“You cannot do anything on the Ethereum Blockchain you couldn’t do on a smartphone in 1999.”—Vitalik Buterin
The World Computer
Would you rather build a world computer, or a world smartphone orbited by a number of broken Nokias, where the communication between the Nokia devices and the smartphone is implemented as EOAC (Ethereum Over Avian Carrier), but with the caveat that the birds have contracted Avian flu? If the latter case sounds like Layer-two-based scaling you’ve got a strong sense of the Ethereum ecosystem right now. Why, in reality, has it been so hard for Ethereum to scale while remaining synchronously composable, secure, and decentralized?
One Thread to Compute the Universe
Well it turns out that blockchains are not really instantaneously decentralized: they merely act as a round-robin election system for proposing state-changes, so at any one instant, one node is in control, and only one thread is running. How do you scale a single-threaded smartphone into a multi-dimensional world-computer? The answer is you don’t run the entire universe on one sequential thread, even if you switch the processor every 12 seconds, and even if you rollup some of the computation from an unknown darkness; after all, a chain is only as strong as its weakest link.
A better solution would be to homogenize the world-computer’s execution across the network, and to homogenize the storage of the world-computer’s state —and maybe history— across the network —after all, homogenizing coordination is what decentralization is all about, and data-storage and state-execution are just units of coordination. Data availability sampling solves the state homogenization problem by distributing the storage of data and state across the validator-set using storage commitments, erasure coding, and redundancy to prove that data is stored by somebody without everybody having to store it themselves. Since this quasi-research paper only discusses execution, allow me to make an assumption to set the —stateless— stage.
Storage Costs are Execution Costs
Storage cost is analogous to computational cost in a blockchain, a balance is merely found between the two bottlenecks. For example, take the current model of the Ethereum world-state and compare it to a stateless model: in the stateful (current) model, every node stores every byte of information, which has a quantifiable cost of storage for nodes, and the execution/verification of a block also has a cost of computation (quantified as gas) that every node incurs; in a (radically) stateless model, every node may only store the root of a trie of the world-state (a less radical version would still store the world-state just without the storage tries), but every node still incurs the computational cost of executing/verifying every block. In the stateless model, a node executing a state-transition must first merkle-verify a merkle-proof that proves the values of the storage-slots being modified within the transaction.
This means that the economic cost to a node is shifted from storing the data on disk to verifying the proofs within execution. In this sense, storage cost and execution cost are one and the same; all storage costs are just execution costs shifted to the node’s disk. The same way mass is just (very) slow energy in the universe, the universe-computer’s mass is slow storage with an equivalence to computational energy.
If we assume the above stateless model, where storage costs are completely shifted to execution costs, we radically simplify the problem: now all we must do is scale the execution throughput and the blockchain-trilemma is solved, and then we can all finally go back to college after that long gap-year we took to help build Ethereum. Yay!
Sharding Made Sense, Fragmentation Doesn’t
Ok great, so how do we scale the execution of the world-computer to accommodate not just the entire universe, but maybe even merkle-proofs that the state of the universe still makes sense? Sharding came in as a scaling solution in the early days of Ethereum as a headline-item of Eth-2.0; the interesting thing about sharding though is that it counter-intuitively does the exact opposite of what a blockchain should do: breaks the chain in some —usually a power of 2— pieces. Despite this, it has obvious benefits. Allow me to explain:
Blockchains are fundamentally consensus systems: if you want to coordinate with others you simply need agreement on the current state of the coordinated effort (world-state) and the parameters of how that coordination can change (state transition function). The problem is that blockchains trade an enormous amount of margin for scaling for this magical property that any user has the ability to interact with any other user at once, even though the vast majority of the time this feature goes unused. If Bob only ever trades Jeff coins on Uniswap, why should he pay for the right to send Gav coins to Alice, who only ever buys mountain-men portraits on OpenSea?
If there are many others like Bob and Alice, it makes intuitive sense to ‘shard’ their interactions with their respective platforms away from the main chain, and just have some trustless bridge (easier said than done) that allows them to move back to the main chain if they ever do happen to require, perhaps, trading mountain-men portraits for Jeff coins. This paradigmatically is superior than executing everything on one thread, but I’d argue it fails due to the complexity of actually deciding, and managing, when and how a new ‘shard-chain’ should be created, and how to manage the security of those shards intra/inter-shard.
This idea of sharding the chain was thus dropped in favor of a Layer-two-centric roadmap that effectively shards the security model by introducing new trust assumptions that, in my opinion, were never worth it just to accommodate demand that often merely goes towards either Casinos, Lazarus, or applications that likely didn’t even need Ethereum anyway. Layer twos do let Ethereum touch multiple corners of the blockchain-trilemma, but really some of those corners are arguably not fundamentally aligned with what makes Ethereum ideologically valuable, to put it in baseic terms.
Delegated Execution Sharding (DES)
“Give me a large enough snark, and somewhere to compute, and I will prove the world-computer.” —Aristotle
Scaling the chain then, by sharding the execution, instead of sharding the chain or the security model, seems like a fundamentally stronger paradigm. Here’s a general description of how this might work.
The concept is inspired by the Lean Ethereum Multi-Sig, which is a component of the Lean Consensus architecture some of the wizards over in Lean-land have bestowed us with. As us mere-mortals ponder the wizardry of Quantum Computing, they’re already architecting a new version of the Beacon chain that uses Quantum-proof XMSS (extended merkle signature scheme) signatures. The ‘Sig’ part of ‘Multi-Sig’ is where the validators create their signatures with XMSS, and the ‘Multi’ part is where snarks are used to aggregate those signatures across a committee to achieve something similar to pairing-based aggregation with BLS signatures; those committees’ snarks are then recursively aggregated with even more snarks (snarkception) to be included in one consensus block. The really cool thing about this is that it’s achieving the same effect as pairing-based aggregation, but computationally instead of cryptographically; though both ways of aggregating signatures are analogous to a kind of paralellization of consensus.
If you can parallelize consensus in this way, why can’t you do the same with EVM execution? You can, and because snarks don’t (really) increase with the size of the data being proven, there’s very little additional overheard; the caveat is that you can really only efficiently parallelize transactions that don’t touch the same state. Really though, there’s rarely never a margin of parallelization available, and the existence —and importance— of BALs proves this. Really, to make this work, all you must do is expand what we already have with BALs to execute a block across multiple threads, but since a validator has finite threads, if we keep expanding the gas limit we can move the execution to another ‘execution-committee’ that executes its own subset of the transactions, but since you cannot trust another committee’s threads, snarks are used to prove valid execution without naive re-execution; this lets you homogenize the execution of the block across a set of execution-committees in the exact same way the Lean Multi-Sig homogenizes attesting across a set of signing committees. If you assemble execution-committees across the validator set, and you assemble ‘super-committees’ that recursively aggregate N committees’ snarks, and you do this until you reach one final holy-grail snark the block-proposer computes that proves everything, you can execute an enormous amount with the overhead only being the time it takes to execute one regular block plus the time it takes to compute ~Log(N) + 1 snark proofs; note that there is additional overhead in verifying the proofs relative to how you organize the committees.
Delegated Execution Sharding allows you to scale the network breadth-first by leveraging all available resources, while keeping the bottleneck of real-time verification (validating) logarithmic, and the retroactive verification (syncing) time constant. This is contrast to Layer-two-based scaling, which only increases throughput depth-first, and introduces a number of undesirable security assumptions and ideological sacrifices in the process.
An Example of the DES Architecture in Practice
A practical DES architecture, at a high level, has three important features:
- Payload delivery scheme
- Dexary tree (delegated execution N-ary tree)
- Parallelization engine
Payload Delivery Scheme:
Scaling beyond a certain point requires that we optimize the way in which transactions are incorporated into the ‘sub-blocks’ that execution committees are computing. The problem is that the mempool may become so bloated due to the sheer volume of transactions that it becomes unreasonable for every validator to replicate the entire mempool across their nodes. A better solution is to use inclusion lists to vote on the presence of transactions in the network’s nodes’ mempools as an aggregate, and to then direct those transactions to the nodes that require them for their delegated computation. The metadata of the transactions in the inclusion list could be the transaction hash and some useful data for the parallelization engine, such as access lists. The metadata is what lets the consensus engine partition the transactions into ‘execution columns’ that are delegated to nodes in the dexary tree. This means that when the structure of the dexary tree is established for a slot, it can be revealed the transactions a committee must have available and the networking layer can coordinate propagation of the necessary data; note that since any one node is unlikely to have all transactions available, and only the hashes are public, it’s still difficult to determine which transactions a committee will be executing. Interestingly it’s worth noting that as the network scales, the problem of mempool availability starts to resemble the data availability problem, so it could be interesting the prospect that data availability sampling may be used to create a virtual mempool larger than any one node could store. In terms of the state retrieval itself, there are two ways it can be done: users can keep track of their own state like in the stateless model described earlier, where they include merkle-proofs in their transactions, or alternatively some form of data availability sampling can be used to spread the state across the validator set in a way that guarantees availability without replicating the state and storage tries across every node. This reason why the latter might be desirable is that in reality it can become extremely difficult to keep track of the value of your own state if it can be mutated by exogenous accounts, and a public contract could very well disappear by the tragedy of the commons taking hold, and nobody tracking its state; privacy also makes this nearly impossible.
Dexary Tree:
Every slot a tree-like structure is computed that delegates execution across the validator-set using RANDAO. This is called a dexary tree (delegated execution N-ary tree) and is used to split the validators into execution/aggregation committees. The tree is built so that execution committees are at the bottom as leaf nodes, and the aggregation committees are recursively pulling proofs of valid execution upwards throughout the tree, until a final proof is propagated to the root node, who in this case is the proposer for the slot.
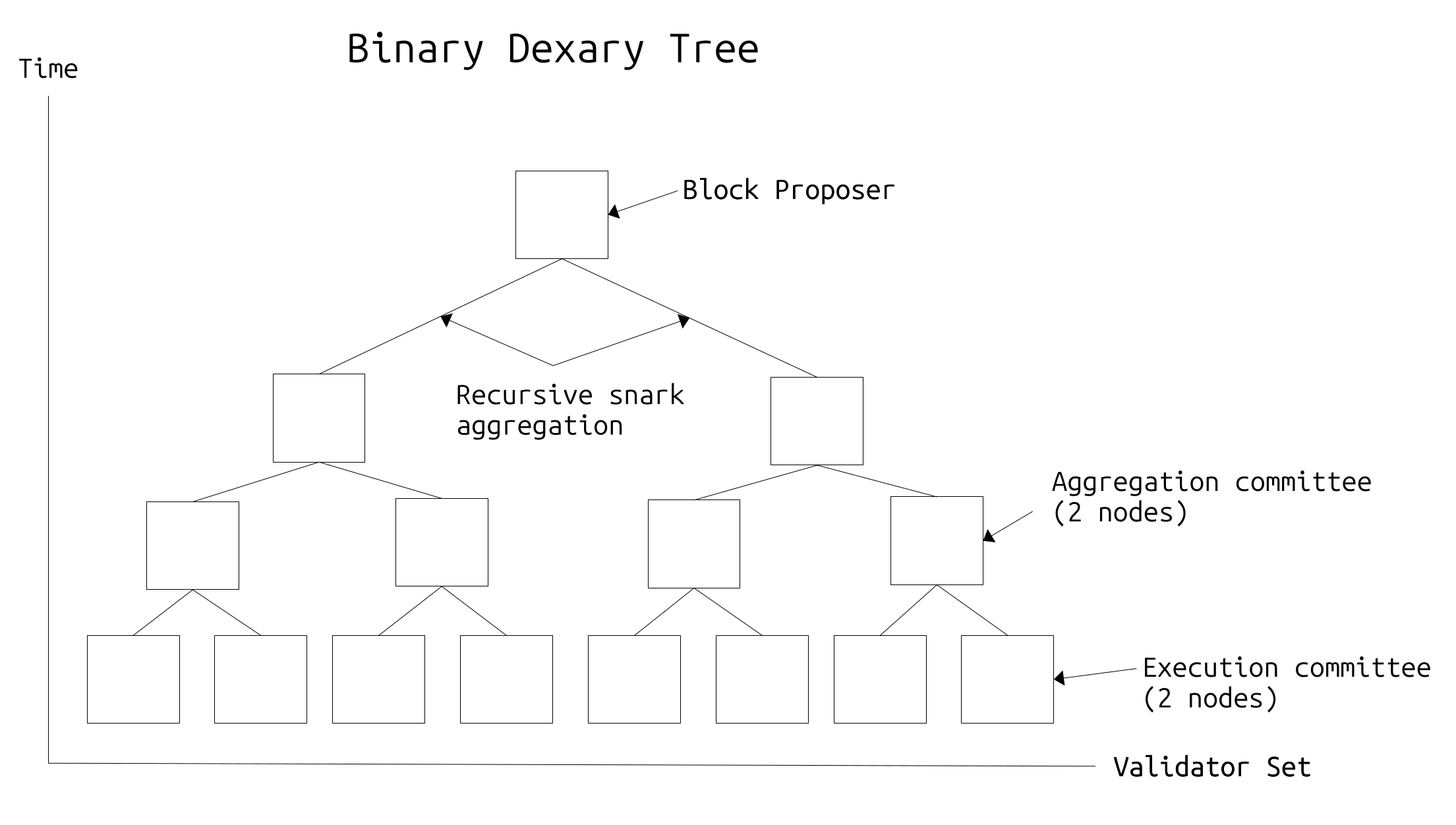
Execution committees consist of N nodes that compute the actual sub-block and create a snark proof of valid execution. N nodes are used to ensure redundancy; i.e there’s a low likelihood that all nodes in the committee will fail to execute and prove their sub-block, and send it to their aggregation committee, so the redundancy ensures resilience in case of asynchronous or otherwise unhealthy network conditions. The aggregation committee is tasked with verifying and snark-aggregating two execution committees’ sub-blocks; there are N nodes in an aggregation committee for the same reasons as mentioned above. The hierarchical proving structure means that an enormous amount of execution can happen in parallel, with the bottleneck for proving the validity of said execution being only logarithmic to the number of validators, i.e roughly:
execution + aggregation time = t + b + vN×LogN(c) + p×LogN(c)
where,
t = time to execute one sub-block
b = time to prove one sub-block
v = time to verify one snark-proof
c = number of validators
p = time to compute one recursive snark proof
In reality since the tree is structured in a way where there are N nodes in every committee, and every committee is a new branch of N committees in the tree, the tree would to built like a geometric series:
1 + N×N¹+ N×N² …
This happens until the sum is greater than the number of validators, whereupon the number of validators minus the second last sum divided by N becomes the number of execution committees.
Note that the networking bottleneck is relatively minimal and actually quite optimized since every node knows which committee it is in, and thus which execution/aggregation committee(s) it must communicate with. The bottleneck can be made even more minimal if the execution committees compute zk-snark proofs for their sub-blocks; i.e they prove a valid set of transactions existed to compute their sub-block without revealing the exact details of those transactions. The forced inclusion and obfuscation of the mempool also makes it much harder to extract value through toxic MEV.
One interesting thing to note is that the dexary tree can be computed in a slot in a way where the structure of the entire tree is not revealed, so any individual validator only knows its own position in the tree; this helps avoid any DOS vectors while also maintaining privacy: since, as mentioned above, zk-snark proofs of valid execution can be used to prove a sub-block’s validity, it’s impossible for any one node in the tree or a post-active validator of the chain to determine exactly what transactions occurred. Essentially what the dexary tree achieves is an EVM whereby its execution scales with the number of validators. In the current model, since any one node must be able to store the entire state of the world-computer, and re-execute any one block, the most that you can scale the execution is that which one individual node can bear; lets call this the decentralization computability limit (DCL). The throughput of the current EVM is exactly one DCL, but with dexary trees, you can scale that to the number of c / N minus the sum at the second last step of the geometric series above DCLs in the optimal case of parallelism:
No. of DCLs (executing validators) = c / N - (N×N¹+ N×N² …)
The geometric series is the validator-space occupied by aggregation committees’ members.
This leads to a fundamental realization about the problem with sequential execution: each validator contributes the same resources to the execution of the chain, regardless of the magnitude of their own stake —really though, it’s safe to assume a validator that can contribute 64 ETH instead of 32 is capable of contributing one more computer to the network; this is fundamentally an imbalance that needs to be remedied. It’s also worth noting that the fact that statelessness and succinct proving make the chain easier to verify boosts the level of decentralization in terms of reading and syncing; an even greater effect, however, is that the resources required to participate in validating the chain scale with the amount of stake contributed. This makes it incredibly difficult to scale a staking operation, and makes liquid staking almost infeasible, while keeping the hardware requirements minimal for solo-stakers: it’s easier for one 32 ETH solo-staker to run a validator on desktop hardware than it is for Tom Lee or Blackrock to purchase hundreds of thousands of devices to be eligible for staking, just to acquire the same yield as the solo-staker; this is fundamentally different than the ASIC arms-race in proof-of-work however, as the additional hardware provides no additional control over consensus, nor any additional margin of profitability, and actually contributes to network throughput. Thus any marginal overhead the dexary tree may bring can be balanced out by the fact that the vast majority of the additional overhead is felt by the wealthier stakers, which is in contrast to the expansionary hardware requirements policy in the current model, where increases in node requirements hurt the long tail of stakers/validators/users the most; I’d argue that the former is fundamentally more Cypherpunk in principle, as the individual defender has a stronger defence —and thus upper-hand during consensus attacks— against the organized attacker.
Parallelization Engine:
Once the dexary tree is built, and the execution committees have received their mempool data, they must have available an algorithm for best executing the transactions on the state in parallel, and the aggregation committees must have a means by which they can aggregate the state changes across the execution committees.
An intuitive way to achieve parallelism on a basic level would be to create a simple algorithm that gives each execution committee a batch of transactions that don’t touch the same state as the transactions in any other batch; the problem with this is that you can never really shuffle the execution columns in a way in which there’s no cross-column dependencies —it’s worth noting all of this shuffling and optimization is handled on the consensus layer when the inclusion list and dexary tree is built. A better solution then is to just modify the above method with the additional case that if there’s a way to optimize the execution by shuffling the columns such that there is both adequate parallelism and a minimal number of inter-column state-collisions, the overhead of the intersecting inter-column collisions that need to be resolved is traded for the optimized parallelism. In practice the inter-column collisions would need to be resolved at higher layers; the scheme for doing so could involve a rule that if a transaction touches the same state as a batch of other transactions in another execution column do, it must be only executed as a partial state-change by the source committee up until the point of intersection, and that the execution may be finished by the aggregation committee that first receives both state-changes that collide in their execution columns. Since at any one level in the dexary tree, the only intersecting state changes are those known intersections, they can safely just simply aggregate the state changes propagated to them to get their recursively aggregated state. It’s also interesting the idea that instead of resolving intersections at higher layers, they can be solved directly at the base of the tree by the execution committees themselves. This could be done by creating committees that overlap in their participants, and thus their state-changes at the position the intersection occurs; this comes out to Amdhel’s law with additional networking overhead, but I’m not certain how much better this real-time stitching together of the state-changes may be.
In the above case the wrath of Amdhel’s law can be somewhat minimized by partial transaction execution, but it’s an extremely messy process that just adds additional overhead. But how about we return to the wonderful-world of BLS for a moment to make an observation: the reason why BLS signatures can be aggregated is because of weird voodo magic called a cryptographic pairing; a really nice property of pairings is this:
b(m, k) + b(n, k) = b(m + n, k)
This is really cool because it means instead of taking two signatures that sign the same data and verifying them separately, you can take both and just add them together and you know that the resulting signature is only valid if both signatures actually signed the data. I bring this up because, even though the XMSS snark-aggregation that mimics the BLS aggregation was the inspiration for delegated execution sharding, you can come full circle and realize the properties of BLS pairing-based aggregation are actually really useful for parallelization. Here’s why:
Imagine this equation represented an EVM state s, tx inputs t1 and t2, and the state-transition function phi instead of just signatures and data:
Φ(t1, s) + Φ(t2, s) = Φ(t1 + t2, s)
This is analogous to the BLS aggregation, and the implications of this equation being true would be that infinite paralellizability would be possible, as you could always split up transactions that touch the same state into subsets that you can delegate the execution of across the validator set. It would mean that none of the shuffling on the consensus layer would need to occur, and there would never be any cross-column intersections that need to be resolved, since the math itself just allows for the state changes to be combined at the end, even if they have intersecting interactions with the state. Now I know what you’re thinking:
“Are you out of your god damn mind, you maniac? You can’t just pretend a cryptographic operation that is just bilinear mapping vector multiplication with properties of a pairing can somehow be Turing-complete.” —You, probably
The best kind of problems are the ones that are impossible to solve, and the best kinds of solutions are the ones that make no sense. Obviously I’d like to point out that the idea of “Turing-complete bilinear mappings” I’m describing is, in fact, mathematically erroneous; it is nonetheless an interesting thought experiment. It’s interesting to point out that the idea of this kind of computation does exist in a modified form; that is, fully homomorphic encryption schemes use this exact property to execute computations on encrypted data:
e(a) + e(b) = e(a + b)
In this case, the sum of the encrypted inputs a and b is equal to the encrypted sum of a and b. The computation is addition here but the idea is to compute over general-purpose circuits. Really what we need is for the encryption function to instead be the state transition function, and for the addition to be a concatenation operation that adds the state-changes. A better way to describe the property we need then may be as a ‘Turing-complete homomorphism’. I know of no such scheme, and it remains purely an imaginary thought experiment; but hey, if idealistic internet wizards can invent a magical computational substrate for the universe, maybe magic homomorphic computation with the properties of pairings is possible too. After all, there is only one thing we’re all looking for:
“What troubles you, mountain man, what is it that you are searching for?”
“One equation to describe the world-computer.”
When the dust settles, and the war is won, the world-computer will have outlived us all.