Toward Semantic Block Chunking
As block gas limits increase, the size of Ethereum blocks will inevitably grow. We cannot rely on monolithic blocks that are compressed, propagated, and only then executed. At some point, we need to introduce block chunking to reduce latency, smooth propagation, and relieve validators in the critical path.
In an earlier post, I described semantic payload chunking and the motivation behind it. Now, I want to take that idea further: real progress comes from treating semantic chunks as first-class objects, and going a step beyond by separating chunk access lists (CALs) from the chunks themselves.
Taxonomy recap
There are several distinct ways to think about chunking blocks:
(1) At the basic level, one can simply take the RLP-serialized block as a byte stream and cut it into fixed-size slices. These fragments are easy to propagate and fit well with transport protocols, but they carry no meaning: a validator cannot do anything with them until the entire block is reassembled. This form of non-semantic chunking helps with bandwidth smoothing and data availability, but does not improve execution latency.
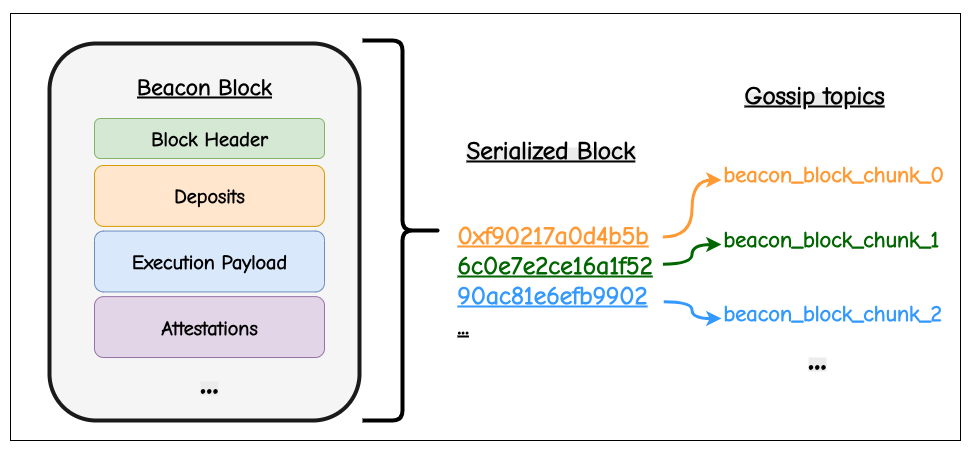
(2) A step up in structure is to split the block along its natural schema boundaries. Here, the header, the transaction list, withdrawals, receipts, and execution outputs would all be propagated as independent objects. The pieces correspond to protocol-defined fields and allow, for instance, partial fetching of headers before the full body, or prioritizing attestations. However, these components often only make sense together: execution still requires the full payload, so the benefits for validator latency remain limited.

(3) The more ambitious version is to redefine the block itself as a sequence of self-contained chunks. Each chunk carries its own header, transactions, and post-state root, and is independently verifiable as an object. The chain of chunks composes into the canonical block by linking the post-state of one to the pre-state of the next. This goes beyond decomposition and becomes compositional semantic chunking: chunks are not mere fragments but new semantic units of the protocol. Validators can begin execution as soon as the first chunk arrives, without waiting for the full block to arrive. This unlocks true streaming validation and opens the door to per-chunk proofs and parallel proving.

Notably, these approaches are not necessarily exclusive: one could do (3) and separate transactions, withdrawals, execution outputs, etc., from chunks, combining them with the semantic chunking approach of (2). Furthermore, chunks could be split up after serialization, before compression, as described in (1).
Chunks as new semantic units
Instead of treating a block as a single execution payload, we restructure it into multiple chunks. The block as we know it today is conceptually reframed and now consists only of a header and the chunks. The header commits to the execution of all chunks in a slot, including the post-state root of the final chunk.
Chunk Architecture
On the CL, each ExecutionChunk contains:
class ExecutionChunk(Container):
chunk_header: ExecutionChunkHeader # Header with execution commitments
transactions: List[Transaction, MAX_TRANSACTIONS_PER_PAYLOAD]
withdrawals: List[Withdrawal, MAX_WITHDRAWALS_PER_PAYLOAD]
The ExecutionChunkHeader contains the fields one would usually expect in the block header:
class ExecutionChunkHeader(Container):
index: int
txs_root: Root
post_state_root: Root # could be removed to reduce hashing overhead
receipts_root: Root
logs_bloom: Bloom
gas_used: uint64
withdrawals_root: Root
As described by proto in this doc on Flash BALs, the post-state roots can be removed from chunk headers to reduce hashing overhead. This is an interesting idea, and it keeps the design closer to how blocks look today (i.e., no intermediate state roots).
Technical Constraints
The protocol enforces strict boundaries to ensure predictable execution:
- Gas Limit: Each chunk must respect a hard limit of
CHUNK_GAS_LIMIT = 2^24(16,777,216) gas - Maximum Chunks: Up to
MAX_CHUNKS_PER_BLOCK = 16chunks per block - Minimum Fill Requirement: Non-terminal chunks must be at least 50% full (≥ 2**23 gas), to prevent inefficient fragmentation
- Withdrawal Placement: Withdrawals are included only in the final chunk to maintain consistency
- State Continuity: The post-state of chunk i becomes the pre-state of chunk i+1. Chunk boundaries serve as intermediate state roots, but these intermediate state roots could be removed if the additional hashing adds too much overhead.
- Block Atomicity: By arranging chunks in order and considering only the execution output of the final chunk, we approximate what is currently defined as a block.
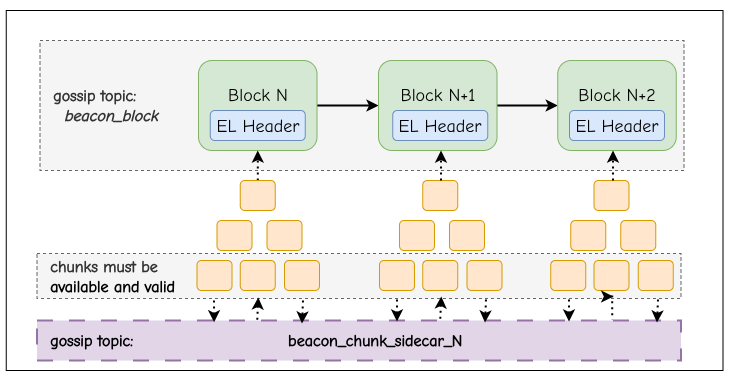
This transforms chunking from a propagation trick into a semantic redefinition of block structure. Validators can execute chunks independently as they arrive through a streaming validation process, but the block is only valid if every chunk in the sequence executes successfully.
The CAL Architecture: State Diffs as Separate Objects
Assuming we split the block into chunks, where should we put the block-level access list (BAL)?
Block-level access lists (EIP-7928) are a proposal for adding state locations (addresses, storage keys) + transaction-level state diffs to blocks, enabling parallel execution independent of transaction dependencies.
For payload chunking, the chunk access lists (CALs) propagate separately from chunks as sidecars, where CALs contain the state diffs of their corresponding chunks:

Execution Dependencies
Resolving dependencies among chunks:
- Each CAL contains the state diffs (account changes, storage modifications) from its corresponding chunk’s execution
- Each chunk N requires the union of CALs for all predecessors up to N–1 in order to be independently executed. This is because CALs contain the state changes needed to reconstruct the required pre-state:
apply_cals(parent_state, [cal_0, cal_1]) -> pre_state_for_chunk_2 - To execute chunk N, the validator must have:
chunk[N]itselfCAL[0], CAL[1], ..., CAL[N-1](containing cumulative state diffs)
This creates a cumulative dependency chain where the late arrival of an early CAL delays the execution of all subsequent chunks. However, since CALs are typically small, they propagate quickly across the network.
Design Consideration: Instead of CALs encoding state diffs relative to the pre-state (chunk 0) or to the previous chunk (chunks 1 to n), each CAL could carry a diff against the pre-state regardless of its index. This would let validators execute, for example, chunk #3 without waiting for CALs #0–2, requiring only CAL #2. The trade-off is that CAL #2 becomes larger, as it must include both its own state diff and the accumulated diffs from earlier chunks.
Network Architecture
The separation of CALs (containing state diffs) from chunks creates distinct propagation paths:
Gossip Topics:
- Chunks (transactions + withdrawals) travel on
execution_chunk_sidecar_{subnet_id}wheresubnet_id = chunk_index % 16 - CALs (state diffs + access info) travel on
chunk_access_list_sidecar_{subnet_id}wheresubnet_id = cal_index % 16

Fork Choice and Two-Phase Validation
The fork choice carefully distinguishes between chunk availability and block validity:
Modified Store
class Store:
# ... existing fields ...
chunks: Dict[Tuple[Root, ChunkIndex], ExecutionChunk]
chunk_access_lists: Dict[Tuple[Root, ChunkIndex], ChunkAccessList]
chunk_validation_status: Dict[Tuple[Root, ChunkIndex], bool] # Phase 1
payload_chunk_availability: Dict[Root, bool] # All chunks present
block_state_valid: Dict[Root, bool] # Phase 2 - final state matches header
The critical distinction: chunks can be validated independently, but the block is only valid after verifying the complete state transition.
Execution Engine Interface
The two-phase validation is reflected in the execution engine API:
# PHASE 1: Independent chunk validation
def notify_new_chunk(execution_engine, block_root, chunk, parent_root):
# Validate chunk internally - transactions, gas, local state transition
return execution_engine.validate_chunk(block_root, chunk, parent_root)
def notify_new_chunk_access_list(execution_engine, block_root, index, cal):
# Provide CAL with state diffs for independent execution
execution_engine.new_chunk_access_list(block_root, index, cal)
# PHASE 2: Complete state transition verification
def finalize_chunked_payload(execution_engine, block_root, expected_chunks, header):
# Verify: chunks[-1].post_state_root == header.state_root
# This is where block validity is determined
return execution_engine.verify_state_transition(block_root, expected_chunks, header)
The separation is necessary: validate_chunk() can return true for all chunks, but verify_state_transition() can still return false if the final state doesn’t match the header commitment.
Block Validity Check
The protocol enforces both phases before attestation:
def is_block_valid(store: Store, block_root: Root) -> bool:
block = store.blocks[block_root]
# PHASE 1: All chunks individually validated
for i in range(len(block.body.chunk_roots)):
if not store.chunk_validation_status[(block_root, i)]:
return False # Chunk failed validation
# Verify chunk matches committed root
if hash_tree_root(store.chunks[(block_root, i)]) != block.body.chunk_roots[i]:
return False
# PHASE 2: Complete state transition verified
if not store.block_state_valid[block_root]:
return False # Final state doesn't match header
# Verify final chunk's post-state matches header
final_chunk = store.chunks[(block_root, len(block.body.chunk_roots) - 1)]
if final_chunk.post_state_root != block.header.state_root:
return False # State transition invalid
return True
Validators MUST NOT attest until is_block_valid() returns true, ensuring:
- All chunks validated independently (Phase 1)
- Final state transition matches block header (Phase 2)
Execution Layer Architecture
The execution layer implements streaming validation to process chunks as they arrive:
Core Data Structures
On the EL, chunks are self-contained execution units:
class ExecutionChunk:
chunk_header: ExecutionChunkHeader # Position in block
transactions: Tuple[Transaction] # Complete txs (not split)
withdrawals: Tuple[Withdrawal] # Only in final chunk
Streaming Validation Components
The EL employs key components for streaming validation:
1. StreamingChunkReceiver: Manages per-block chunk reception and validation
- Tracks chunks arriving (out of order)
- Validates as soon as dependencies are satisfied
- Maintains validation context for each chunk
2. Chunk Processor: Orchestrates the validation pipeline
- Sequential: Uses the previous chunk’s post-state
- Independent: Applies cumulative CALs to the parent state
The critical insight is that CALs contain the state diffs from their chunks’ execution, enabling independent validation without sequential dependencies.
Execution Modes
Chunks can execute in two modes depending on available data:
def validate_chunk(chunk_index, chunk, dependencies):
if chunk_index == 0:
# First chunk uses parent state directly
pre_state = parent_state
elif previous_chunk_validated:
# Sequential execution with previous post-state
pre_state = chunks[chunk_index - 1].post_state
elif all_prior_CALs_available:
# Independent execution by applying CALs (which contain state diffs)
# CALs contain all state changes from their chunks
pre_state = apply_CALs(parent_state, CALs[0:chunk_index])
# Execute chunk transactions
post_state = execute(pre_state, chunk.transactions)
assert post_state.root == chunk.post_state_root
Two-Phase Validation: Independent Chunks, Valid State Transition
The architecture separates chunk validation from block validation:
Phase 1: Independent Chunk Validation (Streaming)
As each chunk arrives, validators immediately verify:
- Internal consistency: Transactions are valid, gas limits respected
- Local state transition: Using either previous chunk’s post-state OR applying CALs to parent state
- Chunk commitment:
post_state_rootmatches after executing chunk transactions - No block context needed: Each chunk validates in isolation
This happens before the block header arrives and without knowing the final state root. Chunks and CALs can be authenticated by verifying the proposer’s signature on the chunk header.
Phase 2: Block State Transition Verification
Once all chunks are validated:
- Verify continuity: Post-state of chunk N-1 must equal pre-state of chunk N
- Aggregate outputs: Total gas, receipts, logs from all chunks
- Validate against header: Final state root MUST match
block.header.state_root - Atomic decision: Block is valid if and only if all chunks validated AND final state matches
# Phase 1: Each chunk validates independently
for chunk in arriving_chunks:
validate_chunk(chunk) # Can fail fast without full block
# Phase 2: Verify complete state transition
if all_chunks_valid:
final_state = chunks[-1].post_state_root
assert final_state == block.header.state_root # Block validity
This separation enables chunks to fail fast during streaming, but preserves the critical property that block validity depends on the complete state transition matching the committed header.
Inclusion Proofs
Every chunk and CAL sidecar includes a Merkle inclusion proof:
class ExecutionChunkSidecar(Container):
chunk: ExecutionChunk
chunk_signature: SignedChunkHeader
chunk_root_inclusion_proof: Vector[Bytes32, CHUNK_INCLUSION_PROOF_DEPTH]
This ensures that even if chunks arrive out of order or from different sources, validators can verify they belong to the committed block before processing.
Builder vs Local Block Production
The protocol supports two distinct flows for chunk production:
Builder Flow
- Builder creates a chunked payload respecting all constraints
- Builder sends
SignedExecutionPayloadBidcontainingchunk_rootsandchunk_access_list_roots - Proposer includes these commitments in the beacon block
- Builder publishes actual chunks and CALs as sidecars. If the builder fails to publish, the block becomes invalid.
Local Flow
- Proposer requests a chunked payload from the local execution engine
- EL returns chunks as they are built, respecting gas limits and fill requirements
- Proposer starts publishing chunks as they are returned
- Proposer computes roots:
chunk_roots = [hash_tree_root(chunk) for chunk in chunks], same for chunk access lists - Proposer publishes a beacon block including the commitments.
Proposers building blocks locally will benefit more from streaming than proposers outsourcing block production to entities that try to submit as late as possible (i.e., proposer timing games).
Related approaches in other ecosystems
Other ecosystems have explored parallelism and “chunking” in different ways.
Fuel and Solana both rely on transactions declaring their full read/write sets upfront: Fuel enforces explicit access lists over UTXO-style resources to partition transactions into conflict-free sets that run in parallel, while Solana’s Sealevel runtime schedules non-overlapping account writes concurrently, with its Turbine protocol chunking block data into shreds purely for propagation.
Aptos and Starknet use Block-STM, which speculatively executes all transactions in parallel and rolls back conflicts until a deterministic sequential state is reached, whereas Sui applies a variant where non-conflicting object-centric transactions can bypass consensus entirely.
In contrast, NEAR and Polkadot pursue state sharding: NEAR splits accounts across shards and aggregates per-shard chunks into a single chain, while Polkadot runs heterogeneous parachains whose proofs of validity are checked and made available by the Relay Chain.
Base’s Flashblocks introduce temporal chunking rather than sharding or state partitioning: within each 2-second block window, the sequencer streams ten “flashblocks” (~200 ms apart) as preconfirmations with bounded gas budgets. These micro-blocks reduce latency and UX by exposing sub-block ordering, but all nodes still process a single global state, and flashblocks collapse into the final block without cross-shard complexity.
Also check out proto’s doc about Flash BALs, which describes the benefits of both Flashblocks and BALs.
Compared to these models, semantic payload chunking maintains Ethereum’s single global state machine but elevates chunks into first-class protocol objects with verifiable post-tx state diffs (CALs), enabling streaming validation and per-chunk proofs without speculative execution or cross-shard asynchrony. Furthermore, thanks to CALs, we won’t need to stop at optimistic parallelization: transactions can be perfectly parallelized independent of state dependencies.
Why semantic chunking matters
Non-semantic chunking helps transport but doesn’t change what a block is. By contrast, the described semantic chunk approach:
- Redefines block structure: Each chunk is a first-class protocol object with its own validation rules and execution outputs
- Enables streaming validation: Validators parallelize download and execution, with chunks processed immediately via
notify_new_chunk() - Improves modularity: CALs encapsulate state diffs separately from transaction data, enabling independent execution
- Supports future proving: ZK or optimistic proofs can be generated per chunk with bounded proving time (max 16.7M gas)
- Preserves atomicity: The block remains atomic - all chunks must validate for block validity
On the EL, we can expect concrete performance improvements:
- Bounded Memory and Compute: Each chunk consumes at most
CHUNK_GAS_LIMITworth of resources - Early Rejection: Invalid chunks fail fast without requiring all chunks to be processed
- Parallel Validation: Multiple chunks can validate concurrently using CALs (which contain state diffs)
The combination of semantic chunking at the consensus layer with streaming validation at the execution layer transforms block processing from a monolithic operation into a composable, streamable pipeline that scales with network capacity rather than being bottlenecked by the largest atomic unit.

