Our contribution (2/2)
Having recalled the basics of sumcheck and GKR, we are ready to present our idea. We stress that this is a proposal. We are very interested in receiving feedback, in particular attempts at breaking this scheme.
Compiling GKR verifier in a R1CS
Hyrax proposes to compile this protocol using discrete-logs assumptions in order to obtain a zero-knowledge succinct non-interactive argument of knowledge. Its purpose is to establish a proof system without trusted setup. Libra propose to use a multilinear commitment, this encapsulate the evaluations of V_d and V_0 at the expense of an increased prover time.
The verifier typically runs in ~1sec. However, it is be feasible to check the verifier transcript of the GKR NIZK with a pairing-based argument (like Plonk or Groth16).
The evaluations of V_0 and V_{d} requires few multiplication gate: 1 for each input and 1 for each output. On top of that it allows us to check relations between the inputs and the output cheaply. And the verifier time is constant.
The sumchecks are however expensive to verify in practice as we need to use randomness from the verifier. The classical way to do it non-interactively is to use the Fiat-Shamir heuristic and therefore a hash function. Even though, this is a logarithmic overhead, it has a large constant (in our circuit, we need to hash ~20k field elements).
Tuning GKR to make it a gMIMC hash proving accelerator
In the constraints model of GKR we may only have addition gates and multiplication gates and we cannot use “constants”. However, nothing prevents us from using different sets of gates. One may even use gates with different fan-in if needed. We take advantage of this observation to design a proof system specially tailored for data-parallel gMIMC hash computation. Each copy of the base circuit takes 2 inputs and returns one output.
Using custom gates
Following a suggestion in Libra, we define a custom family of gates. Let \alpha be the exponent for gMiMC in \Bbb{F} (a small positive integer, 3 - 7 in practice) and let k(1),\dots,k(101) be elements in \mathbb{F} (there are 101 rounds in gMiMC). Ciph_{k(i), \alpha}(x,y) = x + (y + k(i))^\alpha and the copy gate Copy(x, y) = x
The polynomial P_{q', q, i} must be set to P_{q', q, i}(h', h_L, h_R)= eq(q', h')\cdot\left[\begin{array}{r}ciph_i(q, h_L, h_R)\cdot Ciph_{k(i), \alpha}\Big(V_{i-1}(h', h_L),~V_{i-1}(h', h_R)\Big) \\+ copy_i(q, h_L, h_R)\cdot Copy\Big(V_{i-1}(h', h_L),~ V_{i-1}(h', h_R)\Big)\end{array}\right] The ciph_i(\bullet, \bullet_L,\bullet_R) and copy_i(\bullet, \bullet_L,\bullet_R) functions are the analog of the add_i(\bullet, \bullet_L,\bullet_R) and mul_i(\bullet, \bullet_L,\bullet_R) in that they encode the geometry of the gMiMC base-circuit. We use multilinear interpolation to extend their domain. For cost analysis (see below) we record the degrees of these polynomials w.r.t. the variables:
- it has degree \alpha+1 in h',
- it has degree 2 in h_L
- it has degree \alpha + 1 in h_R.
(Note: the various “+1” and “+2” come from degree 1 occurrences of variables in eq, ciph_i and copy_i.)
The verifier has to evaluate a degree \alpha polynomial in the consistency checks of the sumcheck. Since alpha is small, this is a negligible overhead compared to the cost of hashing. We can also still use Libra’s bookkeeping algorihm to keep the prover runtime small.
As a result, we obtain a GKR circuit able to verify the computation of N = 2^{b_N} hashes. Its base circuit consists of 2 gates per each layer (one copy gate, one ciph gate) and has a depth of 101.
Summing up, the consistency check costs 101[(b_N + 1)(\alpha + 2) + 3] constraints. The cost of Fiat-Shamir hashing is, for each GKR layer, (\alpha + 2) hashes of field elements: b_N times for the sumchecks rounds on h', \alpha + 2 field elements once for those on h_R and 3 fields elements once for those on h_L. Let T(n) denote the cost of hashing a string of n fields elements. The total cost of the Fiat-Shamir hash can be rewritten as 101[(b_N + 1)T(\alpha + 2) + T(3)]. These hashes could conceivably be computed directly in the smart contract using a cheap hash function (b_N=20, \alpha=7 equate to 20k hashes and a multiexp of that size or inside the SNARK) or inside the SNARK circuit (with approximatively T(n) = 350n, we estimate it is going to cost an additional 7M constraints.
The evaluation of V_0 and V_{d} is efficient in term of constraints. We need to interpolate 2 multilinear polynomials at given points from their evaluation representation. It takes 1 constraint per input and 1 constraint per output for a total of 3N constraints (plus the logarithmic overhead) per hash to prove. We can similarly obtain circuits for proving hashes with a different number of inputs using analogous methods.
Splitting the depth of the circuit
Although the circuit is asymptotically efficient, the sumcheck induces a lot of overhead, mostly because of the Fiat-Shamir hashes. It is possible to trade asymptotic efficiency for lower overhead by using two sub-circuits of depth 51 to compute a hash. This implies that each sub-circuit is doing two halves of the rounds needed to compute a hash in parallel. Hence a two-fold decrease of depth but a two-fold increase in size of the public input/output. This can be generalized for any n-split of the circuit.
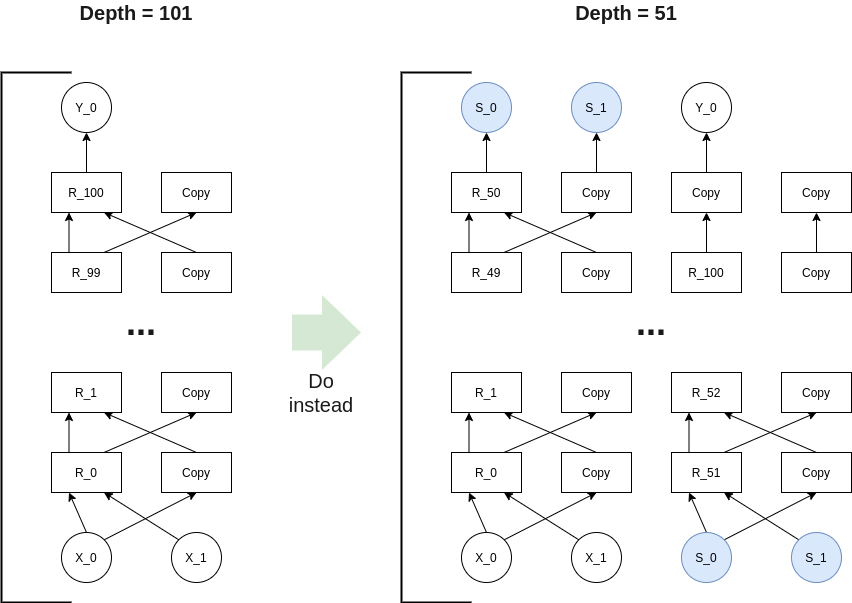
Composing several GKR circuits
As already mentioned, the majority of the verifier overhead lies in the usage of Fiat-Shamir to generate the sumcheck’s challenges. Depending on the input size, it yields in practice the need to hash 10000-30000 field elements. We propose to delegate the hashes to another GKR circuit with an important split factor.
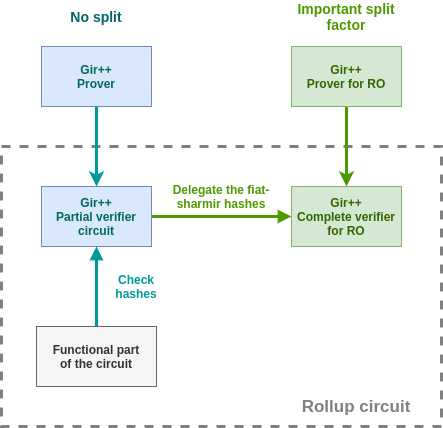
As a result, the rollup circuits has less hashes to perform which contribute to the reduce the overhead.
Generating the initial randomness
There remains an unsolved problem: generating the very first random input r_1 for the very first round of the very first sumcheck run dedicated to checking consistency between layers 0 and 1. In an interactive setting, this would pose no problem: the verifier would simply randomly sample r_1=(q_1',q_1)\in\Bbb{F}^{b_N}\times\Bbb{F}^{b_G}, send it to the prover who would then start work on generating a sumcheck proof for the equality
V_d(r_1) = \sum_{h\in\{0,1\}^{b_N}}\sum_{h_L,h_R\in\{0,1\}^{b_G}} P_{q',q,d}(h, h_L,h_R), and continue down the sumcheck protocol. When we turn things non-interactive, though, we need to efficiently generate the initial randomness, verifiably and with little overhead. Of course, hashing all of x and y (say) is out of the question: this is precisely the work that the verifier tries to avoid having to do. We see three viable possibilities for that.
- Generate randomness from a separate deterministic sumcheck / GKR run
- Pedersen Hash solution
Generate randomness from a separate deterministic sumcheck
Both a (noninteractive) sumcheck run and a (noninteractive) GKR run involve moderate hash computations. To be precise: under Fiat-Shamir, every variable elimination, i.e. every round in the sumcheck protocol, as well as the final round, require a hash computation.
The idea is thus to do a separate run (of either a new sumcheck problem or the actual GKR) using an initial random seed (likely low entropy and possibly biasable). That separate run is used to bind us to x and y through intermediate Fiat-Shamir hash computations. Note taht this involves only very few intermediate hashes. Using the hashes thus produces, one constructs a good initial random seed for the actual circuit verification.
In other words, one uses a dummy sumcheck / GKR run to produce a quickly (polynomial time) verifiable hash for an (exponentially) large input (x and y). Since the SNARK circuit re-uses x and y in the actual GKR proof, we expect this to be binding to x and y.
We see three simple ways to generate an agreed upon initial seed:
- a hardcoded value such as r_1^\mathsf{sep}=-1, or a “more complicated” hardcoded value r_1^\mathsf{sep}\in\Bbb{F} (e.g. a generator of \Bbb{F}^\times).
- a value r_1^\mathsf{sep} deterministically generated from a random beacon value RB that changes periodically and is known to all participants
We next describe two options for the separate sumcheck / GKR runs used to generate the initial randomness.
A simple sumcheck
Let r_1^\mathsf{sep} be some agreed initial randomness seed. One can consider the following sumcheck problem a=\sum_{i=1}^{G\times N}x_i+\sum_{i=1}^{G\times N}y_i=\sum_{i=1}^{2\times G\times N}u_i where we set u=x\|y, the concatenation of the vectors x and y, and view it (equivalently) as a function \widehat{u}:\{0,1\}^{b_G + b_N + 1}\to\Bbb{F} where \widehat{u}\big(\epsilon_0,\dots,\epsilon_{b_G+b_N}\big)=u_i if \epsilon_{b_G+b_N}\cdots\epsilon_1\epsilon_0 is the binary representation of i-1\in[\![~0\dots 2^{b_G+b_N+1}~[\![ for instance.) Alternatively, one may also consider u'=x\|0_{G\times N}\|y\|0_{G\times N} or some other padded variant on u (again, viewing it as a function \widehat{u'}:\{0,1\}^{b_G + b_N + 1 + 1}\to\Bbb{F}. Padding with 0’s (and thus doubling the size of the domain of the function) doesn’t affect the sum but produces an extra round in the sumcheck protocol and completely changes the intermediate steps of the computation.
Using the (low entropy) initial seed r_1 as the initial randomness for Fiat-Shamir, one runs an instance of sumcheck computing intermediate hashes as one goes along. The intermediate hashes thus generated (O(b_G+b_N) many) serve as binding commitments to x and y. From them, one is free to deterministically generate the proper randomness r_1 to be used to bootstrap the actual Fiat-Shamir noninteractive execution of GKR.
Note that x and y will (likely) be private inputs in the Snark circuit. (Although they may be public for some use cases, or parts of them may be public, for instance if the overall computation represents Merkle branch verifications from leaves to a public root hash.) Thus the Snark circuit will re-use these same x and y in the proper GKR verification.
Duplicating the GKR run
The idea is the same as above, but rather than using a completely different instance of the sumcheck protocol to generate the randomness bootstraping the “real” noninteractive GKR verification, one runs a dummy verification of the same GKR circuit (with initial randomness r_1^\mathsf{sep}).
Again, the SNARK circuit will ensure that x and y are re-used in both executions. This demands more work from the prover in that it doubles the effort on the prover’s end (and only slightly more work from the verifier). But it produces further consistency. Indeed, the first polynomial produced in the GKR prover run, P_1(X_1)=\sum_{b_2,\dots,b_n\in\{0,1\}} P(X_1,b_2,\dots,b_n), is the same no matter what. Its coefficients (of which there are very few, say, 3\mu) may thus be provided as further public data in the SNARK circuit used to verify the GKR proof.
N.B. We believe the first solution (separate sumcheck run) to be just as safe and less work for the prover, and thus superior.
Pedersen Hash solution
All of the checks we describe live in a constraint system. This approach proposes to leverage the final verifier in order to succinctly prove the hashing of x and y. We do it with the following protocol transforms:
- Make x and y public inputs of the SNARK proof (if they were not already, it depends on the use-case). We set u = x \| y, the concatenation of the vectors x and y, and set u_i to be its i-th coordinate.
A priori this would require the prover to send x and y to the verifier, who would have to include them in its SNARK multi-exponentiation. For large computations (i.e. large vectors x and y) this imposes a large multi-exponentiation onto the verifier, which is undesirable. Furtermore, the verifier may not care about either x and y, say if they represent intermediate steps in a Merkle proof where only the root hash is public knowledge (and thus, ideally, only the last coordinate of y, say, ought to be public data). This problem is bypassed as follows.
- The prover computes G = \sum_{i \in [|u|]} u_i\cdot G_i, where the G_i are the SNARK verification key parts corresponding to the public inputs u_i, and sends it to the verifier.
The verifier thus won’t need to compute the associated part of the public input multi-exponentiation. It can directly plug G into the multi-exp. The purpose fo G is to be binding to x and y and to serve as the randomness seed for the very first Fiat-Shamir randomness.
- Both the verifier and prover compute r = H(G).
We upgrade r to a public input of the SNARK proof. There is thus an associate curve point G_r in the verification key to be used by the verifier in its multi-exponentiation. The purpose of r is to serve as the initial Fiat-Shamir randomness.
- The verifier computes its public input multi-exponentation as r\cdot G_r + G + \Delta where \Delta is the remaining part of the multi-exp, corresponding to the “actual SNARK verification”.
This is equivalent of the using the hash of a pedersen hash of x and y by reusing the trusted setup. It is worth noting that in the end, the verifier does not have to perform computation linear in |u| as the prover does it for him.