The more I think about full statelessness (stateless ethereum where even the miners hold no state), the more worried I get. Here’s a first post with one of the difficulties I see, I hope to follow it up with more posts in the future:
It’s possible to construct a transaction which consumes a lot of gas before trying to access a state which the witness did not prove. If this was allowed to happen then it would be easy to DOS miners. Ethereum usually handles this situation with reverts, the transaction is included in the block and pays gas to the miner but changes no other state. (This is called “Attributability of Missing State” by this post.
If I can lose money for submitting a witness which is too small then miners need to be able to prove that I submitted a witness which was too small. Ethereum usually handles this situation by asking me to sign my witness.
If it was costless to create a giant witness then it would be easy to DOS the network. So, transaction senders should be charged for the size of their witnesses. If this is the case, then once again transaction senders will want to sign witnesses, or else a malicious state provider / miner could DOS them by attaching a massive witness to their transaction.
If witnesses are signed, then state providers can’t unilaterally update witnesses, they need to ask the transaction submitter to resign the transaction with the updated witness.
Cumulatively, all of the above means that if miners reject transactions with stale witnesses, then transaction senders will be required to stay online and resubmit transactions which have been invalidated (which happens every block, since the state root is always changing).
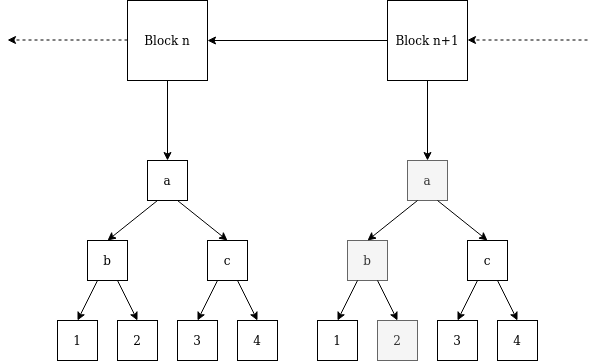
Here’s what I mean by a stale witness. Say you have two blocks, a transaction in block n changed account 2, modifying a few nodes in the state tree.
In order to prove the value of account 1, given the state root for block n, the witness includes nodes 1, 2, and c. However, as of block n+1 that witness is no longer valid. The miner can check that this is a valid proof for a previous block, but it has no way of proving that no transaction in block n changed the value of account 1.
I can think of a few ways around the above problem:
We simply accept that transactions are only valid until a block is mined, at which point they are invalid and must be resubmitted with the new state root.
Miners have some way of incorporating transactions with stale witnesses into the blocks they mine, even though miners hold onto no state.
Maybe I’m wrong that the only way to commit to a witness is to add it to the signed part of the transaction.
All of this assumes something like the “Direct Push” model from this post. A more complicated architecture could push responsibility for submitting correct witnesses to other network participants.
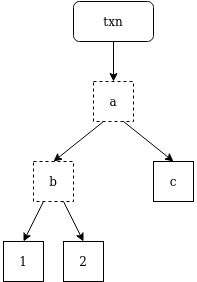
I think you can adapt the scheme I propose here (i.e. state lookup-less clients).
Specifically, modify the steps below to deal with general witnesses instead of UTXO-specific inclusion proofs:
TL;DR: Witnesses can be updated by applying only the last D blocks, which removes the need to interactively update them. Since D is bounded, we don’t have to worry about runaway DoS attacks.
Wouldn’t the block proposer (aka miner) be able to create a witness to account 1 in block n+m based on the witness for block n, along with the witnesses and transactions in blocks n to n+m-1? If the value of account 1 changed, someone had to have provided a witness. Same for any parent nodes in the Merkle proof.
I think this is what @adlerjohn said, using different words.
That said, insufficient witnesses still pose a problem. You need to be able to construct the exact bytes signed by the user if the block proposer is to claim the fees.
It might be possible to reconstruct this from a Merkle multiproof, but outdated witnesses would mean including multiproofs to the state roots of older blocks.
I also think this is what you said @adlerjohn, please correct us if we’re misunderstanding you!
I don’t think it works though. Or, even if it can be made to work, making it work is far too complicated to be feasible.
Say that a transaction includes a witness, W_{tx} rooted in block n, B_n. I agree that a BP can take the witnesses for all blocks between B_n and B_c (the current chain tip), and use it to create a new witness for the transaction.
This has a large problem, which you mentioned:
If miners want to be able to charge for a bad witness they need to be able to prove that the witness, W_{tx} was missing some data. This is… difficult! It looks something like:
Say that the transaction fails because it tries to access account A, which W_{tx} did not prove.
The BP includes both the transaction and W_{tx}.
The BP includes the chain of headers between B_n and B_c (so we can get at their witnesses)
The BP includes an updated witness, all accounts/storage-slots proven by the W_{tx} are proven under the new state root.
The BP proves that no block between B_n and B_c wrote to A. This sequence of proofs gets longer, the larger the distance between B_n and B_c (so in practice we would need to enforce a maximum distance)
(Things get a little easier if you disallow dynamic state accesses, but not much.)
I think this is all a long-winded way of saying what you say here:
It ends up being a lot of data! It’s hard to see how this wouldn’t blow up the size of blocks. It’s also very complicated.
Beyond that, there are also some smaller problems. I mentioned above that you probably need to enforce a maximum distance, past which older transactions can’t have their witnesses updated. Let’s call that distance M.
Transactions must be resubmitted every M blocks, so we would like for M to be relatively large.
Block producers joining this shard need to download M witnesses before they can produce a block (if they want to accept older transactions), so we would like for M to be quite small.
The updated witness is likely to be a different size than the witness, so there might be an attack where you can bloat blocks by looking at the transactions in flight and finding a way to increase the witness size needed to prove them.
While it is possible to take a sequence of witnesses and use them to update W_{tx}, doing so requires being able to know the values which were written by each block. There are two ways to do that:
Have the BP actually execute those M blocks, with all their transactions.
Have the witnesses also include all the values they write (most proposals don’t include this, because it can be derived, and it makes the witnesses larger)
Neither of these options are very appealing, hopefully (2) doesn’t make the witnesses too large.
It is simpler than this. The transaction contains a hash to a signed access list. Verifying the witness and attaching it is up to the block producer. As an entry point to the mempool, the signature and witnesses are verified. The developing phase 2 spec includes functions around this - EE phase2 draft by protolambda · Pull Request #1628 · ethereum/consensus-specs · GitHub
We do not need a user to sign the actual witness, just an access list. If the transaction attempts to touch an access location that is not included in the access list, then the block producer includes the user signed access list and may take a fee from the user along with it being an invalid tx. If the user submits a bad witness, the transaction is rejected from the mempool. If the witness touches state which was recently updated, the mempool/validator will update the submitted witness (there does not need to be user attribution towards the actual witness).
In the model described above, this is not necessary. Clients should just keep track of recently updated access locations/state.
No complicated proofs needed in this model. An SLOAD analogue would just need to be checked against a signed access list (but only in the case that the block producer needs to collect a fee due to state being accessed that was not included in the access list).
This is also unneeded. Clients can keep track of recently updated state for as long as they choose. A user may resubmit their transaction if the waiting period becomes longer than what most clients support. However, the mempool can be optimized around this fairly easily (in which case it is tx specific vs. location specific).
I don’t think this is an issue. In SSA, you would have defined/fixed state size.
Just to follow up on this and give an explicit summary, because I think the access list model has not yet been explicitly written down (we talked about it at SBC):
Under the access list model:
When creating a transaction, the user additionally signs a list of all locations potentially accessed by the transaction and sends this access list along with the transaction and the witness to the network.
Any node in the network drops incoming (pending) transactions from its mempool if its witness is:
too large, or
malformed, or
incomplete, i.e. does not cover all locations specified in the access list
Under SSA, if the witness is complete, it remains complete under updates and merges
Similarly, under SSA, the witness size will remain constant under updates
If a transaction in a block accesses state not provided by the (merged) witness:
If the BP was honest, they can prove that the location is not in the access list signed by the user \Rightarrow The BP was allowed to include the transaction. It fails, but the user still has to pay for its gas
Otherwise (if the BP failed to ensure that the witness was complete), they cannot prove that the location is not in the access list (because it in fact is) \Rightarrow The BP was not allowed to include the transaction. The block is invalid and will be rejected by the network
It is important to note that the feasibility of the access list approach is not yet certain, but so far it seems to solve all important issues around attributability of an insufficient witness.
Additional context into access lists can be found around EIP-648. It was never implemented in the context of stateful Ethereum because it does not provide any scalability benefits as the bottleneck is disk I/O, not CPU. However, if the goal is not parallel stateful execution but rather asserting to some stateless access list and nothing more, it seems perfectly reasonable.