i don’t see it. can you share the right link?
zeko-labs/developer_demos/tree/main/agent_coordination_protocol-financial_intelligence
Great protocol design for the anonymous usage layer. The RLN + refund accumulation approach elegantly solves request unlinkability.
However, one gap I noticed is the deposit itself. The opening example has a user depositing 100 USDC into the smart contract. That deposit is a public on-chain transaction linking the user’s address (and identity, via exchange KYC trails) to the contract. Chain observers know the user is using private AI services before they’ve made a single query.
This gets worse with AI usage patterns. Unlike person-to-person transfers where users can deposit well in advance and withdraw at unpredictable intervals, AI billing is high-frequency and immediate. A developer deposits 100 USDC, and within minutes the system shows activity from a new identity commitment. The temporal correlation between deposit and first usage is trivially linkable, especially for smaller deposit amounts with sparse anonymity sets.
There’s also asset-level risk. USDC’s admin blacklist function has been used to freeze funds in privacy-adjacent contracts before, meaning the privacy guarantee depends on a centralized issuer’s continued cooperation.
Two possible directions worth exploring:
1. A shielded deposit mechanism where deposit amounts are hidden inside a ZK proof and the depositor’s link to their identity commitment is broken at deposit time, not just at usage time. If funds are “born” inside the shielded environment (e.g. minted against overcollateral rather than deposited as an existing token), the temporal correlation attack disappears entirely.
2. Integrating proof-of-innocence (per Buterin/Soleimani/Illum’s Privacy Pools model) so that users can voluntarily demonstrate regulatory compliance without breaking protocol-level privacy, addressing the W-9/KYC concern raised in another comment.
People that want privacy can just run at a local machine, couple of years in the future any PC will be able to run LLM
I just totally dont see the use case, it seems to be a product designed by CS PhDs for CS PhDs.
It is fantastic math, do not get me wrong, but who would use it and why? I do not mean to be nasty, just realistic.
I don’t think we have any evidence yet that this is necessarily going to be true. It does seem likely that models equivalent to today’s SOTA models will run on consumer hardware in the future, but what is far less clear is if you won’t be able to run a better model on hardware at scale. As long as bigger hardware yields better/smarter/faster AIs, there will be demand for renting access.
Beyond that though, even if LLMs do plateau and shirk, this protocol can be used for any other steam-like thing that one wants to pay for. I would love something like this to bypass captchas for example.
Thank you for the proposal!
It seems to me that RLN deposit here tries to fulfil two purposes at once: slashable stake to discourage misbehavior, and payment for service provision. I agree that RLN fulfils the former functional requirement, but I’m not sure about the latter.
Concretely, we can view the payment mechanics here as a payment channel. (Disclaimer: I’m seeing payment channels everywhere because I’ve been working on Lightning for a few years previously.) Still, I think channel mental model is applicable. We want value transfer from the user to the provider proportionally to the amount of service provided, without on-chain transaction per each request. The provider must be sure that at any time it can claim on-chain the fair share of the user’s deposit, proportional to services provided.
Imagine deposit D pays for 100 requests in advance. For simplicity, assume equal cost for each request, and no refund mechanics. When does the provider claim D? It shouldn’t be immediate - that would mean the provider can take the deposit and run away without providing any service. It also shouldn’t be after every request - that would be equivalent to one on-chain interaction per request, which we want to avoid. Therefore, the provider will claim once in a while, for example, every 10 requests.
But then, what if the user makes 9 request, and then deliberately double-signs and tries to slash its own deposit? (Cf. “self-slashing” concern mentioned by @4aelius.) This would introduce a race condition with some non-zero probability that the user ends up with its own deposit and service provided. Rationally (and considering user’s anonymity), this should be a dominant strategy, right?
More generally: RLN is well suited for rate limiting, but is it also a good payment mechanism?
2 Likes
Not sure how relevant this is but we’ve been working on fully P2P communities / P2P bulletin boards for a few years. we even posted the idea here in 2021 Design idea to solve the scalability problem of a decentralized social media platform
in our design, most of the things are P2P, but not on any blockchain, peers join a libp2p gossipsub topic, and they use an arbitrary antispam challenge chosen by the community owner as the validation (antispam) function.
some mechanism to deposit funds somewhere and get credits to publish to the libp2p gossipsub topic is one of the most open and obvious way to do it, so it would be really useful for us and other similar projects like waku, farcaster, etc that use a similar antispam/DDOS strategy.
we are still seriously working on this project and have a few users and P2P communities running, but getting the antispam challenge right is the most difficult part at the moment. it’s difficult for users to easily onboard, yet also prevent people from flooding with spam.
My experience using LLMs is wildly different from this, I would estimate with no refunds my overhead would be like 100x. eg. when I sent requests to GPT 5.2 etc with OpenRouter, I need to have a >$5 budget to make requests, to cover the max possible size, but on average each request costs like a cent.
The problem is that the resource consumption of requests is extremely variable. “write a 10000 word essay” and “translate ‘你好世界’ to English” go through the same prompt path. Or “prove [ X ] theorem”, “research how to do [Y]”, and many other tasks are tasks of the form “search until you find it”, whose probability distribution if you modeled it out would probably be some infinite-variance Levy-ish distribution. Sometimes it takes 100 thinking tokens, sometimes it takes 5000, occasionally it takes 100000.
This isn’t theoretical. vLLM’s chunk-based prefix caching had a documented timing side channel (CVE-2025-46570, GHSA-4qjh-9fv9-r85r), where cache-hit timing differences achieved an AUC of 0.99 with 8-token prefixes, enough to verify whether two requests share context. Patched in vLLM 0.9.0, but the fundamental issue is architectural: any shared-cache inference server leaks request similarity through timing unless explicitly mitigated.
Are you assuming here that the inference server is a TEE, and describing a TEE leak? I was actually assuming a worse security model than even this: the entity running this is a forwarder to OpenAI/Anthropic/…, and so the ultimate inferring entity is an entity that we cannot trust at all.
So yeah, preserving privacy in such a design would require several things on top of ZK-API: probably (i) mixnets, and (ii) having a small local model sanitize requests. Even that would be far from perfect, but it would be much better data leakage prevention than nothing, and importantly it would not be fragile: the key thing that ZK-API ensures is that even if eg. 80% of your requests get linked together based on content and timing, the remaining 20% (which might be about totally different subject matter) stay anonymized.
2 Likes
You can easily control the budget by telling the LLM to reply in short sentences.
You can even tell it in the prompt exactly what your budget is, and it will stay within that budget.
Computational time is proportional to the square of the sum of the prompt length and the response length. My understanding, though, is that commercial providers charge linearly, not quadratically.
1 Like
We shipped a simpler version of this problem last week — x402 + SIWX (CAIP-122 wallet sessions). The insight we landed on: you don’t need ZK for the common case. You need it for the adversarial case.
Our flow: pay once on Base → server issues session → subsequent requests authenticate via EIP-191 wallet signature in microseconds. No RPC, no on-chain verification, no nullifiers. The signature proves you're the same
wallet that paid. 290 lines of code, same-day implementation.
The tradeoff is obvious: we sacrifice unlinkability. The server knows your wallet across requests. For our use case (AI inference routing across 13 providers), that's acceptable — the user WANTS session continuity.
But @omarespejel raises the real issue: even with nullifier unlinkability, the server sees token counts, latency, timing, and prompt structure. That's a richer fingerprint than the wallet address itself. So the ZK layer
protects against a threat model that the inference layer already violates.
The quantized pricing suggestion is underrated. Fixed tiers (we use 4: FREE/LOW/MEDIUM/HIGH) eliminate the refund circuit entirely. You're not metering tokens — you're buying access to a tier. Simpler contracts, simpler
proofs, and the privacy surface shrinks because all MEDIUM-tier requests look identical on-chain.
Where ZK becomes essential: multi-agent workflows where Agent A shouldn't know that Agent B is also being funded by the same wallet. That's the real privacy boundary — not user-server, but agent-agent. PrivateX402 thread
addresses this more directly.
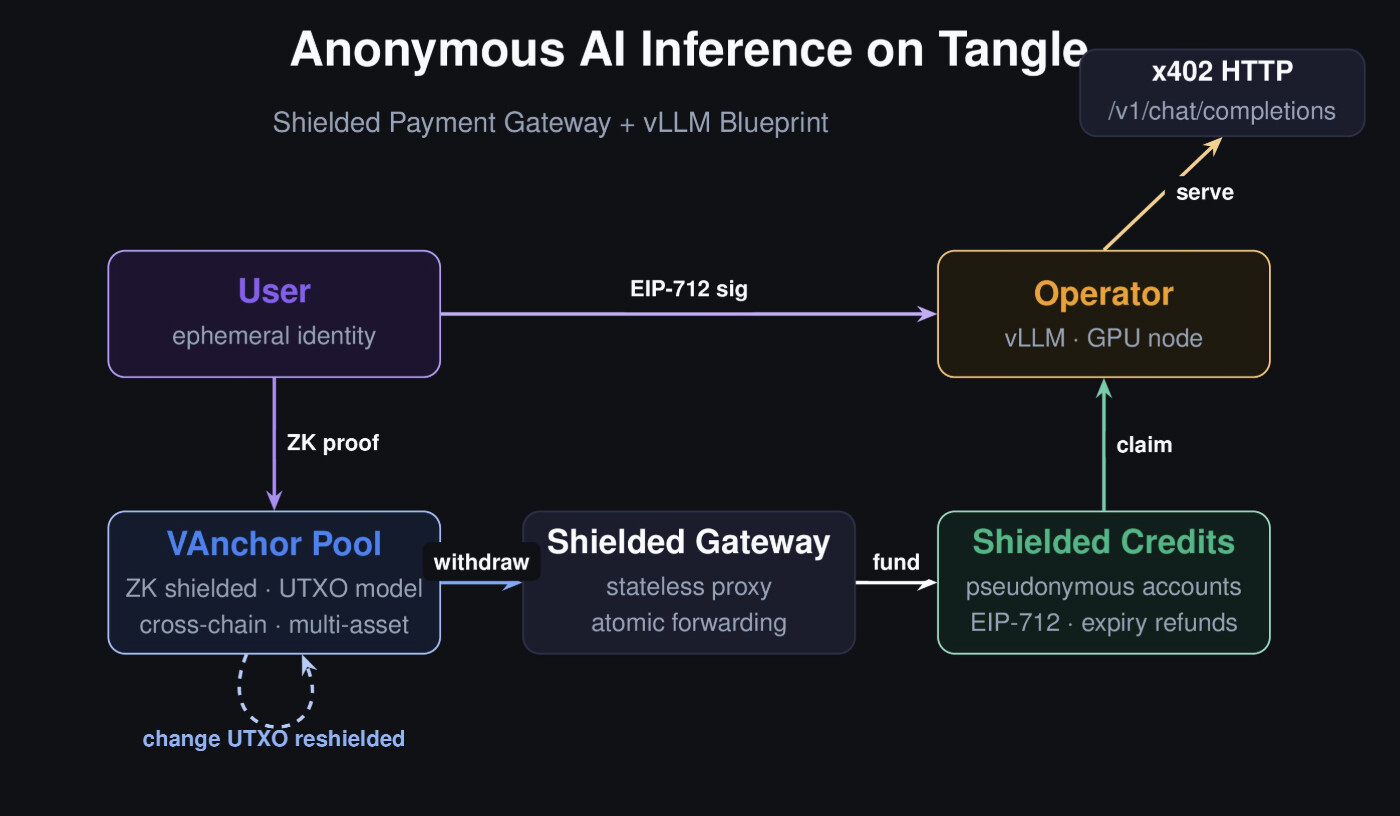
If anyone has some loose GPUs for this and would lend them for testing, I’m building a prototype of a system like this. It will serve any model compatible in vllm. You can build any type of service – from fine tuning jobs, to inference as a service – using the job system and allow people to pay for these services after withdrawing from a shielded pool.
The system combines 3 things. The first is a decentralized cloud protocol and SDK that supports subscription and per-use payment methods for service instances. The second is a shielded pool and RLN payment gateway that scales well for stablecoins on many chains – I had built and gotten this audited in the past. And the 3rd is a specific blueprint that defines an inference products.