Co-authored by Michael and Kubi (Gattaca). Special thanks to Thomas, Julian, Toni, Ladi, Justin, Auston and Max for their feedback and suggestions. Feedback is not necessarily an endorsement.
Overview
This document introduces relay inclusion lists (rILs), a way to immediately improve Ethereum’s censorship resistance without introducing protocol changes, new trust assumptions, or significant technical complexity. The design is intended as a new default feature for non-censoring relays, with an opt-out option provided to accommodate validator preference.
We proceed by detailing how relay inclusion lists increase Ethereum’s censorship resistance while preserving validator’s risk-reward balance. We then propose a rule for constructing relay inclusion lists that is efficient and resilient to outlier values, alongside enforcement procedures that integrate seamlessly with existing block validation. The document concludes with an outlook on promising future directions.
Overall, the document details the exact procedures for generating, validating, and enforcing inclusion lists in the relay. It reflects the EIP-7805 (FOCIL) specifications to ensure protocol compatibility and operational integrity, preparing the block production system for a future in-protocol implementation of inclusion lists in a risk-off manner.
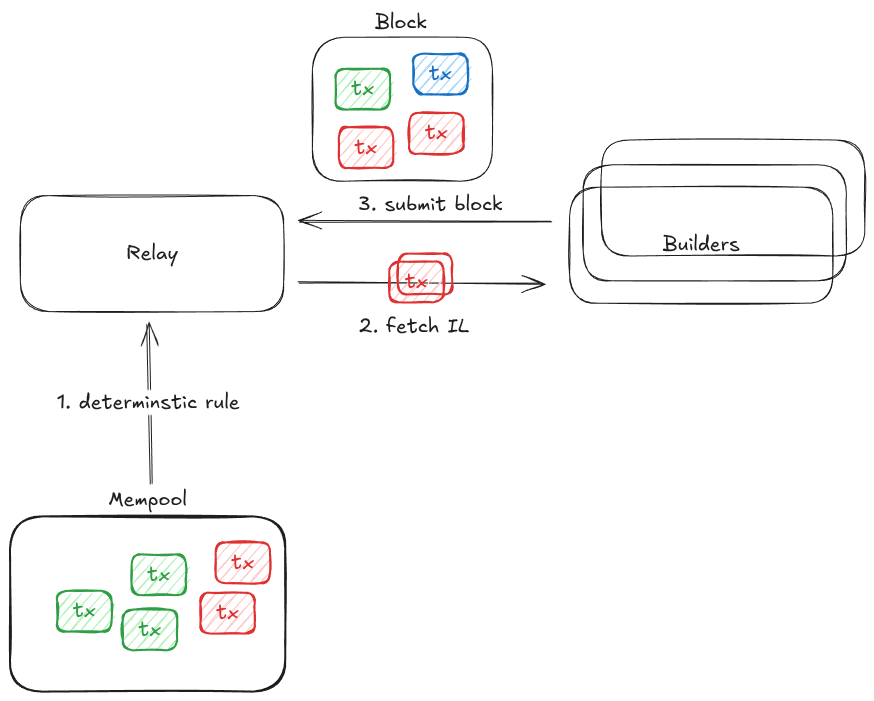
Distribution and roll-out
Relays supporting relay inclusion lists will by default generate and enforce an inclusion list from transactions pending in the mempool for all blocks they deliver. Validators that wish to opt-out may do so by explicitly indicating this preference through the relay registration API, as an additional preference field.
Relay inclusion lists empower validators to immediately improve Ethereum’s censorship resistance without incurring any additional risk or trust assumptions, as the compilation and enforcement of the inclusion list is delegated to the relay, with the validator remaining blind to its contents upon signing the block header. An alternative out-of-protocol approach is IL-Boost, which delegates block building but retains inclusion list construction at the proposer level.
We note that the system is consistent with validator’s economic incentives. In practice, it will reflect as fuller blocks, which come with a minor latency trade-off due to their larger data footprint. In the case where all relays adopt the design, this trade-off will be minimized on a relative basis, as the bid curve will shift to accommodate this marginal and predictable latency overhead; put another way, the best bid is submitted earlier. In the case where some relays do not adopt the design, validators are insured through the standard block auction, which will continue to yield the highest-paying block.
Overall, the design does not impose additional requirements on validators, and allows them to improve Ethereum’s censorship resistance without shifting on the risk/reward curve. For this reason, the system is accessible and attractive to all participants, from solo stakers to large node operators.
Inclusion List Generation and Communication
Relays independently generate inclusion lists from mempool transactions by applying a deterministic inclusion rule. The core purpose of the rule is to maximize the predictability of inclusion by observing the mempool only; specifically, the arrival times and priority fees of pending transactions.
We propose an initial, simple two-step rule:
-
Normalize waiting time and priority fee:
For each transaction t in the mempool, compute:
S_w(t) = \frac{w(t)}{\tilde{w}}, \quad S_f(t) = \frac{f(t)}{\tilde{f}}
where:
- w(t) is waiting time of transaction t in the mempool.
- f(t) is the priority fee of transaction t.
- \tilde{w} and \tilde{f} are the medians of the waiting times and priority fees respectively, for all transactions pending in the mempool.
-
Compute total score and adjust for transaction size:
Each transaction is initially assigned a total score:
S(t) = S_w(t) + S_f(t)
The score S(t) is then size-adjusted to provide higher marginal pricing for large transactions:
D(t) = \frac{S(t)}{size(t)}
where size(t) is the transaction’s size measured in bytes. Transactions are then ranked in descending order of D(t).
The relay then builds an inclusion list with a maximum size of 8 kilobytes, in adherence to the EIP-7805 (FOCIL) specifications, by including the top-ranked transactions until there is insufficient marginal space for a further inclusion.
Normalizing via the median avoids skew from transactions that have not seen inclusion for economical reasons, i.e. due to underpayment. The rule is computationally efficient, as median calculation and transaction sorting can be performed quickly for typical mempool sizes using standard algorithms. An adversary attempting to grief the median by spamming low fee transactions would simply increase the prioritization score of other transactions; a simpler and cheaper way of reaching inclusion would just be to pay more.
Ranking the transactions by the density score imposes a higher marginal price per unit of blockspace consumption. This market-based approach incentivizes the inclusion of many smaller transactions, thereby maximizing participation from as many originators as possible. Large transactions, which consume more blockspace, can still be included quickly by increasing their priority fee accordingly.
Uniform application of the inclusion rule across all relays is desirable; in practice, it is most important that each relay fills the inclusion list to its maximum size (given sufficient transactions in the mempool), to preclude skewed IL implementations optimizing for latency (i.e. lean blocks). Relay behaviour is enforced via proposers, which may elect to opt out of relays that optimize for factors other than censorship resistance. The inclusion rule is economically rational and incentive-aligned by taking into account priority fees.
The inclusion list is computed before the beginning of each slot, and the relay exposes an HTTP API endpoint that builders use to fetch the completed inclusion list. There are no sorting constraints imposed on builders; transactions on the inclusion list can be sorted into the block in the most efficient way.
Block Validation and Enforcement
Block validity is enforced against the FOCIL criteria; specifically, a block proposed to the relay is valid if and only if the following conditions are fulfilled:
- Transaction Inclusion Check
- Every transaction listed in the IL provided by the relay is either:
- Included explicitly in the block delivered by the builder.
- Verifiably invalid after executing against the block’s resulting post-state.
- Simulated Transaction Validation
- The Relay simulates execution of each IL transaction not included in the block against the block’s post-state.
- A block is invalid if it omits any inclusion‑list transaction that would, when validated against its resulting post‑state, pass all pre‑execution validity checks—correct signature, chain ID, nonce, sufficient balance, and intrinsic gas.
- Transactions failing simulation due to inherent invalidity (e.g., nonce mismatch, insufficient balance) do not invalidate the block.
- Simulation and verification of the IL is done in the simulation part of block verification.
This approach fits the FOCIL criteria to the current off-chain PBS pipeline without introducing additional stages; the block simulation is simply marginally extended by one transaction for each IL transaction not included in the block. In the case of optimistic relaying that skips the simulation stage for trusted builders, no overhead is incurred.
Enforcement and Penalties
As per the FOCIL criteria, compliance with the inclusion list is treated as a validity condition. Non-compliance results in non-acceptance at a minimum, and in the case of optimistic builders, a penalty may be enforced.
We propose that the penalty enforced against non-compliant optimistic builders should reflect the IL as an integral validity condition, and lead to forfeiture of the block value against the builder’s collateral. Relays may elect to demote non-compliant builders temporarily, until the error has been traced, to avoid excess collateral burn.
Future Directions
Inclusion Lists for Blob-Type Transactions
In the future, the design may be extended to encompass blobs. This would widen the censorship resistance of the current design while improving timely data availability for L2s.
Larger Inclusion Lists
Relay inclusion lists can be larger than proposer-centric inclusion lists, as they are not directly bottlenecked by validator bandwidth constraints. The present design mirrors FOCIL sizing to ensure blocks with relay ILs are competitively priced in the PBS auction, and can in the future be expanded to accommodate a larger total size.
Multi-Relay Inclusion Lists
Under the present design, each relay maintains its own inclusion list. Builders seeking to retain maximal optionality for their blocks may choose to send a different block to each relay, reflecting the IL provided by the relay.
In the future, even stronger censorship guarantees may be achieved by forming an inclusion list from the intersection of multiple inclusion lists. This ensures fair competition between relays by enforcing uniform application of the inclusion rule, and can be easily computed over the transaction ranking used to compile the inclusion list. This would also reduce redundancy for builders, by removing the need to compute tailored blocks per relay, or to include a union of inclusion lists.
In such a case, each relay could gossip an extended list, which is then deterministically reduced to a uniform standard-sized list by taking the intersection. In practice, this may be achieved by upgrading relays with a simple gossip protocol.
Links