I recently collected some data very relevant to this topic.
This is a summary of state reads + state writes for balances/codes/nonces/slots over ~100 days of recent ethereum mainnet data (~750K blocks)
These tables / charts are derived from parity trace_block stateDiffs for writes and geth debug_traceBlock preState for reads. This means that the data is at the resolution of txs, not opcodes (see overview of tracers here)
High level summary
For each datatype this table shows:
- the number of reads
- the number of writes
- the ratio of reads:writes
- the number of underlying items
- the mean number of reads+writes per items
┌───────────────────────────────────┐
│ Summary of State Reads and Writes │
└───────────────────────────────────┘
│ │ │ │ │ mean │ mean
│ │ │ │ │ reads │ writes
│ │ │ r:w │ │ per │ per
│ # reads │ # writes │ ratio │ # items │ item │ item
────────────┼───────────┼────────────┼─────────┼───────────┼─────────┼──────────
balances │ 514.5M │ 296.4M │ 1.7 │ 21.0M │ 24.4 │ 14.1
codes │ 246.6M │ 2.5M │ 99.3 │ 2.8M │ 87.2 │ 0.9
nonces │ 482.6M │ 121.3M │ 4.0 │ 13.3M │ 36.2 │ 9.1
slots │ 1.2B │ 340.3M │ 3.5 │ 151.4M │ 7.8 │ 2.2
At what rate does each operation occur?
This table shows the rate of reads/writes for balances/codes/nonces/slots on the timescales of seconds/blocks/days/years:
┌───────────────────────────┐
│ Rates of Reads and Writes │
└───────────────────────────┘
│ │ mean │ mean │ mean │ mean
│ │ per │ per │ per │ per
│ action │ second │ block │ day │ year
────────────┼──────────┼──────────┼───────────┼─────────┼──────────
balances │ reads │ 56.3 │ 680.6 │ 4.9M │ 1.8B
│ writes │ 32.4 │ 392.1 │ 2.8M │ 1.0B
codes │ reads │ 27.0 │ 326.1 │ 2.3M │ 850.1M
│ writes │ 0.3 │ 3.3 │ 23.5K │ 8.6M
nonces │ reads │ 52.8 │ 638.4 │ 4.6M │ 1.7B
│ writes │ 13.3 │ 160.5 │ 1.1M │ 418.3M
slots │ reads │ 129.3 │ 1,564.6 │ 11.2M │ 4.1B
│ writes │ 37.2 │ 450.2 │ 3.2M │ 1.2B
How many times does each item get read or written?
Most items are read/written in just a single block:

For an item that is accessed across multiple blocks, what is the typical interval size between reads or writes?
Most interblock intervals are <10 blocks, and much shorter for certain datatypes:

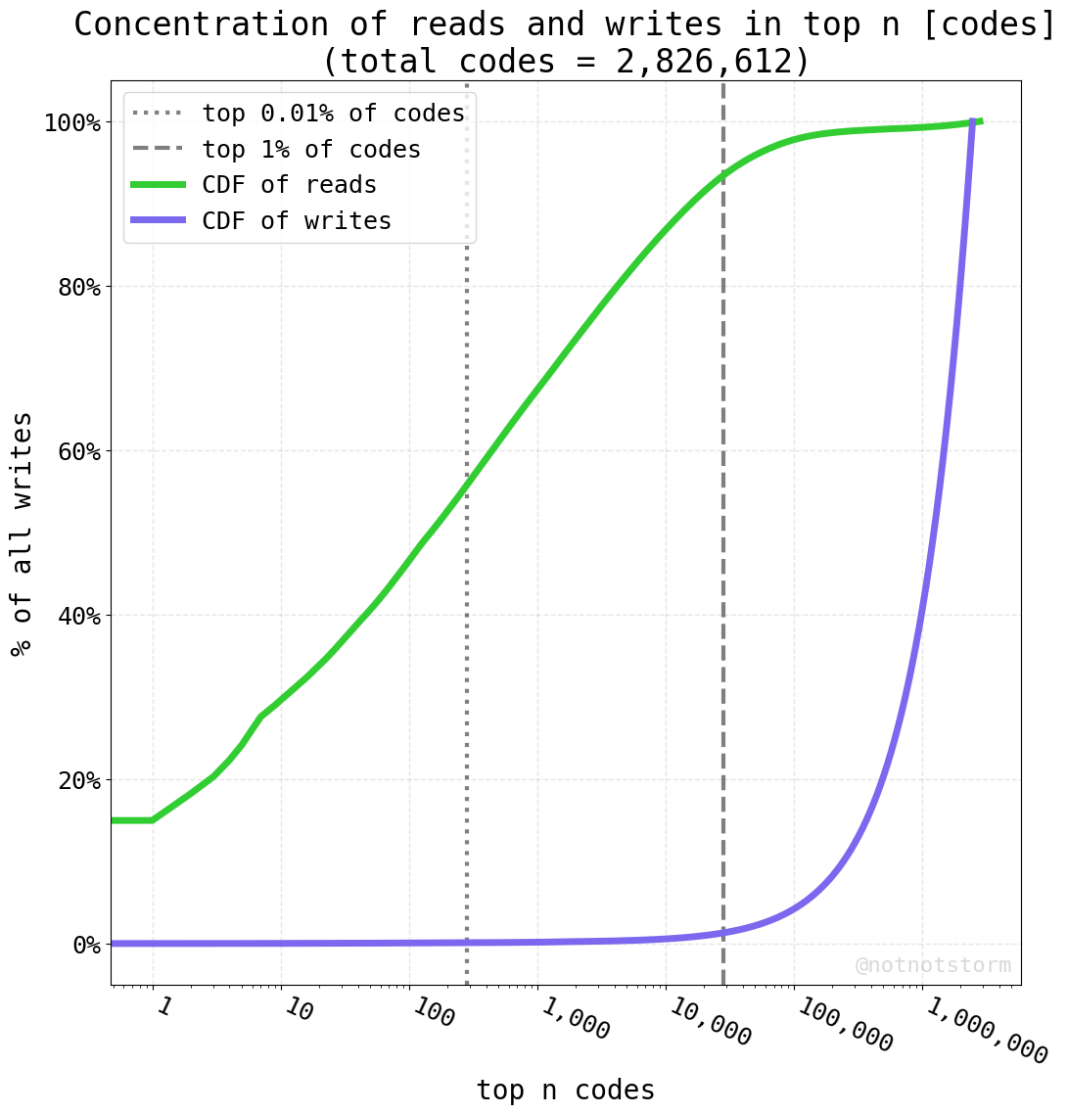
Are reads/writes concentrated to a small number of addresses?
This depends on datatype, for all datatypes, >50% of reads/writes are in < 0.01% of the underlying addresses, sometimes much smaller:



Data Summary
Each of these tables/charts is pretty dense and could be stared at for a long time. But the broad strokes are:
- most items are accessed a very small number of times
- most accesses are concentrated to a very small set of items
- if an item is accessed multiple times, those accesses are likely to be close together in time
- reads are distributed more top heavy than writes
(This is a first pass. It would be good to further validate the data before using it in production. There are some additional transformations that might be useful, e.g. filtering out the validator balance changes)
Thoughts on the current proposal
- Tiering storage costs by frequency of access is a natural thing to do in many contexts. I would love to see something along these lines, especially 1) if cache pricing reflects the reality of how nodes are already accessing this stored data because the pricing would become more accurate, and 2) if this could increase throughput of the network without much increased storage IO burden on nodes.
- There’s a big question of how to track access efficiently and whether the benefits outweigh the overhead. Slot reads consume much less gas than slot writes. I would like to see numbers on the expected impact…if we’re talking about trimming gas usage by less than 5% it’s probably not worth the complexity.
- Maintaining some well-specified LRU cache logic is one approach. Another approach is just storing the last block height where each slot was accessed and then pricing access according to some recency formula. Another approach is, at the end of a block, give partial gas refunds for any slots that were read by multiple transactions (e.g. slot warmth persists across all txs in block).
- I like the relative simplicity of the LRU approach and nodes such as Reth already use a LRU cache for many things. But I would worry about forever locking clients into a suboptimal LRU architecture in case more efficient caching architectures are developed in the future.
- LRU is probably a good first pass, but an even more effective algorithm might try to be stickier for the historically top 0.01% - 1% most used items. Whether it’s worth the extra complexity is TBD