TLDR: We highlight a special subset of rollups we call “based” or “L1-sequenced”. The sequencing of such rollups—based sequencing—is maximally simple and inherits L1 liveness and decentralisation. Moreover, based rollups are particularly economically aligned with their base L1.
Definition
A rollup is said to be based, or L1-sequenced, when its sequencing is driven by the base L1. More concretely, a based rollup is one where the next L1 proposer may, in collaboration with L1 searchers and builders, permissionlessly include the next rollup block as part of the next L1 block.
Advantages
liveness: Based sequencing enjoys the same liveness guarantees as the L1. Notice that non-based rollups with escape hatches suffer degraded liveness:
weaker settlement guarantees: Transactions in the escape hatch have to wait a timeout period before guaranteed settlement.
censorship-based MEV: Rollups with escape hatches are liable to toxic MEV from short-term sequencer censorship during the timeout period.
network effects at risk: A mass exit triggered by a sequencer liveness failure (e.g. a 51% attack on a decentralised PoS sequencing mechanism) would disrupt rollup network effects. Notice that rollups, unlike the L1, cannot use social consensus to gracefully recover from sequencer liveness failures. Mass exists are a sword of Damocles in all known non-based rollup designs.
gas penalty: Transactions that settle through the escape hatch often incur a gas penalty for its users (e.g. because of suboptimal non-batched transaction data compression).
decentralisation: Based sequencing inherits the decentralisation of the L1 and naturally reuses L1 searcher-builder-proposer infrastructure. L1 searchers and block builders are incentivised to extract rollup MEV by including rollup blocks within their L1 bundles and L1 blocks. This then incentivises L1 proposers to include rollup blocks on the L1.
simplicity: Based sequencing is maximally simple; significantly simpler than even centralised sequencing. Based sequencing requires no sequencer signature verification, no escape hatch, and no external PoS consensus.
historical note: In January 2021 Vitalik described based sequencing as “total anarchy” that risks multiple rollup blocks submitted at the same time, causing wasted gas and effort. It is now understood that proposer-builder separation (PBS) allows for tightly regimented based sequencing, with at most one rollup block per L1 block and no wasted gas. Wasted zk-rollup proving effort is avoided when rollup block n+1 (or n+k for k >= 1) includes a SNARK proof for rollup block n.
cost: Based sequencing enjoys zero gas overhead—no need to even verify signatures from centralised or decentralised sequencers. The simplicity of based sequencing reduces development costs, shrinking time to market and collapsing the surface area for sequencing and escape hatch bugs. Based sequencing is also tokenless, avoiding the regulatory burden of token-based sequencing.
L1 economic alignment: MEV originating from based rollups naturally flows to the base L1. These flows strengthen L1 economic security and, in the case of MEV burn, improve the economic scarcity of the L1 native token. This tight economic alignment with the L1 may help based rollups build legitimacy. Importantly, notice that based rollups retain the option for revenue from L2 congestion fees (e.g. L2 base fees in the style of EIP-1559) despite sacrificing MEV income.
sovereignty: Based rollups retain the option for sovereignty despite delegating sequencing to the L1. A based rollup can have a governance token, can charge base fees, and can use proceeds of such base fees as it sees fit (e.g. to fund public goods à la Optimism).
Disadvantages
no MEV income: Based rollups forgo MEV to the L1, limiting their revenue to base fees. Counter-intuitively, this may increase overall income for based rollups. The reason is that the rollup landscape is plausibly winner-take-most and the winning rollup may leverage the improved security, decentralisation, simplicity, and alignment of based rollups to achieve dominance and ultimately maximise revenue.
constrained sequencing: Delegating sequencing to the L1 comes with reduced sequencing flexibility. This makes the provision of certain sequencing services harder, possibly impossible:
pre-confirmations: Fast pre-confirmations are trivial with centralised sequencing, and achievable with an external PoS consensus. Fast pre-confirmations with L1 sequencing is an open problem with promising research avenues including EigenLayer, inclusion lists, and builder bonds.
first come first served: Providing Arbitrum-style first come first served (FCFS) sequencing is unclear with L1 sequencing. EigenLayer may unlock an FCFS overlay to L1 sequencing.
Naming
The name “based rollup” derives from the close proximity with the base L1. We acknowledge the naming collision with the recently-announced Base chain from Coinbase, and argue this could be a happy coincidence. Indeed, Coinbase shared two design goals in their Base announcement:
tokenlessness: “We have no plans to issue a new network token.” (in bold)
decentralisation: “We […] plan to progressively decentralize the chain over time.”
Base can achieve tokenless decentralisation by becoming based.
no MEV income: Based rollups forgo MEV to the L1, limiting their revenue to base fees.
Based rollups who wish to capture their own MEV could plausibly enshrine an auction mechanism inside the L1 contract, e.g. a dutch auction that forces the batch submitter to pay some ETH to the contract.
Alternatively, there could be a mechanism where the last n batches (for a small n) can be cancelled and replaced by bribing the contract with a higher payout. Of course this would come with a tradeoff of longer finality for rollup transactions (since cancelled batches are essentially reorgs from the point of view of L2), as well as wasted gas for reorg’d batches submitted by sequencers who didn’t bid optimally (edit: on second thought this is also terrible because it breaks atomic composability between rollups who’s batches are submitted in the same block)
Unless you explicitly defined a based rollup as one that doesnt capture its own MEV, i think the design space is broad enough to allow them to have MEV income (of course with some tradeoffs, as is always the case!) - agree with your follow-up argument that it may end up being better for the rollup to leave their MEV to the underlying L1
Rollkit sovereign rollups have a similar concept called “pure fork-choice rule” rollups.
There is a resource-pricing / DOS vector that the rollup must solve on its execution layer, e.g if a bundle contains a while(true) loop and consumes max gas, the rollup should add a burn or something of that sort.
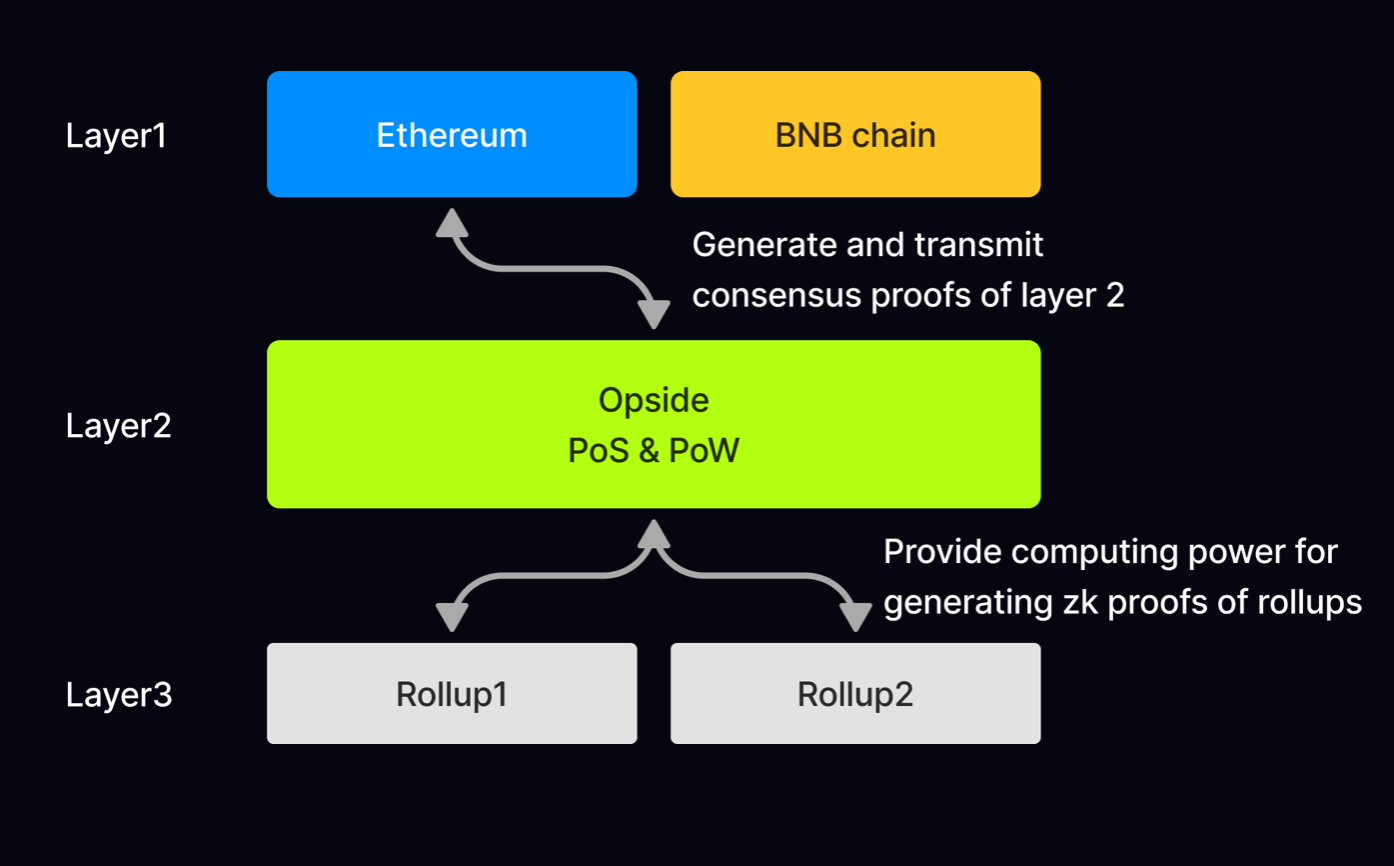
PoS: Opside will adopt the PoS of ETH 2.0 and make necessary improvements. As a result, Opside’s consensus layer will have over 100,000 validators. Anyone can stake IDE tokens to become a validator. In addition, Opside’s PoS is provable, and validators will periodically submit PoS proof to layer 1. Validators can earn from block rewards and gas fees in layer 2.
Layer 3
PoS (Sequencer): The validator proposes not only layer 2 blocks but also layer 3 blocks(i.e. data batch); that is, the validators are also the sequencers of the native rollups in layer 3. Sequencers can earn the gas fee from the transaction in layer 3 transactions.
PoW (Prover): Any validator can be the prover of a native rollup as long as it has enough computing power for zkp computation. Provers generate zk proofs for each native rollup in layer 3. A prover generates zk proof for each block of layer 3 submitted by sequencer according to the PoW rules. The first submission of zk proof will get the block reward of layer 3.
This is a really interesting idea. One question here is where do L2 clients send transactions to, so that searchers / builders can then make up L2 blobs? Are they sent to the L1 mempool, with some special metadata that “informed” searchers can interpret? Is this going to significantly increase load on the L1 mempool (if L2 transaction load is going to be 100x L1 transaction load)? Another possible approach is to let these L2 transactions live in new p2p mempools (one for each L2) that “informed” searchers can then fish them out of.
This is super cool as a concept. Thanks for sharing.
I do have a question though.
You mentioned L1 searchers and builders will collaboratively include the rollup block with the next L1 proposer. Does that mean they will be also in charge of sequencing and compression of the sequenced transactions, which then get included in the next L1 block? Mainly curious about how the block compression happens without introducing additional roles. Because without the proper compression, L2 will not achieve further scalability in throughput and gas-saving, which is what they are built for.
Fun fact: I actually thought this is how all rollups work until about a year ago I guess because it’s a quite inutitive solution.
I have a question about the “anarchy” part. You said that wasted computation can be avoided by the based sequencing but this is not obvious to me. Even in PBS, wouldn’t you have many builders compete to mine the next L1 block, and hence all repeat the effort of making the next L2 block as well?
I’m thinking specifically, all of them would do the compression work, and all of them would have to compute the validity proofs. (Am I missing any other work?) You said that the latter can be avoided if the L1 builder can validity-prove the previous block, but how does that change anything? Then the competition for proving block n would simply go to block n+1, it wouldn’t disappear.
We discussed a solution for this (multiple concurrent block proposers) in a previous post. Tldr you can have an additional validity condition for a block to be valid: requiring signed payloads with additional txs from >2/3 of the other validators for the block to be accepted. @sreeramkannan also made a post about it the other day with a good summary on how this could help based rollup sequencing.
Imho that’s not a big deal, it’s the same as builders/searchers today doing overlapping work. The bigger issue would arise if there was complete anarchy in what actually ends up on chain, e.g. if you have a “naive” proposer (not connected to some builder network) and if these L2 bundles are all sent over the L1 mempool as normal txs, because it would lead to wasted gas and wasted blockspace.
One approach to remove this redundancy in proof computation could be to reinstate the “centralized sequencing + open inbox” model, but for validity proof submission (instead of actual sequencing). Basically, there’s a centralized, whitelisted prover (or even better, the role is auctioned periodically), which is the only one allowed to submit proofs for some time (e.g. it is the only one which can submit a proof for a sequence of batches which was fully included by block n before block n + k), but after that time anyone can submit, ensuring liveness. The reason why this is better than the same model for sequencing is that there’s nothing bad which the whitelisted prover can do with their own power, other than delaying the on-chain finality of some L2 batches. Perhaps one could even allow anyone to force through a proof, they just wouldn’t get compensated for it?
Awesome post @JustinDrake! Really great summary of the pros and cons of based vs non-based sequencing for rollups. Also love the term “based”, I have just been calling this native vs non-native sequencing, and native is an overloaded term .
One question on the social consensus point quoted above – what precisely is the issue that you are referring to? For example, if a non-based sequencing solution is implemented with an external consensus protocol whose stake table (i.e., participation set) is managed in an L1 contract, why wouldn’t you say that social consensus among the L1 nodes could be used to recover from failures?
Or at least to the same extent that it can be used to recover from failures with based sequencing? (I am not sure to what extent we can rely on social consensus in the first place, as it is somewhat of a magic hammer to circumvent impossibilities in consensus, recovering liveness despite the conditions that made it impossible in the given model, whether due to the network or corruption thresholds exceeded).
Is the assumption that L1 validators do not have the incentive to do any form of social recovery for non-based sequencing because they aren’t running it and aren’t deriving sufficient benefit from it? Would you say this changes with re-staking that protocols like Eigenlayer are enabling? Because with re-staking the L1 validators do have the option to participate and get more exposure to the value generated by the rollup? If so, would you say this still remains true when some form of dual-staking is used, that allows both for participation of Ethereum nodes (L1 stakers) and other nodes that are directly staking (some other token) for the non-based sequencing protocol? If not, then where would you say the threshold is crossed, going from pure based sequencing, to sequencing exclusively run by L1 re-stakers, to some hybrid dual-staking, that makes social consensus no-longer viable?
Disc-V5 supports topics and is used on both CL and EL, so we could create separate p2p channels at any granularity we want (e.g. “shared_sequenced_chain1_chain2_slot5”, see e.g. how EIP-4844 blobs are each on separate topics.
I’m going to take the opposite view here and say that the advantages of based rollups are exaggerated. I’ll go one by one:
liveness: If there’s a liveness failure, rollups can recover by having a new set of sequencers (or even just one) be chosen on L1. There’s no reason to stop the chain and force people to do a mass exit. We can always find new people to continue building blocks.
decentralisation: We can still use the L1 searcher-builder-proposer infrastructure to include rollup blocks on L1. We create the L2 blocks using L2 sequencers and then allow anyone to submit it to L1 (in exchange for a small reward of course). L1 builders will take that MEV opportunity and include the L2 blocks in their L1 blocks.
simplicity: True, it’s indeed simpler.
cost: True, but verifying signatures is not that expensive. And can be done optimistically, resulting in very low overhead. Regarding tokens, they are a regulatory burden, but are necessary to fund development.
L1 economic alignment: Indeed, MEV would flow to L1. But that’s more of an advantage to L1, not really to the rollup.
sovereignty: Evidently, non-based rollups can do all of this too. And more.
Regarding the disadvantages, latency is a big one. With L2 sequencers you can have L2 block finality in 1s which, while much weaker than L1 block finality for sure, still provides a decent guarantee for most use cases. And as soon as a valid L2 block is included in L1, it’s is in effect final. There’s no way that that L2 block will be reverted. The proof can be submitted later, it doesn’t matter.
But with based rollups, we always need to wait for the L2 block to be proved. Each block will include the SNARK proof for the previous block, so no new block can be created until the proof is generated. With the current technology that takes several minutes. Until that, there’s no guarantee that a user transaction will complete.
So, based rollups are indeed simpler and send their MEV to L1, but have much higher latency.
But with based rollups, we always need to wait for the L2 block to be proved .
Why? Isn’t the definition of finalized that the transaction cannot be reverted? When you post a rollup block on-chain, you cannot revert it since you can’t make an invalid proof of the rollup block.
It has to do with if you allow several block proposals (by this I mean L2 blocks that are included in L1 but not proven yet) at the same height or if you lock the contract.
Assume that you allow people to keep sending block proposals until one of them is proven. In that case, you clearly cannot be sure whether a particular block proposal will be finalized because you might have several valid block proposals and any of them could get proven.
So, that doesn’t work. The other option is to “lock” the contract. When someone sends a block proposal, you optimistically assume that it’s correct and don’t accept any other block proposals at that height. You cannot prove that a given block is invalid, so you need to have a timeout. If the block proposal doesn’t get proven within that timeout, then you revert the block proposal and let other people propose a block for that height.
This is where the problems start. You cannot let anyone send block proposals, otherwise a malicious actor can just continuously send invalid block proposals. That’s a liveness risk. You can try to fix it by having smaller timeouts, but then a valid block proposal might get reverted if it doesn’t get proven in time. So, you need a timeout that is long enough and you need some type of bond for the block proposals (that you can slash if the block is invalid).
At this point we are starting to deviate from a based rollup. The other problem is that the value of the bond needs to be well-priced. If it’s too low you open yourself to liveness attacks again, if it’s too high no one will send block proposals (there’s a capital cost to having ETH locked, sending block proposals needs to be competitive with other activities like staking or LPing). The natural solution is to let the market decide, so you decide on some number of available slots to be a block proposer and auction them off.
Now we are way off the original based rollup design, this is almost PoS. It’s certainly not as simple as a based rollup. It’s in fact similar to another rollup design where we auction slots to be block proposer, and then let them propose blocks round robin. The only difference really is that in our based rollup variant every block proposer competes to send the next block proposal, which will make the MEV flow to L1. While if we let the proposers go round robin the MEV stays in L2. Evidently rollups are going to prefer to keep the MEV since that means higher rewards for the block proposers which means higher bonds/stakes which means higher security. So we end up with L2 sequencing.
And all of this only gets you to a 12s latency. With full blown PoS you can get down to 1s.
 I guess because it’s a quite inutitive solution.
I guess because it’s a quite inutitive solution.