Finalized Chain History Portal subnetwork
The Finalized Chain History is the subnetwork build on top of Portal wire protocol. Its goal is to provide decentralized storage of the finalized historical Ethereum data.
It assumes that nodes on the network are Execution Layer clients that store all historical headers locally. Nodes that are not Execution Layer clients will need a way to obtain block header for a given block number (in order to verify the content).
In the appendix section, I provide comparison to the existing Portal History subnetwork and rationale for the proposed changes.
Specification
Distance Function
The Finalized Chain History subnetwork uses the stock XOR distance metric defined in the Portal wire protocol specification.
Content id Derivation Function
The content keys (described later) use block number. The content id is calculated in the following way:
CYCLE_BITS = 16
OFFSET_BITS = 256 - CYCLE_BITS # 240
def content_id(block_number):
offset_bits, cycle_bits = divmod(block_number, 2**CYCLE_BITS)
# reverse the offset bits
offset_bits = int('{:0{width}b}'.format(offset_bits, width=OFFSET_BITS)[::-1], 2)
return cycle_bits << OFFSET_BITS | offset_bits
Detailed explanation and visualization of the content_id function is provided in the section below.
Wire protocol
The Finalized Chain History subnetwork uses the Portal wire protocol specification.
The discv5 sub-protocol identifiers (the protocol field of the TALKREQ message) are based on the Ethereum network that the content originated from:
0x5000- Mainnet0x5050- Sepolia0x5060- Hoodi0x5040- Testnet (used for testing purposes or isolated devnets)
The subnetwork protocol should be configurable via config file and/or cli flag (details TBD).
Message types
The Finalized Chain History subnetwork supports standard protocol messages:
| Request | Response |
|---|---|
| Ping (0x00) | Pong (0x01) |
| FindNodes (0x02) | Nodes (0x03) |
| FindContent (0x04) | Content (0x05) |
| Offer (0x06) | Accept (0x07) |
Ping.payload & Pong.payload
The payload type of the first Ping/Pong message between nodes MUST be Type 0: Client Info, Radius, and Capabilities Payload. Subsequent Ping/Pong message SHOULD use the latest payload type supported by both nodes.
List of currently supported payloads:
Content types
The Finalized Chain History subnetwork contains block body and receipts content types. Unlike other Portal subnetworks, these types use rlp encoding of the underlying objects.
Block Body
The Block body content type contains block’s transactions, ommers and withdrawals.
selector = 0x09
block_body_key = Container(block_number: uint64)
content_key = selector + SSZ.serialize(block_body_key)
content_value = rlp.encode(block-body)
Note: The block-body refers to the type defined in the devp2p spec, which is the collection of transactions, ommers and withdrawals.
Receipts
The receipts content type contains block’s receipts.
selector = 0x0A
receipt_key = Container(block_number: uint64)
receipts = [receipt₁, receipt₂, ...]
content_key = selector + SSZ.serialize(receipt_key)
content_value = rlp.encode(receipts)
Note: The receiptₙ refers to the type defined in the devp2p spec.
Future improvements
The current spec is designed with no changes to the original Portal wire protocol. The changes below are identified as desired and could be implemented using protocol versioning at any point in the future.
Some improvements might be prioritized and implemented before subnetwork goes “live”.
Better network support
Currently, the network is identified using specific discv5 sub-protocol (see Wire protocol above). This could be improved by specifying the chain_id or fork_id inside ENR record instead.
Range queries
The newly defined content id derivation allows us to easily add support for range queries. Content is already spread around the network in a desired way, so we wouldn’t need to re-seed it.
Adding support would be as simple as adding new message types, e.g.:
Range Find Content (0x08)
Request message to get the multiple content anchored with a given content_key.
selector = 0x08
range_find_content = Container(content_key: ByteList[2048], count: uint16)
Each content type should specify:
- whether range query is supported or not
- the maximum value of
countthat is supported - how
content_keyrepresents the desired range- e.g. whether
content_keyrepresents the start or the end of the desired range
- e.g. whether
- whether partial response is considered valid
- maybe this should be a message field
RangeContent (0x09)
Response message to Range Find Content (0x08).
selector = 0x09
range_content = Union[
connection_id: Bytes2,
content: List[ByteList[2048], 65535],
enrs: List[ByteList[2048], 32],
]
This message type is almost identical to the Content message. The only difference is that the content is a list of content values.
Appendix: Rationale and explanations
Comparison with legacy History Portal Network
If we assume that most of the nodes on the network are execution layer clients, we have to take into consideration some of their properties:
- The EL clients store all historical block headers
- The EL clients are long running
- Most common use case for accesing Finalized Chain History is to sync node from genesis
The EL clients don’t have access to HistoricalSummaries object that is needed to prove headers on the legacy History Portal Network. With this consideration and the fact that EL clients store all block headers, we no longer need to keep headers on the network. If this changes in the future, we can easily add them, and decide if we do so with or without proof.
After EL client syncs block headers, it can calculate which of the bodies and receipts it should store, and it can fetch them from the network. As the chain is progressing, the EL clients can just keep the bodies and receipts that they need. This eliminates the need and effectiveness of the bridges.
The disk requirements for EL clients is expected to grow over time. Therefore, it’s more reasonable for them to have fixed radius (compared to portal clients that were mostly using dynamic radius).
Using the block number and custom content_id function allows us to easily add batch requests in the future. This should improve the performance of synching the client from genesis.
Using rlp encoding for bodies and receipts is more alligned with the way the EL clients store and process data.
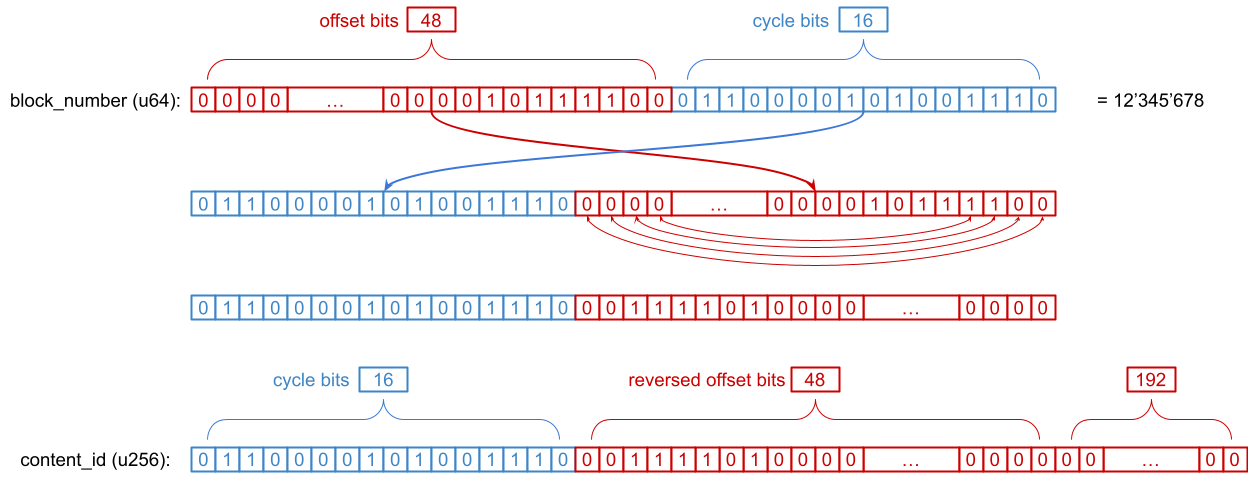
Content id function
The goal of the content_id function is to evenly spread content around domain space, while keeping consecutive blocks somewhat close to each other.
The blocks are split into cycles, where each cycle contains 65536 (2^CYCLE_BITS) consecutive blocks. Blocks from a single cycle are evenly distributed across entire domain space. Blocks from different cycles are offset in order to prevent multiple blocks mapping to the same content_id and to spread content more evenly.
Visualization of this idea is shown in the following image.

We achieve this by manupulating bits of block_number (uint64):
- 16 least significant bits (
cycle bits) and 48 most significant bits (offset bits) are swapped - Offsetting blocks from different cycles in a desired way is done by reversing the order of
offset_bits - Finally, we append zeros at get a value from the domain space (
uint256)
The following image shows this process for a block number 12'345'678.
{kind=link}
{kind=link}
Interaction with distance function (XOR)
Because we use XOR as a distance function, it’s possible that the radius doesn’t cover continuous section of the domain space (resulting in “holes” in the stored range). This is not a big concern because:
- It is guaranteed that at least half of the radius will be continuous
- This continuous section will include the
NodeId
- This continuous section will include the
- If the radius is power or two, then the entire stored range is continuous
- If we assume that clients use fixed radius, then they can enforce this
Choosing CYCLE_BITS
The choice of the CYCLE_BITS has two tradeoffs that should be balanced:
- bigger value implies that each peer will store fewer longer sequences of consecutive blocks, rather than many shorter sequences
- bigger value also implies that if there is more demand for certain range of blocks (e.g. towards the head of the chain), the same nodes while take on the burder for longer to serve those requests
The value CYCLE_BITS=16 is chosen because it simplifies function implementation in most languages (manipulation on byte vs. bit level), and because if we assume that each peer stores at least 1/256 (≈0.4%) of all content, then they will also store sequences of at least 256 consecutive blocks (which feels like the a good balance).