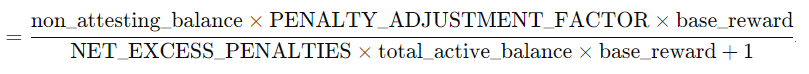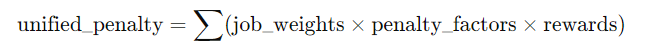This post introduces a concrete proposal for how correlated penalties could be done, in a way that maximizes (i) simplicity, and (ii) consistency with valuable invariants that exist today.
Goals
Replicate the spirit of the basic design proposed here.
Same average validator revenue as today, at all levels of “percent attesting correctly”. This should hold as a hard invariant, even against attackers with a large percent of stake trying to break it
Same penalty as today from failing to make one attestation, on average
Validators should only be rewarded for sending an attestation, never passively
Mechanism
We set two constants: PENALTY_ADJUSTMENT_FACTOR = 2**12, MAX_PENALTY_FACTOR = 4
We add a counter to the state, NET_EXCESS_PENALTIES
During a slot, let non_attesting_balance be the total balance that is not correctly attesting in that slot
Let R be the current reward for attesting correctly (computed based on base_reward and adjusted based on the fraction allocated to the job in question). This stays the same.
If a validator fails to attest correctly, they get penalized penalty_factor * R (as opposed to R as today)
At the end of a slot, set: NET_EXCESS_PENALTIES = max(1, NET_EXCESS_PENALTIES + penalty_factor) - 1
Rationale
It should be easy to see that NET_EXCESS_PENALTIES tracks sum(penalty_factor[slot] for slot in slots) - len(slots). Hence, if penalty_factor on average exceeds 1 for a sustained period of time, NET_EXCESS_PENALTIES will keep rising until that’s no longer the case. NET_EXCESS_PENALTIES is part of the denominator in the calculation of penalty_factor, and so NET_EXCESS_PENALTIES rising will push the average penalty_factor values down until the average is below 1 (and likewise in reverse, if it decreases).
penalty_factor is proportional to the total non_attesting_balance of the current slot, and so for it to average 1, it must roughly equal the non_attesting_balance of the current slot divided by the long term average - exactly the design proposed here.
Because penalty_factor averages 1, average non-participation penalties are equal to R, as today. And so average rewards for a validator are the same as today, for any correct attestation rate, assuming that their incorrect attestations are uncorrelated with those of other validators.
PENALTY_ADJUSTMENT_FACTOR affects how quickly penalties can adjust.
Possible extensions
Make penalty_factor more “continuous”, eg. by putting the base_reward into the numerator that computes the penalty_factor (and into the maximum, and into the per-slot decrement) and then using it to compute penalties directly.
Explore smarter ways to apply this mechanism across multiple jobs (correct head attestation, target attestation…). The naive approach is to just apply it sequentially for each job, but there may be a smarter approach.
I‘m glad to see further progress in this work,the existing mechanism of correlated attester penalties, as described in your documents, sets a penalty factor based on the non-attesting balance relative to the total active balance, adjusted by a PENALTY_ADJUSTMENT_FACTOR. This penalty factor affects the net excess penalties, which in turn influence future penalty calculations in a feedback loop aimed at maintaining system balance.
Proposed Extensions
Making the penalty_factor more continuous:
The current system uses a discrete set of penalty values. A proposed extension is to make this factor more continuous by incorporating the base_reward into both the numerator and denominator of the penalty calculation. This would make the penalty adjustments smoother and potentially more responsive to changes in attesting behaviors.
Proposed Formula:
Penalty_factor
Applying the mechanism across multiple jobs:
Currently, penalties are applied in a straightforward, sequential manner across different attestation jobs (like correct head attestation, target attestation). A smarter approach could involve aggregating the impacts across jobs to apply a unified penalty that reflects overall performance more holistically.
Potential Approach:
Develop a multidimensional penalty system where penalties for different types of jobs are adjusted based on their correlation and impact on the overall network security and performance.
Example Formula for Unified Penalty:
where job_weights are predefined constants reflecting the relative importance of each job type.
Python Code Example
To simulate the calculation of the unified penalty, we can write a Python function:
I know in your first post you had mentioned the large “publicly known clusters”. For these groupings (where I think this will be most powerful), does this approach necessitate we agree on the clustering? Do we have any recourse if the clusters themselves don’t cooperate with identifying themselves as correlated attesters?
MAX_PENALTY_FACTOR = 4 seems to be on the low-ish side. I think it’ll force operators to handle liveness failures better rather than the stake to decentralize (which is mostly a win as well, ofc).
I agree, I feel like the max penalty factor needs to be parameterized to make it much larger.
Imo the tail risk has to be much higher for validators to change data centers / get out of cloud providers, at a penalty of 4 its unclear to me that validators would prioritize work to leave cloud providers.
We can be a bit more concrete with minimum costs here. The GCP SLA for users at scale appears to me to be 99.99% per month: Compute Engine Service Level Agreement (SLA) | Google Cloud . If they fail to meet that rate, and instead hit [99%, 99.99%). you get a 10% rebate off your entire months cloud bill. (Higher rebates at larger downtimes). I’m not sure how SLA’s for direct data centers work though.
1% availability loss / month is roughly 7 to 8 hours of downtime. .01% availability loss / month is 4-5 minutes.
I feel like a candidate way to contextualize a parameterization for max penalty factor here here would be to graph the following for X,Y “if 5% of Ethereum stake was in one cloud provider, and was down for X hours, they should miss out on at least “Y” times more than industry standard rebates”. Accounting for penalty factor starting around 1, and incrementing however high it will go with the update equation.