
By Lin Oshitani (Nethermind Switchboard, Nethermind Research). Many thanks to Conor for the detailed back-and-forth on crafting this document and to Aikaterini, Elena, Ahmad, Anshu, Swapnil, Tomasz, Jinsuk, Quintus, Ceciliaz, and Brecht for the helpful comments and/or review. This work was partly funded by Taiko. The views expressed are my own and do not necessarily reflect those of the reviewers or Taiko.
TL;DR
As we outlined in our previous post Strawmanning Based Preconfirmations, naive implementations of based preconfirmations introduce many negative externalities that require thoughtful consideration.
In this post, we will expand on the negative externalities of based preconfirmations by examining them through the lens of the L1 PBS pipeline. Then, we propose multi-round MEV-Boost, a modification of MEV-Boost that enables based preconfirmations by running multiple rounds of MEV-Boost auctions within a single slot. This approach inherits the L1 PBS pipeline and mitigates the negative externalities of based preconfirmations as a result.
Motivation
As Justin Drake defines in the original post, based rollups are rollups “where the next L1 proposer may, in collaboration with L1 searchers and builders, permissionlessly include the next rollup block as part of the next L1 block”. Using the MEV supply chain diagram, based rollups can be illustrated below:
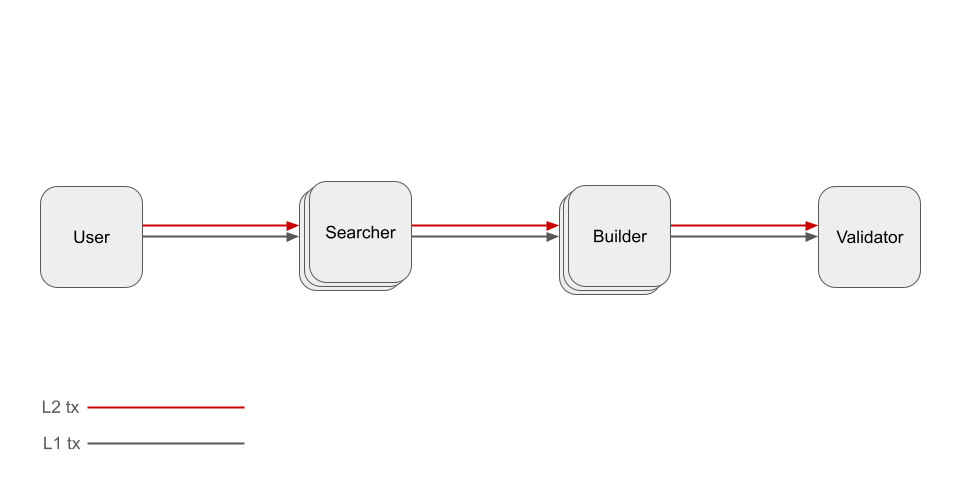
Notice that the L2 transactions, represented as the red line, go through the same process as the L1 transactions, represented as the black line. By effectively “piggybacking” the L1 PBS pipeline, based rollups provide two key benefits:
- Benefit 1: Since no additional actors (and thus no additional choke points) are introduced for L2 sequencing, based rollups fully inherit L1 censorship resistance, liveness, and credible neutrality.
- Benefit 2: Since the L1 and L2 transactions are sequenced by the same entity (the builder), based rollups enable not only synchronous L2-L2 composability but also synchronous L1-L2 composability.
Based rollups are great. They solve L2 fragmentation and sequencer decentralization while enabling L1 composability and inheriting L1’s censorship resistance, liveness, and credible neutrality. They are the only rollups that can have these properties simultaneously.
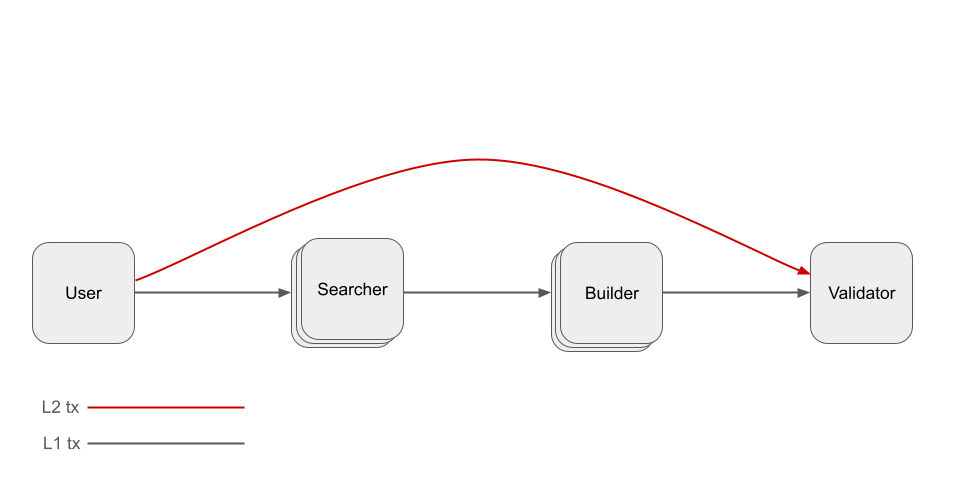
However, they have one large drawback: they also inherit the 12-second L1 block time. To address the slow confirmation time, Justin introduced base preconfirmations. In this approach, L1 proposers can opt into providing preconfirmations for based rollup L2 transactions, as shown below:
Since providing preconfirmations requires technical sophistication, most based preconfirmation designs include a delegation mechanism that allows validators to outsource the preconfirmation duty to a designated preconfer, as illustrated below:
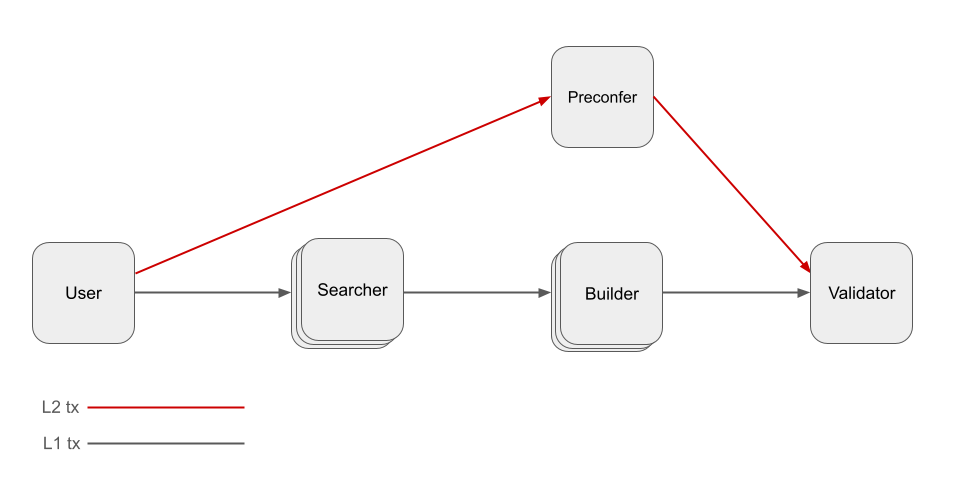
Notice that L2 and L1 transactions no longer share the block-building pipeline. As such, the benefits of based rollups are diminished:
- On benefit 1: We introduced an additional choke point to the system, the preconfer, which can censor L2 transactions or degrade L2 liveness by going down. As a result, the inheritance of L1 censorship resistance and liveness are degraded.
- On benefit 2: We now have two parallel block-building entities: one for L1 (the builder) and another for L2 (the preconfer). Consequently, L1-L2 composability now requires coordination between the builder and the preconfer. This adds complexity and can lead to builder-preconfer integration, where the proposer delegates not only their preconfirmation right but also the whole block-building right to the preconfer ahead of their slot.
In summary, by introducing preconfirmations, we lost the below structure:
As a result, many of the benefits of based rollups are diminished.
So, what if we keep this pipeline but run it multiple times within a slot to achieve fast preconfirmations? This brings us to the main contribution of this document: Multi-round MEV-Boost.
Multi-round MEV-Boost
At a high level, Multi-round MEV-Boost, or MR-MEV-Boost (pronounced “mister-mev-boost”, h/t Conor for the idea on the pronounciation :)) for short, works as follows:
- Split each slot into a fixed number of rounds, e.g., 4 rounds with 3 seconds each.
- Within each round, run a single MEV-Boost auction. As a result of the auction, a single partial block (a.k.a partial payload) will be signed and published, i.e., the partial block will be preconfirmed.
- The full block is created and published at the end of the slot. The full block should contain the partial blocks in the exact order they were preconfirmed without inserting any transactions before or in between.
Refresher: MEV-Boost
Before diving deeper into the proposed protocol, let’s quickly review today’s MEV-Boost PBS pipeline used in L1 Ethereum.
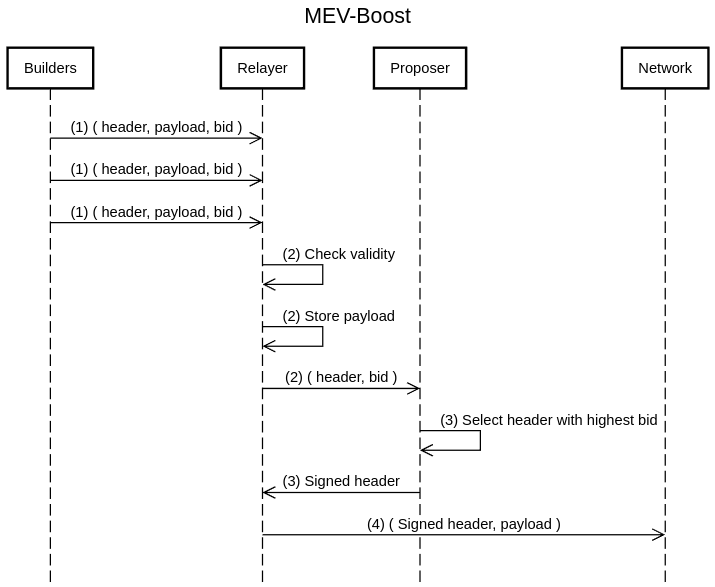
- Builders send the
header,payload, andbidto the relayer. - The relayer checks the validity (the
bidis correct, thepayloaddoes not contain invalid transactions, etc), stores thepayload, and then sends theheaderandbidto the proposer. - The proposer selects the header with the highest bid, signs it, and then sends the signed header to the relayer.
- The relayer propagates the signed header and corresponding payload to the network.
Protocol Description
In this section, we describe the MR-MEV-Boost protocol.
Protocol Flow Overview
To incentivize proposers to provide preconfirmations, we introduce a preconf transaction, where the payment of a preconf tip is conditioned on being preconfirmed. It will include the following information on top of the transaction payload itself:
tip: The preconfirmation tip paid for being preconfirmed.target_slot: The latest slot in which the preconf transaction can be included.target_round: The latest round within thetarget_slotin which the preconf transaction can be included.
The Preconf Transaction section will discuss the encoding and enforcement of these conditions.
Using this new transaction type, MR-MEV-Boost works as follows:
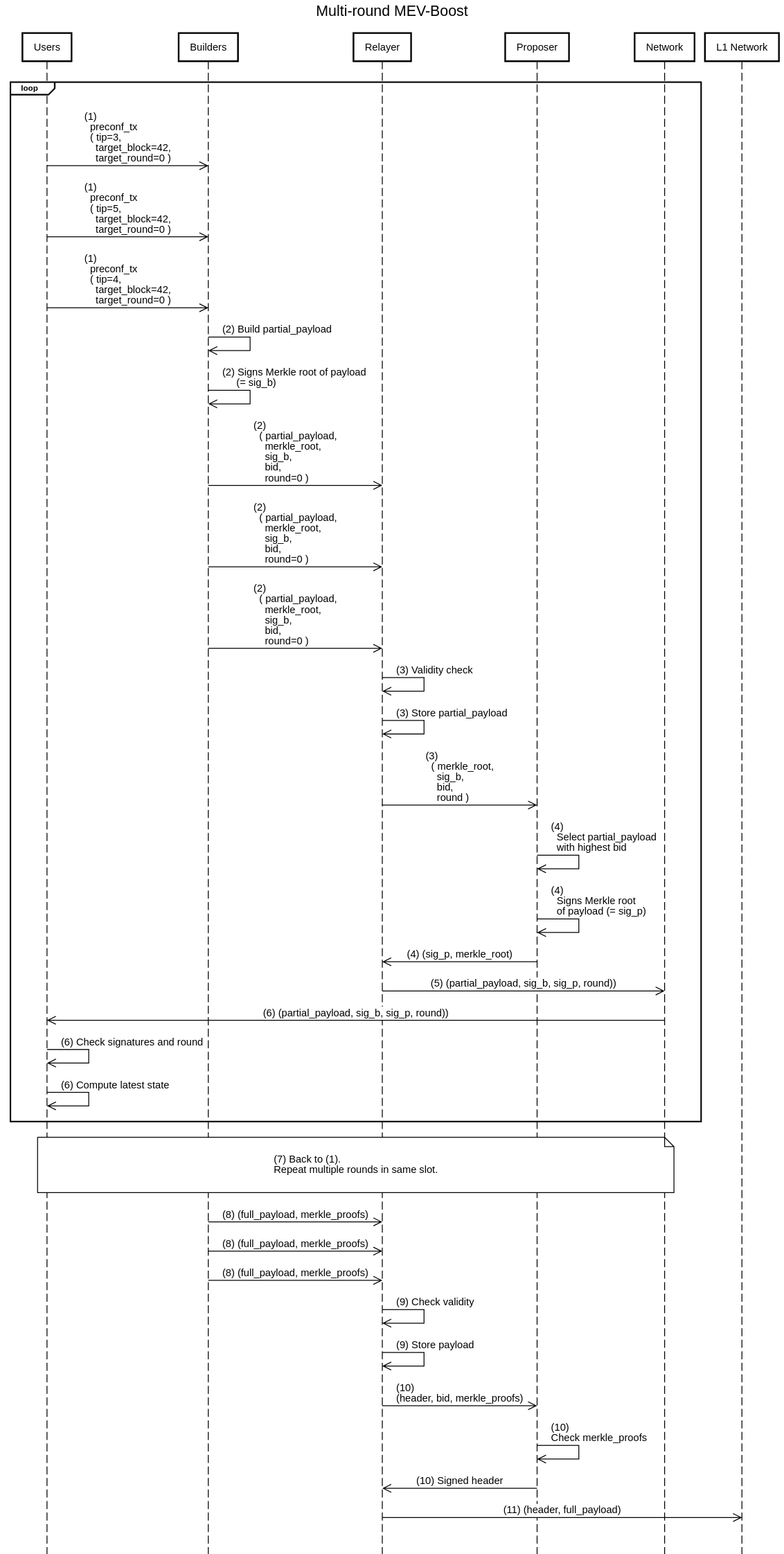
- Users submit preconf transactions to the builders. The submission can be through any order flow pipeline used in current L1, such as:
- Public mempool.
- Private order flow.
- Order flow auctions on MEVBlocker, MEV-Share, SUAVE, etc.
- The builders build
partial_payloads. The partial payload built by the builders should only include preconf transactions withtarget_slotandtarget_roundat or after the current block/round. To commit to this, the builder signs themerkle_root(denoted assig_b) and becomes subject to builder slashing condition 1, described in the slashing condition section. - The relayer checks the validity (e.g., the
bidis correct, thepartial_payloaddoes not contain invalid transactions, etc.), stores thepartial_payload, and then sends themerkle_rootandbidto the proposer. - Proposer signs (denoted as
sig_p) and returns the selectedmerkle_roottogether with the currentround. - The relay publishes the selected
partial_payloadand the associated round and signatures to the preconf network. Note that the preconf network is different from the existing L1 p2p network. Only entities interested in the preconfirmed state (partial block builders, relays, full-node providers, etc.) must subscribe to the preconf network. - End users—or, more precisely, the L2/L1 full nodes to which they are connected—verify that the
merkle_rootis signed by the proposer and is associated with the currentround. Upon confirmation, they accept thepartial_payloadas preconfirmed and execute it to update to the latest preconfirmed state. -
- to 6. is repeated multiple rounds within the slot. The number of rounds within each slot will be fixed. The final round will run concurrently with the full block MEV-Boost auction at 8.-11.
- to 11. The MEV-Boost auction is conducted for the full block. An important difference with the usual L1 MEV-Boost auction is that the
merkle_proofsare propagated from the builder to the proposer. These proofs prove that thepartial_payloads are included in the full block in the order they were preconfirmed without any other transaction being inserted before or between them. By validating these proofs, the proposer can ensure that the proposer slashing condition 2, described in the slashing conditions section, is not violated without needing to trust the relayer (h/t to Brecht for the idea of using Merkle proofs here).
Preconf Transaction
Let’s consider the encoding of the preconf transactions. For L2s, the additional fields can be introduced as custom encodings of the transactions. For L1, they can be implemented through an ERC-4337-style entry point contract that wraps the contract calls with additional information.
To enforce the expiration, the L2 execution layer (or derivation layer) and L1 entry point contract will filter out preconf transactions with expired target_slot. On the other hand, since the L1 is unaware of the concept of rounds, expiration based on target_round will be enforced via builder slashing condition 1, explained in the next section.
Slashing Conditions
To ensure that the full block matches with the preconfed partial blocks, the proposer will be subject to:
- Proposer slashing condition 1: The proposer must not sign two conflicting
merkle_roots within the same round. - Proposer slashing condition 2: The final
full_payloadshould contain all thepartial_payloads in the order they are signed and published without any other transaction being inserted before or in between.
Furthermore, to crypto-economically enforce the expiration of preconf transactions, the builder will be subject to:
- Builder slashing condition 1: Each
partial_payloadmust only include preconf transactions withtarget_slotandtarget_roundat or after the current slot/round.
We impose this condition on the builder rather than the proposer because the proposer does not see the partial payload when signing. An alternative approach would be to make this a proposer slashing condition and require the relayer to ensure the condition is not violated. However, this would necessitate the proposer trusting the relayer to avoid being slashed rather than only relying on the relayer to avoid missing a slot, as is currently done in L1 MEV-Boost.
User Actions
To mitigate the fair exchange problem, wallets or full nodes to which end users are connected should take the actions below:
- User action 1: Stop submitting preconf transactions if preconfirmed
partial_payloads are not published in a timely manner. For example, if we have 4 rounds in a slot, then stop submitting preconf transactions if apartial_payloadis not published every 3 seconds. - User action 2: Set
target_slotandtarget_roundto a reasonably close block and round (e.g., one or two rounds ahead). By doing so, builders are required to respond in a timely manner to preconfirmation transactions to avoid the preconfirmation transactions being invalidated.
More on how the fair exchange is addressed is described in the analysis section.
L1-L2 Composability
Since the partial payloads can contain both L1 and L2 transactions, builders can ensure L1-L2 composability by including L1-L2 transaction bundles in the partial payloads.
Non-opted-in Slots
When the current L1 slot’s proposer has not opted in as a preconfer, L1 transactions will be proposed by the current proposer, while L2 transactions will be proposed by the next opted-in preconfer in the lookahead (we follow Justin’s original based preconfirmation design here). This results in two simultaneous MEV-Boost auctions: the usual L1 MEV-Boost auction signed by the current L1 proposer and the MR-MEV-Boost auction signed by the next preconfer. As a result, L1-L2 composability and L1 preconfirmation will be lost during these non-opted-in slots. Note that this limitation applies to all off-protocol preconfirmation designs.
Analysis
In this section, we will perform an initial analysis of the proposed protocol and identify its drawbacks.
Have we solved the problems?
Let’s revisit the problems raised in the Strawmanning Based Preconfirmations post and see if and how MR-MEV-Boost addresses them.
Problem 1: Latency race
Latency races are when searchers fight to be the first to access the preconfer, leading to colocation or vertical integration. With MR-MEV-Boost, this issue is largely mitigated by preconfirming batches and conducting auctions within the batch, as it promotes competition based on price rather than speed. It is generally acknowledged that batch auctions help reduce latency wars compared to continuous first-come, first-served ordering, as described in this paper and this post.
Problem 2: Congestion
Congestion issues arise when searchers flood the rollup with probabilistic arbitrage attempts. With MR-MEV-Boost, this issue is mitigated as searchers are incentivized to participate in auctions rather than resort to spam.
Problem 3: Tip pricing
The MEV-Boost auction will handle the tip pricing of the preconfirmation. Furthermore, by introducing batching and auctions within the batch, proposers can price the preconfirmation tips more effectively (hence capturing revenue) than by providing a continuous stream of per-transaction preconfirmations.
Problem 4: Fair exchange
Let’s see how MR-MEV-Boost addresses the fair exchange problem, where the proposer withholds publishing preconfirmations to the user. Note that preconfers are incentivized to withhold preconf promises as much as possible to maximize their opportunity to reorder and insert transactions, thereby increasing their MEV.
There are two cases to consider:
- If the proposer withholds preconfirming partial payload (i.e., stops signing
merkle_roots ofpartial_payloads), users will stop sending preconfirmation requests (user action 1), reducing the proposer’s order flow and, consequently, revenue. - If the proposer intentionally publishes empty partial payloads, pending preconf transactions will expire after a few rounds (user action 2 and builder slashing condition 1), reducing the proposer’s order flow and, consequently, revenue.
In summary, end users monitor and enforce proposers’ honest behavior by linking the proposers’ revenue to the timely preconfirmation of partial payloads.
A potential alternative would be to introduce a committee to monitor and attest to the timely releases of partial payloads. However, this would require additional trust assumption to an external committee unless we enshrine the protocol into the L1. More on enshrinement in the future direction section.
Problem 5: Liveness
With existing based preconfirmation designs where preconfirmation duties are delegated ahead of the slot, liveness relies on this single external entity for the duration of the preconfer’s slot(s). On the other hand, with MR-MEV-Boost, liveness concerns are reduced as we do not introduce such “lock-in” to a specific entity before the slot. If some builders or relayers are unavailable, others can step in to maintain functionality. Moreover, even if the entire multi-round MEV-Boost pipeline fails, proposers still have the option to construct their own partial blocks and preconfirm them independently.
Problem 6: Early auctions
Early auctions are not introduced as preconfirmations are provided through the MEV-Boost JIT auctions.
Round Interval
How short can each round in MR-MEV-Boost be? If it is too long, it will degrade the user experience; if it is too short, it will impose excessive network and hardware requirements on builders and relays, thus hurting decentralization.
In each round, the relayer has two tasks:
- (A) Run the partial block auction.
- (B) Propagate the partial block.
Task (A) consists of the time it takes the builder to construct the block, the time it takes the relay to validate the block, and two network round-trips: one between the builder and the relay and another between the relay and the proposer. Assuming that block construction, validation, and network round-trips take 500 milliseconds each, we get a ballpark estimate of 2 seconds.
For task (B), considering L1 allocates 4 seconds for block propagation and 8 seconds for consensus, and no consensus is needed for partial blocks, a good upper bound for propagation time is 4 seconds. In practice, it should be much shorter because only block builders, relays, and full-node providers need to receive these partial blocks, and they have better network bandwidth and lower latency than average validators. Let’s assume 1-2 seconds for this analysis.
Combining 2 seconds for (A) and 1-2 seconds for (B) gives us 3-4 seconds per round.
These estimates are highly approximate, and further research and analysis are needed. Additionally, making the interval too short will intensify latency races toward the end of the batch duration, as described here, and should be considered.
Drawbacks
Next, we will outline the drawbacks of this protocol when compared to existing based preconfirmation designs, such as the one described in the original post. An analysis of more general drawbacks of preconfirmations will be reserved for future work.
No Speed-of-light Continuous Preconfirmations
MR-MEV-Boost does not provide speed-of-light preconfirmations with hundreds of milliseconds latency, like Arbitrum’s first-come-first-serve sequencer. Instead, it offers preconfirmations in batches with a few seconds of latency between them, similar to Optimism’s approach.
Solana and Jito provide an interesting case study on continuous versus batched preconfirmations. In Solana’s “continuous block building,” the leader streams (i.e., preconfirms) processed transactions continuously. Combined with Solana’s fixed low fee, continuous block building led to network spamming and latency races, causing validators to waste 58% of their time processing failed arbitrages. Jito addressed this by introducing a 200ms “speed bump” (batches) and a mev-geth style bundle auction for batches, achieving an 80% share with their Jito validator client. This example indicates that that continuous preconfirmations are likely unsustainable due to spam and that batching and some auction for each batch are required. For more details, watch this informative talk by Zano Sherwani, co-founder of Jito, here.
Relay Burden
MR-MEV-Boost introduces additional burdens to the relays without incentives. Instead of managing a single round of MEV-Boost auctions, relayers must handle multiple rounds within a single slot, each within a limited timeframe. If the cost of operating a relayer increases too much, it may lead to further relayer centralization and builder-relay integration, or alternatively, no relayer may opt to support MR-MEV-Boost. Relayer incentives are a long-lasting problem in L1, and MR-MEV-Boost likely worsen this situation.
One way to mitigate the issue is to incorporate optimistic relay schemes to reduce the relayer’s operational costs. With this approach, relayers optimistically assume the honesty of the block-builder and skip the validation work for payloads sent from the builder. If the builder is later found to deviate from honest behavior, their collateral will be used to refund the proposer. Optimistic relaying would be especially helpful as it allows relayers to bypass the need to validate the based rollup transactions when verifying partial blocks.
Another potential solution is for the proposers to share the preconfirmation tip revenue with the relay to compensate for the additional workload.
Blob Efficiency
So far, we have blurred the line between L1 and L2 preconfirmations. This is somewhat intentional, as L2 transactions are included within L1 transactions. However, there are cases where the difference becomes important.
Consider a scenario where the L2 transactions within a round cannot fill an entire blob. If we only support preconfirmations for L2 transactions by preconfirming the L1 transactions that contain them, we face a problem. Proposers would either have to preconfirm partially filled blob transactions at the end of the round or wait for another round to collect enough transactions to fill the blob.
One solution is to allow proposers to commit to a batch of L2 transactions without linking them to a specific L1 transaction. This would let the builder of the final full block aggregate the L2 transactions into one or more L1 blobs at the end of the slot.
Issues with MEV-Boost
MR-MEV-Boost inherits the existing L1 MEV-Boost pipeline, which also means that we inherit many of MEV-Boost’s downsides, such as reliance on a handful of relays and builders. However, based rollups aim to inherit the security of L1, not to exceed it. Therefore, being “as bad as” L1 is the best we can do as a based solution.
Future Direction
MR-MEV-Boost can be generalized as partial-block preconfirmations, where the proposer incrementally builds the block by committing to and publishing partial blocks during their slot.
One future direction would be to enshrine partial-block preconfirmations into the L1 protocol to achieve faster block times. This aligns with Vitalik’s recent post and offers several benefits over off-protocol designs like MR-MEV-Boost:
- Removes “non-opted-in” proposers, enabling L1 preconfirmations and L1-L2 composability for all slots.
- Fully utilizes Ethereum’s validator set, potentially introducing lightweight PTC-like attestations for timely partial payload releases.
- Opens doors to increase the block times without degrading UX, which may help enable single-slot finality.
Related Work
In his latest post, Jon Charbonneau explains in great detail how based rollups/preconfirmations work and the centralization risk of based preconfirmations.
Furthermore, partial-block preconfirmations are closely related to inclusion list research, as both can be viewed under the broader concept of “partial-block building,” where different parts of a block are constructed at different times by different entities. For example, the MEV-Boost++ proposal from Kyodo (EigenLayer) resembles MR-MEV-Boost, as both enable early commitment to partial blocks by imposing additional slashing conditions on the proposer.
Conclusion
We introduce MR-MEV-Boost, a design that enables based preconfirmations by running multiple rounds of MEV-Boost auctions within a single slot. By inheriting the L1 PBS pipeline, MR-MEV-Boost mitigates many of the negative externalities of based preconfirmations while retaining the benefits of based rollups.
At Nethermind Switchboard, we actively research and tackle the open challenges of based preconfirmations. We are also collaborating closely with Taiko to develop a PoC for based preconfirmations compatible with L2 PBS, including MR-MEV-Boost. Stay tuned for more updates!