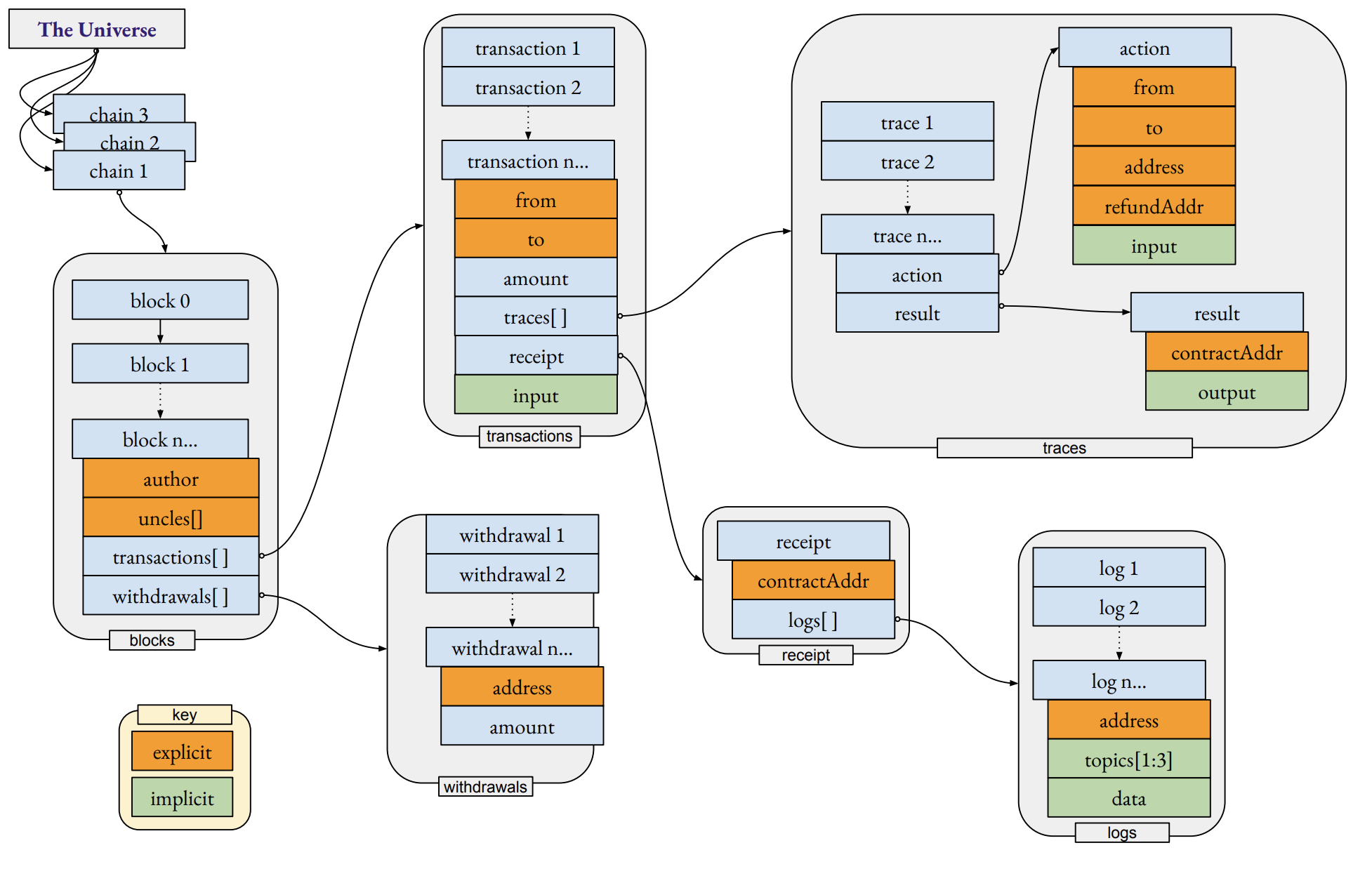
We (TrueBlocks) recently released version 2.0.0 of the Unchained Index spec. I thought I’d share here seeking feedback, comments, suggested improvements, questions. Please enjoy.
I’ve always thought that indexing of “address appearances” should be (and always should have been) part of the node software (i.e., --index_appearances command line option). This spec tries to spell out as clearly as possible how that might be accomplished.
I question the deeply ingrained beliefs that (a) index takes up too much time and space, (b) as a result of (a), indexing should be outside of the node, and (c) as a result of (b), indexing must be incentivized. I don’t think any of these three “sacred” beliefs is true.
I think step 1 would be to show that (a) is not true. Assuming optimal storage layout on-disk using your proposed solution, how much disk space does this index consume?
There’s two components to the chunked index: (1) bloom filters, and (2) appearance index. The appearance index takes up about 100GB for mainnet Ethereum. The bloom filters takes up about 4GB. We keep a “manifest” of the IPFS hashes for the Blooms and the Index portions for each chunk (there are about 4,000 chunks for Ethereum mainnet, which means around 8,000 total files).
A user can build the index and keep only the Blooms and then query an address, reference the manifest, and download or build the index portion.
So…in answer to your question: either 4GB for Blooms only, 110 GB for Blooms plus Index portions, or anywhere in between depending on how heavily the user queries for which addresses.
It designed to be maximally small so it works on laptops, but also maximally detailed (so it finds every appearance of every address) and maximally re-distributable through regular usage without any “extra action” on the part of the end user (the user only needs the index chunks for that part of the index he/she is interested in.)
And, as an added bonus, if someone has any part of the index, they can pin it to IPFS making each portion more and more available the more people use it.
I recommend pushing this forward with the 4GB requirement for the protocol, and IPFS access to the rest of the data with optional local caching of the data if the client/user wants. I think you may be able to sell a 4GB increase in disk size for an index (assuming you can convince people the index is useful), but I doubt you’ll be able to sell a 110GB increase in disk size.
I should have mentioned a few other things. (1) this can be totally optional, so there would be no requirement that requires anything from the node, (2) if it were required, it would be amazing for it to be part of the protocol (but I’m not suggesting that–but it would be amazing), (3) I envision some sort of command line option: --index blooms or --index appearances, again optional.
Also, there’s a half-step that would require exactly zero additional disc space but provide a huge benefit to anyone wishing to build their own index: an RPC endpoint called something like eth_AppearancesInBlock. (This is fully described in the document.) This is basically what we do outside the node using already available RPC endpoints (mostly trace_block) which means it works. It’s also very performant. One can build the entire index of appearances for mainnet on a reasonably powerful Mac laptop in just over a day. It requires no disc space and could be used by people to build an off-chain index for themselves.
As far as useful I point you to the fact that almost everyone I know spends a ton of time and money trying to get an accurate transactional history of their accounts to no avail. Without accurate transactional histories, doing anything even approaching automated accounting is impossible. (If you’re missing transactions, the chances of reconciling your accounts is zero.)
Our scraper builds a collection of minimally sized binary files (about 2,000,000 appearances per file). Each file (or chunk) is more easily shared (and thereby automatically sharded) using IPFS (each user can query, download and re-pin only what they’re interested in).
Two articles describing why our index is more complete than any other (and why I think it’s super useful given the above claim it can do perfect accounting:
If all of the clients added the 4GB bit (but not the 100GB bit), and a user had access to an Ethereum client + an IPFS node, would they be able to get their own transaction history without needing any other third party services or indexes and without needing to trust anyone else? Their IPFS client would need to make external requests for certain shards IIUC, but they wouldn’t need to trust anyone for those shards?
If my understanding is correct there is a small risk of correlational doxxing in this setup as someone could look at which shards a user downloaded, but someone who was concerned about this could simply download all of the shards presumably?
If all of the clients added the 4GB bit (but not the 100GB bit), and a user had access to an Ethereum client + an IPFS node, would they be able to get their own transaction history without needing any other third party services or indexes and without needing to trust anyone else?
Yes. If the address hits the Bloom, (which they would consult locally), they can grab the IPFS of the manifest from the smart contract. In that manifest, they can find the IPFS hash of the larger index portion, download that from IPFS, and get the account’s history in that chunk. All local. No third party. (This assumes there are enough copies on IPFS to make locating the larger index pieces performant. One may have to resort to a gateway until there are enough copies.)
Or they could build the index themselves from their own locally running node.
I’m not sure how they would be doxxing themselves. There’s 2,000,000 appearance records in each chunk, so even if they downloaded 10 larger portions, there would be a massive number of addresses in all 10 making it impossible to identify exactly which one that particular user was. (I think…open to discussion here.)
How many chunks are generated per year (on average)? My suspicion is that the number of accounts in a particular sub-set of chunks approaches 1 quite rapidly. Keep in mind that any accounts that are in the same chunks as your account while also being in others can be removed from the set. This could be partially mitigated by having the client download a bunch of random chunks along with the ones they actually want, but that is more bandwidth/time for the person building the local account history.
I understand this can be used to fetch users erc20/erc721 logs. How do you identify addresses in these logs? As the data in logs can be what ever, and if you dont have contracts ABI, you cannot be sure what is an address and what is something else.
For clarity, I believe this will just tell you that a user was part of that transaction, but it won’t tell you that it was an ERC20/ERC721 transfer. Once the dapp has the transaction, it is up to it to decode the log to figure out what happened.
This is such an excellent question and EXACTLY the one we answered in our work. Of course, theoretically, it’s impossible, but we do an “as best as we can” approach. Please read the sections of the document mentioned above called “Building the Index and Bloom Filters.” The process is described in excruciating detail there.
The index itself is SUPER minimal on purpose, so it stays as small as possible. With the index, you can then use the node itself as a pretty good database. (We claim the only thing missing from the node to make it a passable database is an index.)
To get the actual underlying details of any given transaction appearance, we have a tool called chifra export which has many options to pull out any particular portion of the node data given the list of appearances.
For example, we have chifra export <address> --logs --relevant which gets any log in which the address appears. Another example is chifra export <address> --neighbors which shows all addresses that appear in any transaction that the given address appears (helps find Sybils for example).
Upshot – the index is only for identifying appearances. Other tools can be used to get the actual underlying details for further processing.
Of course, it depends on usage. We tried to target about 2 chunks per day, but to be honest, I’ve not looked at it for a while. The number of included appearances in a chunk is configurable, and to be honest, we’ve not spent much time on this. 2,000,000 was an arbitrary choice that balances the number of times a chunk was produced per day, the size of the chunks in bytes (we tried to target about 25MB – also arbitrary). There’s a lot of opportunity to adjust/optimism, but it’s not been our focus due to resource limitations.
Concerning being able to doxx someone given which chunks they download. I tried to do some back of the envelope calcs, and it was a bit beyond my mathematical abilities. I too, however, started to think it might be easier than it seems.
Currently, there are about 4,000 chunks for Eth mainnet.
Hmm, does this mean that to get at the appearances in traces you would need a full archive node? Is there a way to say “don’t include traces in the index, because I can’t reasonably recover them later”?