Snap v2: Replacing Trie Healing with BALs
Special thanks to Gary for feedback and review!
Snap sync (snap/1) dramatically improved node sync when it launched in Geth v1.10.0. But it has a well-known Achilles’ heel: the trie healing phase, an iterative process where syncing nodes discover and fix state inconsistencies one trie node at a time. This phase has caused nodes to get stuck healing for days or weeks and has been identified as something the community wants to eliminate.
With EIP-7928 (Block-Level Access Lists), a new approach becomes possible: replace trie healing entirely with sequential BAL application. This post explains how snap sync works today, what makes trie healing problematic, and how a proposed snap/2 protocol upgrade would fix it.
Part 1: How Snap Sync Works Today
The problem snap sync solves
A new Ethereum node needs the current state: every account balance, storage slot, and contract bytecode. This state lives in a Merkle Patricia Trie with the account trie saturated at a depth of about 7 levels (EF blog: Snapshot Acceleration), containing hundreds of millions of nodes.
The old approach (“fast sync”, eth/63–66) downloaded this trie node by node from the root. At block ~11,177,000, the state contained 617 million trie nodes, and syncing them required downloading 43.8 GB of data distributed over 1,607M packets, resulting in a total of ~10h 50m of sync time.
Snap sync’s key insight: skip the intermediate trie nodes entirely and download the leaves (accounts, storage) as contiguous ranges, then rebuild the trie locally. This requires serving nodes to maintain a dynamic snapshot, a flat key-value store that can iterate accounts in ~7 minutes versus ~9.5 hours for raw trie iteration (see snap.md).
Comparing fast-sync with snap sync, we got the following improvements:
| Metric | Fast sync | Snap sync | Improvement |
|---|---|---|---|
| Download | 43.8 GB | 20.44 GB | -53% |
| Upload | 20.38 GB | 0.15 GB | -99.3% |
| Packets | 1,607M | 0.099M | -99.99% |
| Serving disk reads | 15.68 TB | 0.096 TB | -99.4% |
| Time | 10h 50m | 2h 6m | -80.6% |
Note: These benchmarks are from block ~11.2M (late 2020). The state has grown since, but the relative improvements remain representative. Modern snap sync typically takes 2–3 hours total on good hardware.
The three phases
Snap sync proceeds in three phases:

Phase 1 - Header Download: Uses the eth protocol to download all block headers, building a verified chain. The CL drives the EL, which means the first HEAD is received from the CL and the EL then downloads all parent headers starting from the latest header and moving backwards.
Phase 2 - State Download: The node picks a pivot block P (typically HEAD−64) and downloads the complete state at P:
GetAccountRange(0x00): Download accounts in contiguous hash ranges, each response Merkle-proven at the boundaries to prevent gap attacksGetStorageRanges(0x02): Download storage slots for contracts, with multiple small contracts batchable into one requestGetByteCodes(0x04): Download contract code, verified by codehash comparison
Each response is capped by byte size (not count) for predictable bandwidth, and different peers can serve different ranges concurrently. Serving nodes keep snapshots for the most recent 128 blocks (~25.6 minutes at 12 seconds per slot).
The pivot block is a block far enough in the past from the tip of the chain to ensure that we don’t download state that is the result of a block that is later reorged. 64-block deep reorgs are practically impossible. Even if such a reorg occurs, the already downloaded state does not need to be discarded and can be repaired by iteratively fetching the required trie nodes.
Crucially, as each state range is received, the node rebuilds and persists the intermediate trie nodes for that segment locally rather than fetching them over the network. By the end of Phase 2, the bulk of the trie is already correctly constructed, significantly reducing the healing workload to only fixing nodes made inconsistent by state changes that occurred during the download window.
Phase 3 - Healing: While Phase 2 is running, the chain advances from the pivot block P to P+K, turning the downloaded state stale. Healing fixes this, but it’s also where a problem begins.
How trie healing works
The healing phase uses GetTrieNodes (0x06) / TrieNodes (0x07) to iteratively discover and fetch changed trie nodes:

Why trie healing is the bottleneck
- Iterative discovery. Syncing nodes don’t know what changed until they look. Each round of
GetTrieNodesreveals the next set of differences, requiring another round trip. This is fundamentally sequential. - Small payloads, many round trips. Individual trie nodes are 100–500 bytes. Even batched, the data per round trip is tiny relative to network latency.
- Moving target. With 12-second slots, about 1,000 trie nodes are deleted and 2,000 added per block. Healing must outpace this or it will never converge.
- Random disk access. Serving
GetTrieNodesrequires random database reads. This is expensive compared to the sequential reads used byGetAccountRange. - Progress is unknowable. As Geth documentation notes: “It is not possible to monitor the progress of the state heal because the extent of the errors cannot be known until the current state has already been regenerated.”
The real-world impact can be severe. Examples include nodes being stuck for 2+ weeks while healing (43 million trie nodes, 11.7 GiB downloaded; throughput degraded to ~2 trie nodes/second), being stuck for 4 or 6 days during healing.
The at-launch benchmark showed healing adding ~541,260 trie nodes (~160 MiB) at block ~11.2M, but with today’s larger state and higher block gas limit, the healing burden is already substantially heavier, and will worsen with further gas limit increases.
Part 2: Block-Level Access Lists (BALs)
EIP-7928 introduces Block-Level Access Lists (BALs): data structures recording every account and storage location accessed during block execution, along with post-execution values. Each block header commits to its BAL via a new block_access_list_hash field placed in the block header:
block_access_list_hash = keccak256(rlp.encode(block_access_list))
A BAL contains, for every accessed account:
- Storage changes: per-slot post-values, indexed by which transaction caused the change
- Storage reads: slots read but not modified
- Balance/nonce/code changes: post-transaction values
BALs are RLP-encoded, deterministically ordered (accounts lexicographically by address, changes by transaction index), and complete. State diffs are a subset of the BAL and can therefore be used to assist during sync.
BAL sizes
Empirical analysis of 1,000 mainnet blocks at a 60M block gas limit showed that BALs are ~72.4 KiB on average.
Nodes must retain BALs for at least the weak subjectivity period (up to 3,533 epochs, ~15.7 days at today’s validator set size).
Part 3: snap/2: BAL-Based State Healing
Instead of iteratively discovering and fetching trie nodes, snap/2 inverts the snap/1 pattern. In snap/1, the trie is built incrementally during download and the flat state is derived from it. In snap/2, only the flat state (leaves) is synced, BAL diffs are applied directly to it, and the trie is rebuilt once from the complete state, eliminating incremental trie construction and the complex healing it requires.
Concretely, instead of iteratively discovering and fetching trie nodes, nodes download the BALs for every block that advanced during sync and apply the state diffs sequentially. The set of blocks is known upfront. Each BAL is verified against its header commitment. This eliminates the need for iterative discovery.
snap/2 removes the trie healing messages and replaces them with BALs, reusing the same message IDs:
| ID | snap/1 | snap/2 |
|---|---|---|
| 0x00–0x05 | Account/storage/bytecode download | Unchanged |
| 0x06 | GetTrieNodes |
GetBlockAccessLists |
| 0x07 | TrieNodes |
BlockAccessLists |
Note that reusing the message IDs is safe because snap/2 is a new protocol version negotiated during the RLPx handshake. snap/1 peers never see snap/2 messages.
The new messages
GetBlockAccessLists (0x06):
[request-id: P, [blockhash₁: B_32, blockhash₂: B_32, ...]]
BlockAccessLists (0x07):
[request-id: P, [block-access-list₁, block-access-list₂, ...]]
- Nodes must always respond
- Empty entries (zero-length bytes) for unavailable BALs
- Responses preserve request order and may be truncated from the tail
- Recommended soft limit set to 2 MiB per response, which is consistent with existing messages, e.g. blocks, headers or receipts.
The new sync algorithm

Notably, since BALs are guaranteed to be correct by consensus (BAL hash check against canonical blocks), the state roots are guaranteed to match; thus, clients could even skip the final state root comparison step.
Why this works
With snap/2, the healing window is bounded and known. For a pivot at HEAD−64:
- 64 blocks × ~72.4 KiB (projected 60M gas) ≈ 4.5 MiB total BAL data
- Fits in 2–3 responses at the 2 MiB soft limit
- Serving BALs requires only a few disk lookups instead of a lookup for every changed trie node
- 1–3 total round trips (including any “tail” blocks that arrive during application)
- Extracting the state diff from the BAL is purely local computation. There’s no need for trie traversal.
Compared to snap/1, snap/2’s healing is more efficient, requiring fewer disk reads and round trips. With snap/2, at least in theory, it should become impossible for the chain to outpace sync.
Relationship with eth/71
EIP-8159 adds BAL exchange to the eth protocol as messages 0x12/0x13. Both exist for different reasons:
| eth/71 | snap/2 | |
|---|---|---|
| Purpose | Recent BALs for parallel execution, reorg handling | Sync: bulk BAL download during healing |
| Volume | 1–3 BALs at a time | Multiple BALs at a time |
| Protocol | Mandatory for all nodes | Optional satellite protocol |
Messages are duplicated in eth/71 and snap/2 to ensure snap stays a self-contained satellite protocol and to allow snap to evolve independently, for example, serving only state diffs instead of full BALs in a future version, without requiring changes to eth.
Part 4: Comparison
Healing phase: snap/1 vs snap/2
| Property | snap/1 (trie healing) | snap/2 (BAL healing) |
|---|---|---|
| Discovery | Iterative: nodes don’t know what changed until they look | Deterministic: blocks P+1..P+K are known upfront |
| Round trips | Hundreds+ (issues report millions of trie nodes) | Final number TBD, but estimated to be only a few |
| Verification | Complex trie reconstruction + root comparison | keccak256(rlp(bal)) == header.block_access_list_hash |
| Moving target | Each healing round + chain advance → more healing | BAL application is local and fast; tail is tiny |
| Convergence guarantee | Weak: healing must outpace chain growth | Strong: deterministic, bounded work |
The complete flow, comparing snap/1 with snap/2, looks like the following:
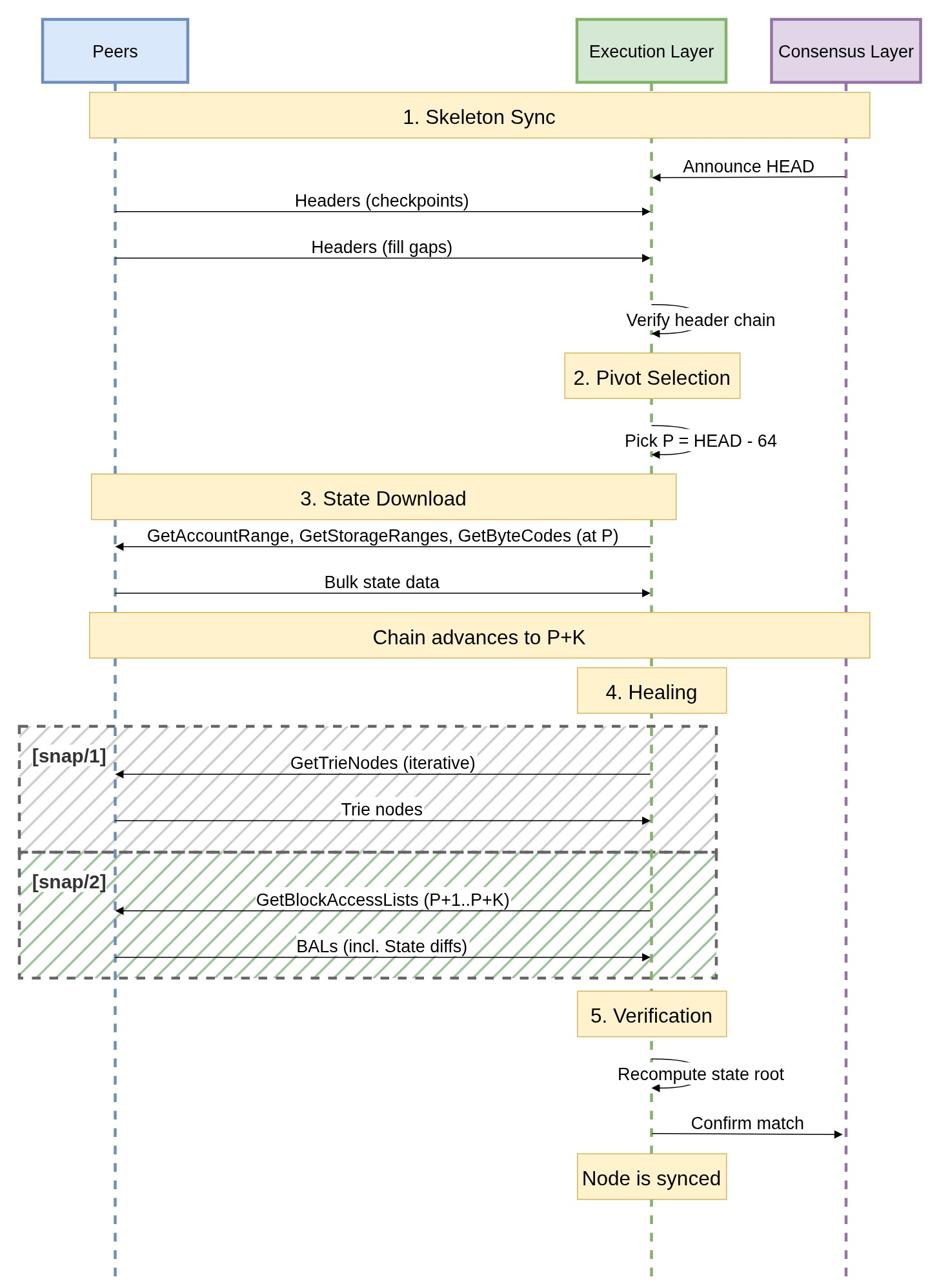
Failure modes
| Failure | snap/1 | snap/2 |
|---|---|---|
| Healing can’t converge | Real risk: trie healing is slow enough for chain to outpace it | Nearly eliminated: only BAL download needs network |
| Unavailable data | None: snap/1 only requires healing to outpace the chain | The weak subjectivity period (~15.7 days) is generous |
| Bad data | Merkle proofs catch bad trie nodes | Hash comparisons catch bad BALs |
| Reorg past pivot | Recoverable: trie healing resolves state against the new canonical chain | Recoverable if orphaned BALs are retained; otherwise requires sync restart |
A concrete example
Consider a pivot at block 22,000,000 with the chain 200 blocks ahead when state download completes:
snap/1: Start trie traversal from block 22,000,200’s state root. Each round discovers more differences, goes deeper. Meanwhile, multiple new blocks arrive during healing. In the best case, this takes minutes; in pathological cases (slow disk, slow network), it has taken days.
snap/2: Request BALs for multiple blocks. At a 60M block gas limit, that’s ~4–5 MiB, which fits in a few responses. Apply the BALs locally, optionally verify the state root matches. A few more blocks arrived during application? Fetch 2–3 more BALs. Total: 2–3 round trips, seconds to complete.
Further Reading
- Ethereum Snapshot Protocol (snap/1) — devp2p spec
- Ethereum Wire Protocol (eth) — devp2p spec
- EIP-7928: Block-Level Access Lists
- EIP-7928 BAL Size Analysis (empirical, 30M gas)
- EIP-8159: eth/71 — Block Access List Exchange
- Geth Sync Modes documentation
- Geth FAQ — state healing
- Ask about Geth: Snapshot Acceleration — EF Blog
- Geth v1.10.0 release — EF Blog
- Weak Subjectivity — Ethereum Consensus Specs
- Block-level Access Lists (BALs) — ethresear.ch
- go-ethereum #23191: State heal phase very slow (2+ weeks)
- go-ethereum #25945: Stuck healing for 4 days
- go-ethereum #25898: State heal since 6 days
- go-ethereum #27692: Get rid of snap sync heal phase
- Nethermind Sync Modes documentation
- Proof-of-stake (12s slots) — ethereum.org