“you havent addressed that L3 is pretty much useless over L2 when trying to optimize gas fees, check out What kind of layer 3s make sense? by vitalik buterin”
The article explains : “If we can build a layer 2 protocol that anchors into layer 1 for security and adds scalability on top, then surely we can scale even more by building a layer 3 protocol that anchors into layer 2 for security and adds even more scalability on top of that ?“
But some problems may occur : “There’s always something in the design that’s just not stackable, and can only give you a scalability boost once - limits to data availability, reliance on L1 bandwidth for emergency withdrawals, or many other issues.”
Yet, the article confirms that you can scale computation with SNARK : “SNARKs, can scale almost without limit; you really can just keep making “a SNARK of many SNARKs” to scale even more computation down to a single proof.”
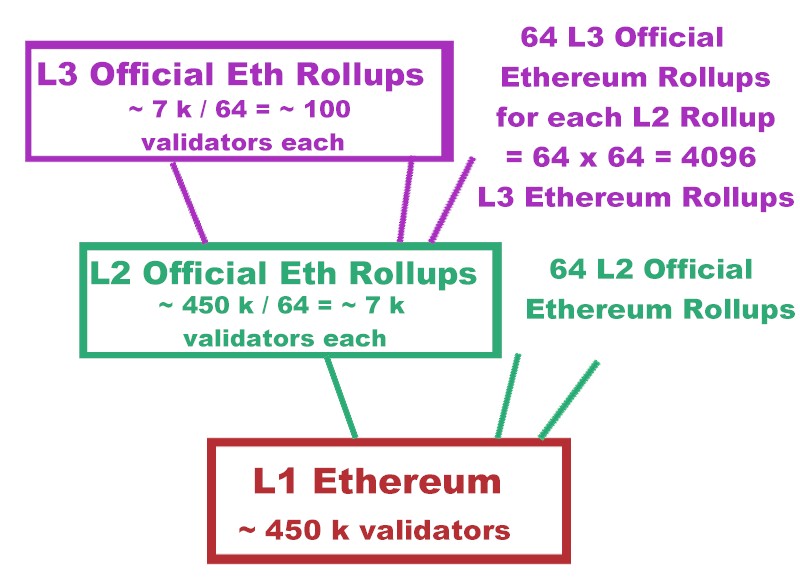
Regarding computation, the proposed model of L2 and L3 Official rollups is therefore possible, with a Zk-Rollup implementation.
The problem of data availability is more complex, as the article explains : “Data is different. Rollups use a collection of compression tricks to reduce the amount of data that a transaction needs to store on-chain: … About 8x compression in all cases. But rollups still need to make data available on-chain in a medium that users are guaranteed to be able to access and verify”
There are solutions to increase data availability in a context of rollups on top of rollups.
An article on Coinmarketcap about EIP-4844 explains : “it has been proposed that the data can be stored elsewhere in a way that it is easily accessible like several applications/protocols that provide that service.”
To increase data availability, a solution would be to store data elsewhere, not only on the compressed blockchain. Blockchain is basically a security measure intended to secure transactions, so they cannot be modified.
But the data could also be available elsewhere.
L1, L2 and L3 blockchains could have a buffer for data availability. In this buffer, there would be a list of all the addresses of the blockchain with their balances in real time, and a list of the characteristic of the smart contracts implemented on the chain. These buffers should have enough information to validate new transactions without having to do expensive calldatas on the blockchain, at least most of the time.
If the buffer is too big, it could be sharded between nodes operating on the same blockchain.
Being uncompressed and easily accessible, the buffer would solve the problem of data availability.
atm the ethereum proposed way of sharding is just danksharding (data storage sharding), afaik we aren’t sharding the execution layer any time soon so no fragmentation as it would ruin the UX
Rollups can be seen as a way to shard the execution layer. Some rollups are popular, and this fragmentation doesn’t ruin the UX.
Regarding data sharding, there is a consensus that it is necessary, because the monolithic L1 chain is too heavy.
But :
-
there are several ways to shard data. I would prefer a temporal sharding of data. Validators should have the option to store only a random period of the blockchain history (if they store more, they are more rewarded). Storing only a part of the blockchain would not be a problem for data availability with the proposal of buffer.
-
sharding data doesn’t mean sharding the execution of the L1 chain. If the L1 chain is divided into different shards working in parallel, security breaches may occur, with risks of double spending attempts, looping problems, contradictory instructions …
-
an interesting post about sharding and parallelization comes to the same conclusion : “Rollups + data-availability sharding are substantially less complicated than most sharding proposals.”
-
as the post explains, a major argument in favor of rollups is that “a single honest party” is required, enabling to push “heavy-duty execution” on rollups
-
the proposed model of L2 and L3 official Ethereum rollups could come along with buffers to increase data availability, and a sharding of data, preferably a temporal sharding.
“i believe proposer/builder separation will make things better so validators/proposers won’t need to store a load of data, rather it ll just accept bids from builders, plus light clients are being championed which are meant for mainstream users. not everyone needs to run a full node”
Yes I agree that validators shouldn’t be required to store a lot of data. Once data is sharded, one way or another, it will be possible to run lighter clients.
“perhaps ether balances could be merged, but how about tokens? what if there are multiple instances of the token on different rollups? how about different create2’d instances of the same contract with the same address on different rollups with different state?”
In the case, very hypothetical, where a fragmentation of data should be reversed, it’s possible to add an identification linked to the original shard.
It’s also possible to identify different contracts with the same address on different shards.
More, if there are official L2 and L3 rollups, it may be possible to shard the addresses. For example, a certain range of addresses could be assigned to L3 rollup n°1, another range to L3 rollup n° 2, …
As a conclusion, L1 Ethereum runs about 1 million transaction per day. Instagram and Facebook have around 1,5 billion daily users. In case Ethereum is to become as popular, with zero fee transactions, there may be around 200 million daily users, who would process an average of 3 daily transactions (utility token, gaming token, fan token, NFT, …). It means the Ethereum ecosystem should be able to handle 600 million to 1 billion transaction a day.
This is a x1000 factor compared to the current situation. It may be possible to reach such scalability with L2 Rollups, or other L2 solutions, but models with L3 rollups should also be considered.
A benefit of L3 rollups is that they write Zero-Knowledge Proofs on L2 rollups, which is much cheaper than putting Zero-Knowledge Proofs on the L1 chain. So the use of L3 is more in line with the goal of zero fee transactions.