Towards safe optimization of the storage-related gas cost
TL;DR
This post follows the idea of EIP-2929 to optimize gas cost by ensuring de-facto storage loads inherent in those opcodes are priced correctly. Evaluations demonstrate our optimizations can reduce about 30% gas cost (i.e., transaction fee).
This post is a summary of our research paper “Z. He, Z. Li et al., Maat: Analyzing and Optimizing Overcharge on Blockchain Storage. (Usenix FAST25)”, you can read the full paper here.
Introduction
Our research identifies three inconsistency issues, in which gas cost of storage is higher than de-facto storage loads (e.g., a memory load is charged as the gas cost of a disk load). These three inconsistency issues occur in Ethereum’s storage operations, including 1) continuous access accounts/slots within a block, 2) cross-block access within 128 blocks, and 3) deployment of duplicate smart contracts.
Furthermore, we propose four related optimization rules to address these issues by ensuring de-facto storage loads inherent in those opcodes are priced correctly.
Meanwhile, we also prove our optimizations are compatible with Ethereum’s consensus and maintain storage operation consistency across heterogeneous Ethereum nodes.
Finally, we evaluate our optimizations using Ethereum data from block #18M (Aug-26-2023) to #19M (Jan-13-2024) and corresponding data on BSC. Extensive evaluations of Maat on Ethereum reveal a 32% reduction in transaction fees, amounting to 5.6M USD in weekly savings and nearly outperforming the EIP-2929 by nearly three times.
EIP-2929
Before introducing our optimizations, it is essential to understand EIP-2929, which plays a crucial role in the context of our research. EIP-2929 aims to ensure that the gas costs associated with storage operations within a single transaction are accurately priced. One of its key design goals is to reduce memory access costs within the same transaction, thereby lowering overall gas fees.
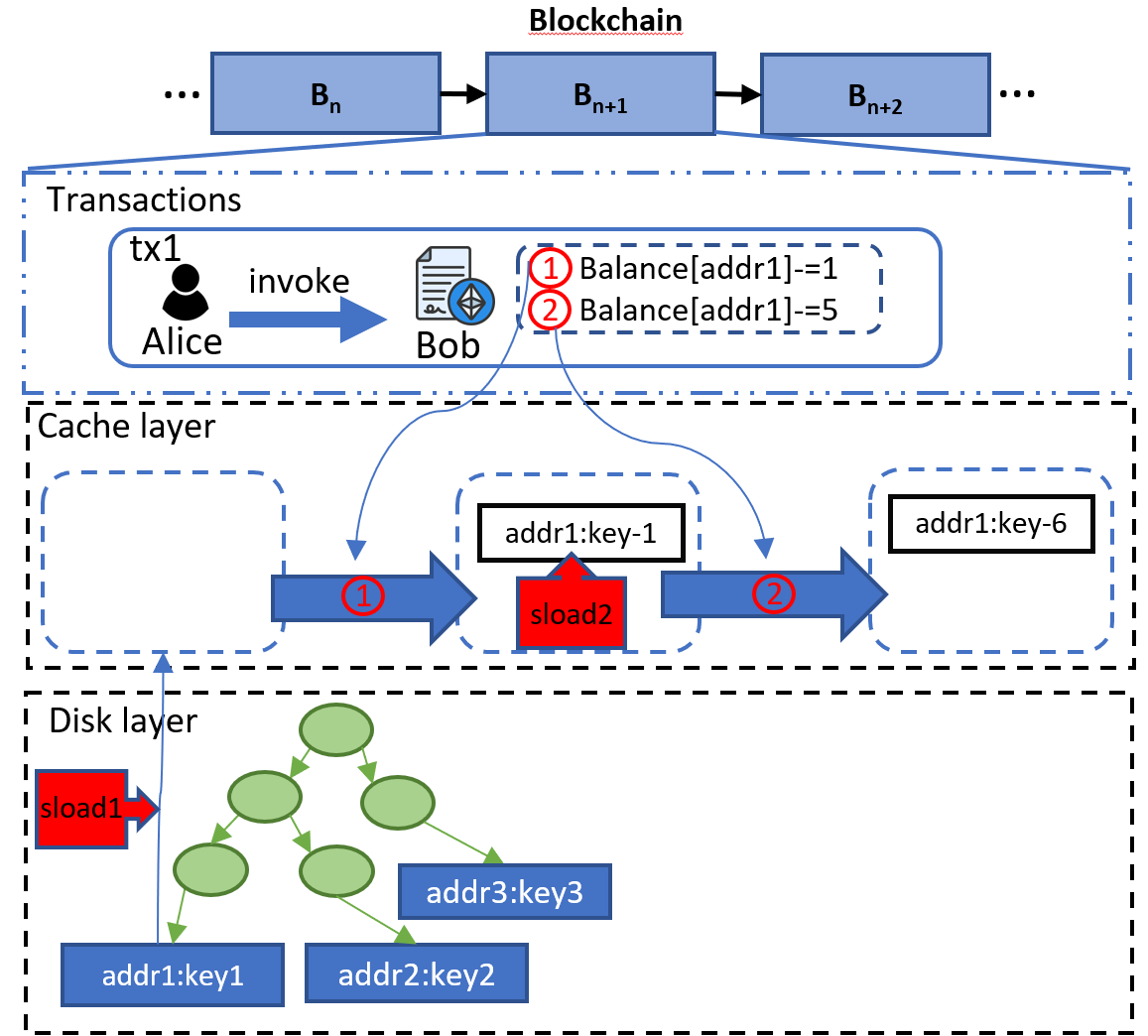
Figure 1: EIP-2929 reduces gas costs for subsequent storage operations within the same transaction.
Take Figure1 as the example, consider a scenario where a transaction accesses the same storage slot (i.e., addr1 in our figure) twice using the SLOAD opcode (e.g., for an airdrop). Prior to EIP-2929, both SLOAD operations would incur the same gas cost. However, with the implementation of EIP-2929, the second SLOAD operation incurs a reduced gas cost (e.g., 100 gas) because it accesses data from memory rather than from disk (see the red label of sload2).
The rationale behind this reduction is straightforward:
- The first SLOAD operation involves accessing the storage slot from disk and loading it into memory (see the red label of sload1).
- Subsequent SLOAD operations on the same slot can then retrieve the data directly from memory, avoiding redundant disk accesses and thus reducing the gas cost (see the red label of sload2).
This adjustment ensures that gas pricing more accurately reflects the actual computational resources used, leading to fairer and more efficient transaction processing.
Identified inconsistency Issues
Issue1: Continuous Access account/slot within a block
Issue1 occurs when an account or storage slot is accessed multiple times within the same block. Subsequent accesses should be charged at the lower gas cost of memory accesses. Concretely, Ethereum adopts a cache strategy for state modifications during one block execution, ensuring that updates are stored in cache until block finalization. When an account or storage slot is accessed multiple times within the same block, subsequent accesses within the cache retention window still be charged as disk reads rather than memory reads.
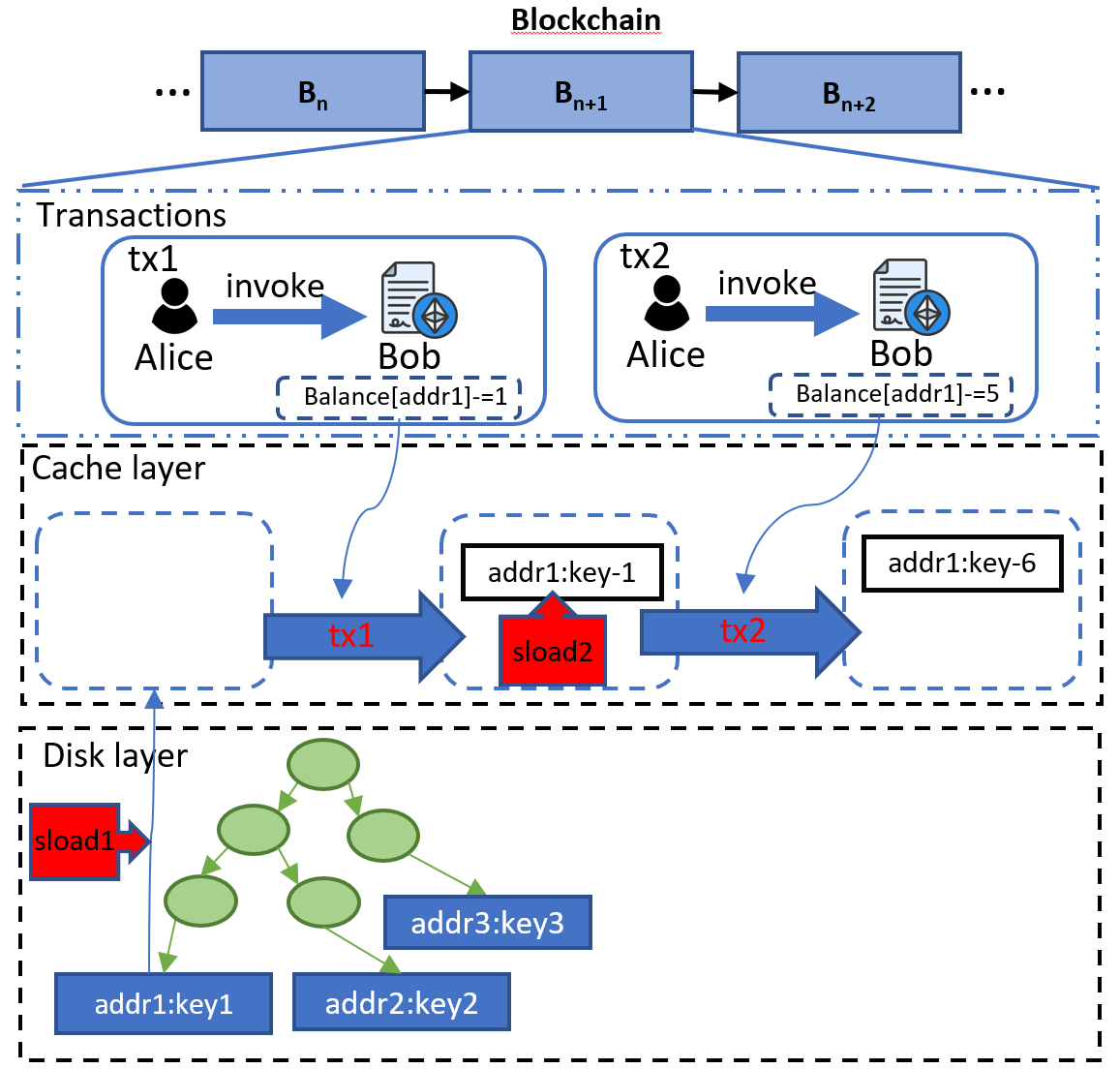
Figure 2: The gas costs inconsistency in issue1 for subsequent operations within the multiple transactions in a block.
Take Figure2 as the example, consider a scenario where two transactions (tx1 and tx2) access the same storage slot (i.e., addr1) within the same block. The first SLOAD operation in Tx1 incurs a disk read cost (e.g., 2,100 gas), as the data is fetched from disk and loaded into memory (see the red label of sload1). However, the subsequent SLOAD operation in tx2 should ideally incur a memory read cost (e.g., 100 gas) since the data is already in memory (see the red lable of sload2). Despite this, Ethereum still charges the full disk read cost for the second SLOAD operation in tx2, leading to inefficiencies.
Actually, the same issue also occurs in the same transaction, which is similar to the example of EIP-2929. However, the difference is that the issue1 occurs in the same block, while EIP-2929 occurs in the same transaction. Meanwhile, we extend issue1 to both account and storage slot, while EIP-2929 only focuses on the storage slot.
Issue 2: Continuous read account/slot within cross 128 blocks
Issue2 arises when an account or storage slot is accessed multiple times across 128 blocks. Specifically, Ethereum EL clients utilize a state snapshot acceleration structure to cache accessed state objects for up to 128 blocks (e.g., seeing SSAS of geth, bonsai tree of besu).
When an account or storage slot is red multiple times within 128 blocks, subsequent accesses within the cache retention window still be charged as disk reads rather than memory reads.
To save space, we omit the example of issue2 here. The example is similar to the example of issue1, but the difference is that the issue2 occurs across 128 blocks, while the issue1 occurs in the same block. Besides, the issue2 only focuses on read operations, while issue1 focuses on both read and write operations. Because the cross-block write operations only occur in Merkle Patricia Trie (MPT), the cross-block read operations occur in the above cross cache.
Issue 3: Deployment of Duplicate Smart Contracts
Issue3 arises when a contract with an identical bytecode is deployed multiple times. Ethereum charges a storage fee of 200 gas per byte for writing bytecode to storage. However, if a contract with identical bytecode has already been deployed, the new deployment should reference the existing contract code instead of incurring redundant write fees. Despite this, Ethereum still applies the full storage cost, leading to inefficiencies.
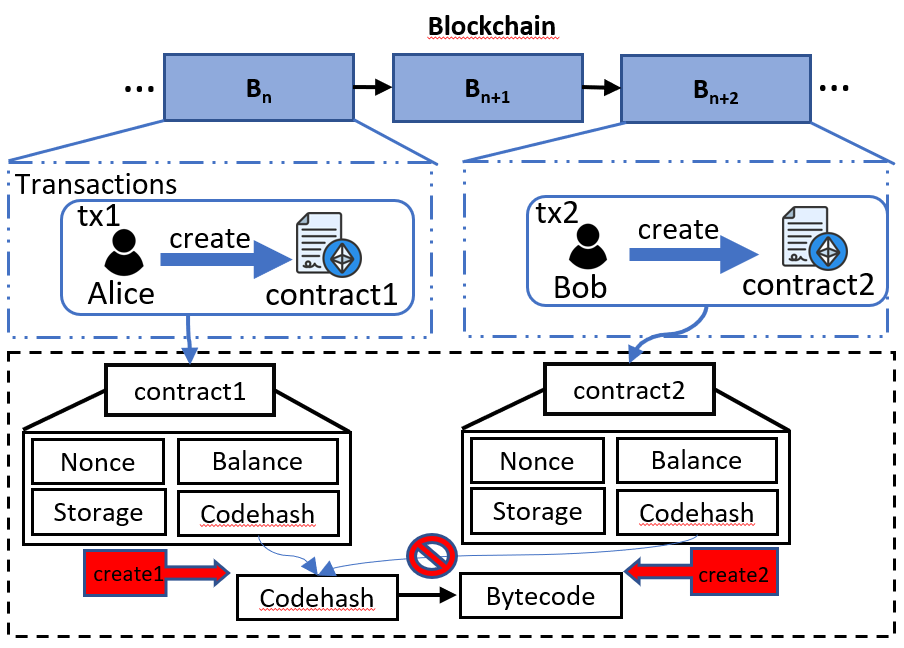
Figure 3: The gas costs inconsistency in issue3 for the deployment of duplicate smart contracts.
Take the exmple of Figure3, consider a scenario where two contracts (contract1 and contract2) with identical bytecode are deployed. The deployment of contract1 incurs a storage cost of 200 gas per byte for writing the bytecode to storage. However, the deployment of contract2 should ideally reference the existing contract code of contract1 instead of incurring redundant write fees. Despite this, Ethereum still charges the full storage cost for the deployment of contract2, leading to inefficiencies.
Actually, the current Ethereum EL client always writing the duplicated contract code into state (see the code of geth). But when SSTORE write data, they will first check whether the data is already in disk, if it is, they will not write the data again (see the code of geth).
Optimization
Optimization Rules
- O1 & O2: For multiple read/write to the same object within a block, adjust subsequent charges to the memory access fee.
We submitted our paper to the community in Nov 2024, and someone proposed EIP-7863 regarding o1/o2. - O3: For objects read across blocks within the SSAS retention window, charge memory access fees instead of disk access fees.
- O4: For duplicate contract deployments, eliminate redundant bytecode storage costs by referencing existing contract code. Although users shouldn’t pay for the storage cost of the duplicated contract code, they still need to pay a fee to check the existence of the contract code (more like the fee of SSTORE when writing identical data, the price can be set as the cost of opcode ExtCodeCopy).
Considerations
- Price rationality: The price of memory access and disk access will follow the EIP-2929 to prevent intruding on the DoS attack. Concretely, 100 gas for memory access, 2,100 gas for slot disk read, 2,600 gas for slot disk write, and 2,600 gas for account disk read.
- Space rationality: O1, O2, and O3 will introduce additional memory. However, such memory can be accepted because the memory space is constrained by the block gas limitation. Note that there should be considered metadata to index such data.

Figure 4: The maximum memory usage of O1/O2/O3 in a block.
Concretely, we assume all the gas in a block is used to read accounts to estimate the maximum memory usage in Figure 4. The memory usage of O1/O2/O3 is 230MiB. I recommend you to read the paper for more details (e.g., why the account object is 164bytes).
- The introduction of a fee for querying contract bytecodes in the world state aims to balance costs between deploying duplicate and non-duplicate contracts. Most deployed contracts are duplicates, allowing over 88% (test in 1M blocks) of users to benefit from cost savings via O4 optimization. The deployment fee for a contract is significantly higher than the querying fee, making the additional charge minimal even for non-duplicate contracts. Consequently, the new charge is justified as it imposes a negligible financial burden on a small percentage of users while offering substantial benefits to the majority.
Ugly
1 Account write price: None of the specifications clearly defines the price of writing a single account object. The yellow paper defines the g_callvalue as 9000 gas to transfer Ether, and vitalik’s blog mentions this price is used to write two account objects. However, the price of writing a single account object is still unclear. Updating two account can be seen as two reads and two writes for two accounts, while account read can refer the price of BALANCE opcode (e.g., 2600 gas) and write account only needs 1900 gas (9000 /2 - 2600). How could it be possible?
Anyway, when we need to optimize the gas cost of accounts update, we will optimize the g_callvalue of 9000 gas to 400 gas for 4 times memory writes on two accounts or to 4700 gas (4500 gas + 200 gas) for 2 times memory writes on one account.
2 Cross-block cache inconsistency: O2 and O3 need a cross-block cache to store the accessed objects. Although the current Ethereum EL clients have supported the cross-block cache, they don’t consider the robustness of the cache. We need to ensure all the newly added nodes can get the state of the current 128 blocks cache from the existing nodes. When a node uses fast synchronization, it can only obtain the latest state and cannot obtain the state update cache of the nearby 128 blocks.
3 Cross-block cache inefficiency: In Cross-block, the worst cache query times would be 128 times. The current cross-block cache implementation stores the updated state of the 128 blocks as 128 maps. When a node queries the state of a block, it needs to query 128 maps to get the state of the block. If we update the 128 blocks in a single map, the query times can be reduced to 1 but we need additional operations/time/resource to update the map.
Experimental Evaluation
To evaluate the efficacy of Maat, we launch experiments on Ethereum from block #18M (Aug-26-2023) to #19M (Jan-13-2024) within 1M blocks. We adopt EIP-2929 as the baseline for comparison.
| Metrics | Optimized gas (gas) | Optimized ether (ETH) | Optimized fee (USD) |
|---|---|---|---|
| 1M blocks (Our Opitmization) | 2.01×10^12 | 58,358.52 | 1.12×10^8 |
| 1M blocks (EIP-2929) | 0.67×10^12 | 21,221.28 | 0.39×10^8 |
| Optimized rate (Our Opitmization) | 33% | 32% | 32% |
| Optimized rate (Baseline) | 11% | 12% | 11% |
Table 1: Optimization effect on Ethereum overcharging issues.
We display the evaluation results in Table 1. The experimental results show that Our Optimization processes 1 million blocks using 2.01×10^12 gas, converting to 58,358.52 ETH, with an optimized fee of 1.12×10^8 USD. In comparison, the EIP-2929 standard uses less at 0.67×10^12 gas, 21,221.28 ETH, and 0.39×10^8 USD respectively. Our method achieves a 33% optimization rate in gas, 32% in ETH, and 32% in fees, whereas EIP-2929 offers a lower optimization rate of 11% in gas and fees, and 12% in ETH. This indicates that while our optimization leads to higher absolute values, it provides a significantly greater improvement efficiency-wise over EIP-2929.
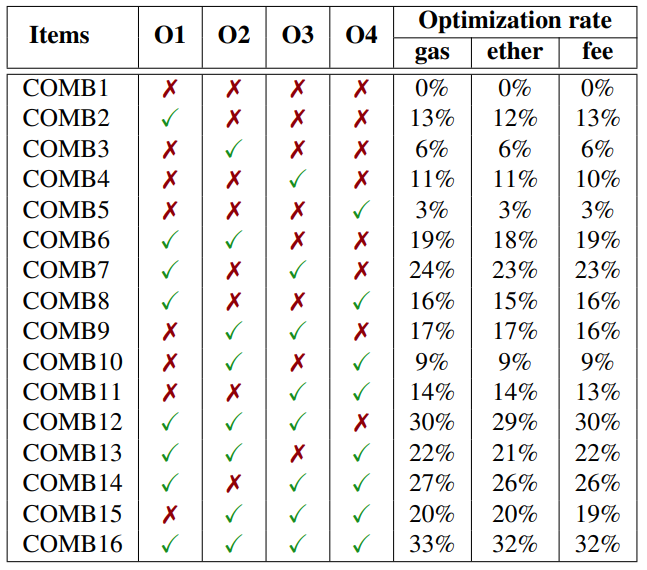
Table 2: The combination of four optimizations.
We also evaluate the effect of the four optimizations in Table 2. The experiment showed that COMB16, which includes all four optimizations, achieved significant improvements: 33% less gas used, 32% savings in ether, and a 32% reduction in fees. Meanwhile, COMB8, using O1, O2, and O4 but not O3, resulted in slightly lower benefits with 30% less gas, 29% savings in ether, and a 28% decrease in fees. Both combinations demonstrate effective cost reductions, with COMB16 offering the best overall performance.
Conclusion and Future Work
Our research highlights significant inefficiencies in Ethereum’s gas fee mechanism, leading to substantial overcharges. Maat effectively addresses these issues, resulting in large-scale cost savings.