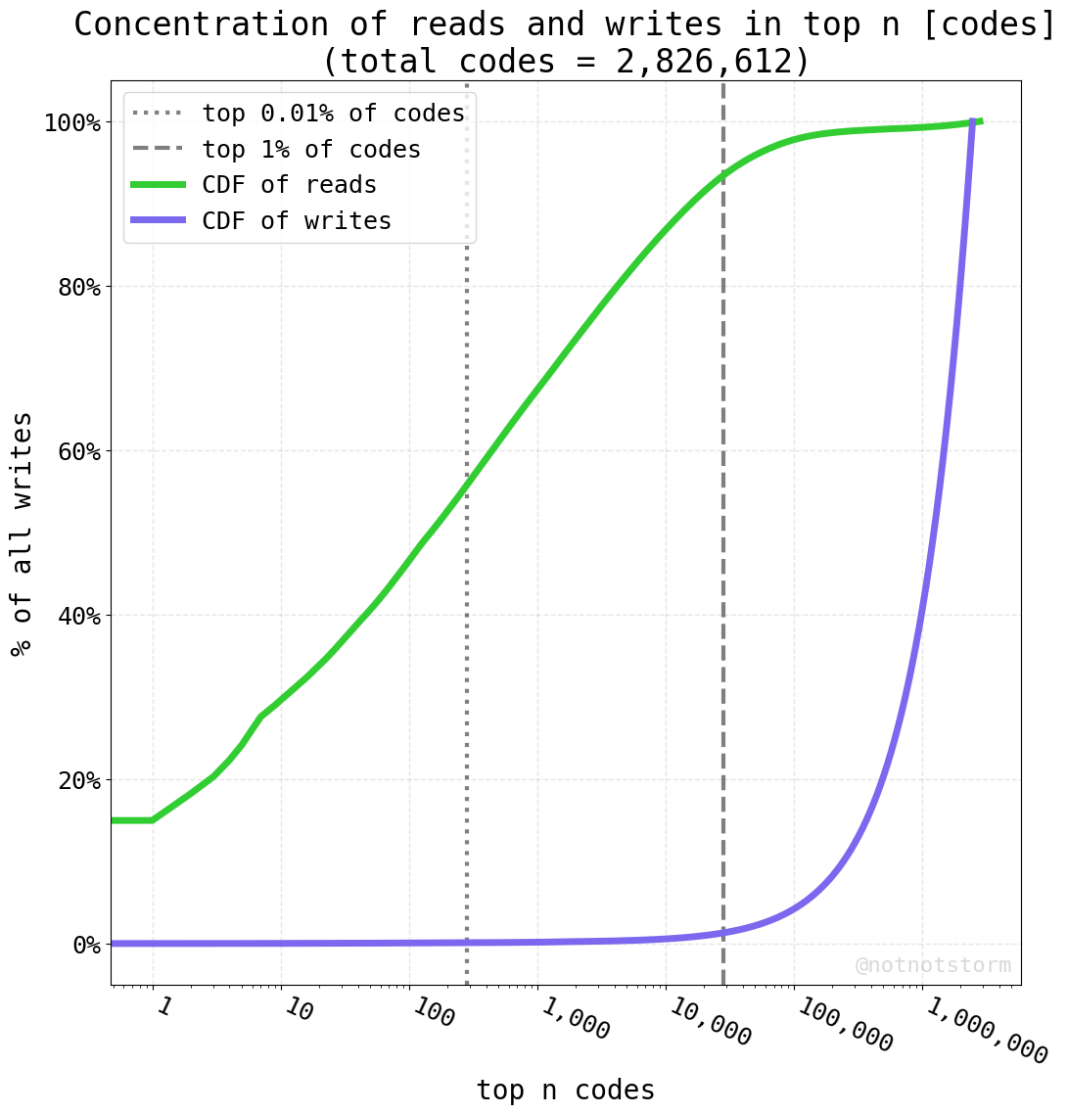
I recently collected some data very relevant to this topic.
This is a summary of state reads + state writes for balances/codes/nonces/slots over ~100 days of recent ethereum mainnet data (~750K blocks)
These tables / charts are derived from parity trace_block stateDiffs for writes and geth debug_traceBlock preState for reads. This means that the data is at the resolution of txs, not opcodes (see overview of tracers here)
Each of these tables/charts is pretty dense and could be stared at for a long time. But the broad strokes are:
most items are accessed a very small number of times
most accesses are concentrated to a very small set of items
if an item is accessed multiple times, those accesses are likely to be close together in time
reads are distributed more top heavy than writes
(This is a first pass. It would be good to further validate the data before using it in production. There are some additional transformations that might be useful, e.g. filtering out the validator balance changes)
Thoughts on the current proposal
Tiering storage costs by frequency of access is a natural thing to do in many contexts. I would love to see something along these lines, especially 1) if cache pricing reflects the reality of how nodes are already accessing this stored data because the pricing would become more accurate, and 2) if this could increase throughput of the network without much increased storage IO burden on nodes.
There’s a big question of how to track access efficiently and whether the benefits outweigh the overhead. Slot reads consume much less gas than slot writes. I would like to see numbers on the expected impact…if we’re talking about trimming gas usage by less than 5% it’s probably not worth the complexity.
Maintaining some well-specified LRU cache logic is one approach. Another approach is just storing the last block height where each slot was accessed and then pricing access according to some recency formula. Another approach is, at the end of a block, give partial gas refunds for any slots that were read by multiple transactions (e.g. slot warmth persists across all txs in block).
I like the relative simplicity of the LRU approach and nodes such as Reth already use a LRU cache for many things. But I would worry about forever locking clients into a suboptimal LRU architecture in case more efficient caching architectures are developed in the future.
LRU is probably a good first pass, but an even more effective algorithm might try to be stickier for the historically top 0.01% - 1% most used items. Whether it’s worth the extra complexity is TBD
After giving it more thought I think it is recipe for reliability and consensus issues disaster. Let me explain: In order to process blocks you need to have the cache built. If you don’t have the cache your gas metering will be wrong and you have consensus issue.So now there are two situations where you don’t have the cache:
Sync - you just synced the state, you would also have to sync the cache. If the cache would be additive only that would be easy, but it is not, elements are also removed from the cache which makes sync complicated - you need to trach items order too.
Restarts/shutdowns - You can break restarts into:
a) clean shutdowns - should we persist the cache? Persisting few GB of data would take quite some time, easy to misconfigure when your docker or OS gives you 30s to shutdown by default. Loading them again on startup takes time too.
b) crashes - ok we crashed and we don’t have the cache. What can we do? Only way is to sync them from network - what if a large part of the network just crashed due to some bug? Ugh…Based on this I think this is not a practical solution at all and there are better experiments with what to do with the state, so it can be more in-memory while not changing any consensus rules. And then we could just increase gas limit!But the main problem with increasing gas limit is size of storage. And it is not size of state! The main problem now is size of Blocks and Receipts, which would grow even faster. And for that EIP-4444 is more important.