
Co-authored by Lin Oshitani & Conor McMenamin, both Nethermind. Thanks to Patrick McCorry, Chris Buckland, Swapnil Raj, Ahmad Bitar, and Denisa Diaconescu for their feedback. Feedback is not necessarily an endorsement. This is the first part of a two-part series on embedded rollups.
Series Summary
- In this post, we’ll explore the core concepts of embedded rollups and demonstrate a simple key-value store example, which can be applied to services like ENS and Keystore.
- In the next post, we’ll explore an exciting use case that enables fast and efficient cross-chain interoperability by implementing an embedded shared-bridge rollup.
Introduction
Rollups publish data to L1 but execute on L2. This gives them state that is independent from L1 and other L2s. While this independence is the key to their scalability, it also means that L2s only share state through L1, which is expensive to write to and execute on. This limitation makes features like cross-L2 interoperability challenging.
We introduce embedded rollups (ERs)—rollups that are embedded within and shared among other rollups. When embedding an ER, the rollup stores and updates the ER’s state alongside its own, which gives the rollup a local read-only view of the ER’s state during execution. If multiple rollups embed the same ER, they can share this read-only state without relying on the L1 state or execution. This cross-rollup read-only shared state can be utilized for use cases such as shared key-value stores, including ENS and keystores, and a shared bridge layer.
Primer: Conventional Rollups
To explore how rollups can embed another rollup, let’s first review how rollups currently update their state. Consider rollup A. Rollup A progresses its state using the following protocol:
- Synchronize its local L1 node.
- Retrieve rollup A transactions from rollup A inboxes on L1, along with their accompanying calldata or blobs.
- Rollup A may additionally read preconfirmed txs from the rollup A sequencer.
- Update rollup A's state by executing these transactions.
Core Protocol Description
When Rollup A embeds another rollup ER (for embedded rollup), it maintains a local view of the ER's state alongside its own - effectively embedding the ER's state within itself. For example, this local view could be implemented through a special contract in rollup A that stores ER's state root. As we describe in the Execution section, there are other ways to achieve this embedding.
In this post, we’ll sometimes refer to rollup A —the rollup embedding an ER —as the embedding rollup.
Rollup A then updates both its local view of the ER and its own state as follows:
- Synchronize its local L1 node.
- Retrieve rollup A and rollup ER transactions from rollup A and rollup ER inboxes on L1, along with their accompanying calldata or blobs.
- Rollup A may additionally read preconfirmed txs from the rollup A sequencer and/or rollup ER sequencer.
- Update their local view of ER by executing the ER transactions.
- Update rollup A's state by executing the A transactions.
- These transactions may read from the local view of ER.
Additionally, any other rollup—call it rollup B —can embed the same ER. By doing so, the state of ER serves as a read-only shared state between rollups A and B. Such a read-only shared state enables a range of use cases, which we will explore in the following section and future posts.
Note that ER's execution does not depend on A's execution; ER's state transition function is unaware that A exists. Contrarily, A's state transition function depends on ER's state to update A's local view of ER, and conduct reads against it. This dependency of A on ER is discussed in the later Layer-by-Layer Considerations section.
Example: Key-Value Stores (KVS)
One of the most straightforward applications of embedded rollups is to provide a cross-rollup shared key-value store (KVS).
Take ENS as an example, which recently announced its pivot to becoming a standalone L2. Embedding the ENS rollup would allow any rollup to maintain an up-to-date copy of ENS domain names without waiting for ENS to settle state roots on L1 or relying on oracle-based message-passing solutions.
Similarly, Keystore rollups (e.g., Keyspace by Base), which map smart contract accounts to their associated keys, are also well-suited for embedding.
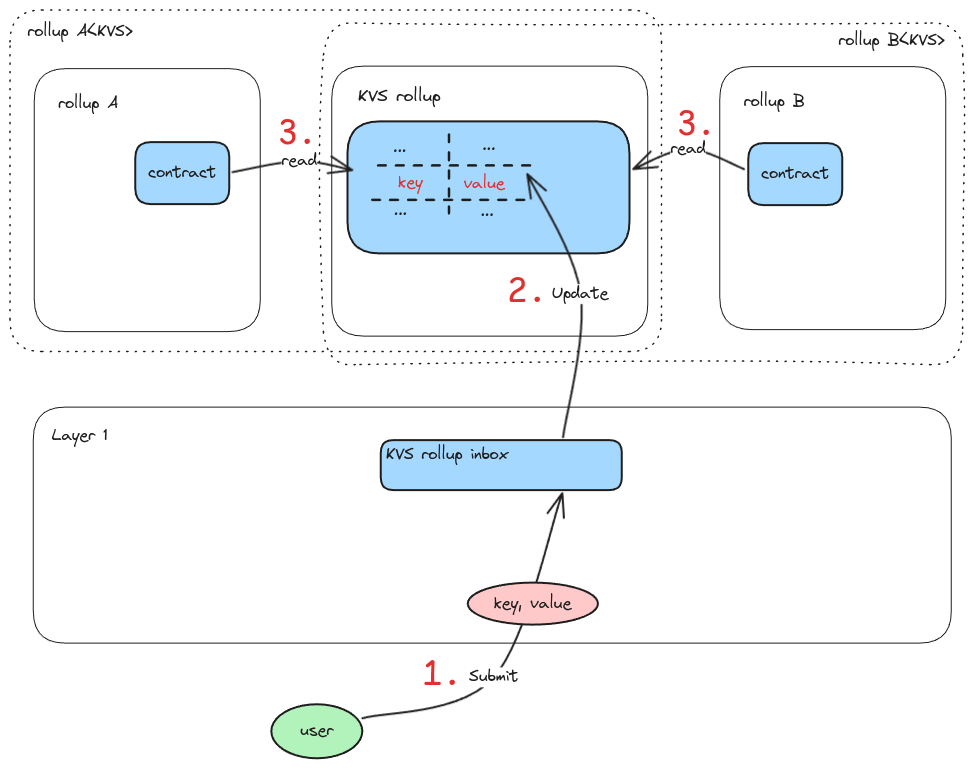
The shared key-value store use case operates as follows:
Suppose rollup A and rollup B want to share a KVS. This can be achieved by introducing a shared \mathit{KVS} rollup embedded in both rollups, then:
- Users submit key-value updates to the \mathit{KVS} rollup’s inbox on L1. Updates can be batched to minimize gas costs.
- Rollups A and B retrieve the updates from the \mathit{KVS} rollup’s inbox on L1 and update their local view of the \mathit{KVS} rollup accordingly.
- Rollups A and B can now read from the updated local view of the shared \mathit{KVS} rollup. They should both see the same updated \mathit{KVS} since they execute the \mathit{KVS} rollup with the same inputs.
Below is a diagram that illustrates this use case:
Example: Shared Bridge Rollup
We can implement a shared bridge rollup to track token balances across rollups and consolidate solver liquidity. This shared bridge can be embedded into any rollup that agrees to participate. This rollup enables L2→L2 transfers without requiring costly L1 transactions. Additionally, it supports fast and efficient solver-based transfers by concentrating solver liquidity within a single shared bridge layer.
Details of this shared bridge rollup design will be explored in the next post in this series here: Embedded Rollups, Part 2: Shared Bridging
Layer-by-Layer Considerations
This section explores how ERs integrate and interact with the modular stack’s layers—data availability, sequencing, execution, and settlement. While much remains similar to traditional rollup designs, we focus on the unique considerations that arise when one rollup embeds another.
Data Availability and Sequencing
When rollup A embeds ER, it can read ER ’s input from three possible sources:
- Finalized L1 blocks: Read from ER inbox contract in finalized L1 blocks.
- Non-finalized L1 blocks: Read from the ER inbox contract in non-finalized L1 blocks.
- Preconfirmations: Read from preconfirmed ER txs provided by the ER sequencer.
Reading from finalized L1 blocks introduces latency between the posting of ER inputs and their incorporation into rollup A.
Reading from non-finalized L1 blocks or using preconfirmations can reduce this latency, potentially to sub-second levels, depending on the preconfirmation protocol. However, this introduces the risk of reorgs, where an ER input batch is reorged (either via L1 reorgs or preconfer equivocation), but the dependent rollup A batch is not.
To mitigate such reorg risk, we can implement batch conditioning, where rollup A batches specify the ER rollup batch (via hash or some ID) they depend on. This can ensure that the L2 execution will reorg rollup A's batch if its dependent ER batches are reorged.
Having a shared sequencer for rollup A, rollup ER, and/or L1 provides another layer of protection against reorg risks, as shared sequencers can ensure the atomicity of batches.
Furthermore, since censorship resistance of embedded rollups is important to be accepted as a credible natural shared layer, they are a good fit to be “based.”
Execution
ERs can either have a custom execution environment tailored to a specific use case or use a general-purpose VM like the EVM. A custom environment can optimize performance, enabling faster proving and settlement on L1. However, using a widely adopted VM like the EVM makes embedding much easier. For example, if the embedding rollup already supports the EVM, it can reuse its existing execution environment to embed an EVM-based ER.
To further simplify embedding, an ER can be implemented as a restricted EVM execution that allows only a limited set of specific contracts to be deployed. The embedding rollup can then map the entire ER state to special contracts within its own state and restrict all inputs to these contracts to come through the ER inbox. This approach enables embedding with minimal changes to the embedding rollup’s execution environment. For example, this approach should work for the KVS example introduced in this post.
Settlement
When rollup A and B embeds ER, the execution result of rollup A and B will now depend on the execution result of ER. As a result, when you settle rollup A and B's state root, the settled state root will depend on the state root of rollup ER. This dependency can be handled in two ways:
- Contingent settlement: Rollups A and B make their settlement dependent on (“contingent” on) the settlement of ER. Specifically, rollup A's settlement will reference the ER state root on which it depends. Rollup A's settlement is invalidated if the settled ER state root does not match the referenced state root.
- Pros: Ensures that rollup A, rollup B, and the L1 all maintain a consistent view of the ER rollup state.
- Cons: The settlement contracts for rollups A and B are required to account for this dependency, which both introduces a liveness dependency on rollup ER's settlement and increases the complexity of the settlement logic.
- Sovereign settlement: Rollups A and B do not depend on rollup ER's settlement and instead independently settle the state of their local view of rollup ER within their settlement.
- Pros: Preserves rollups A and B's independence (sovereignty), as their settlement logic remains self-contained without relying on external settlement.
- Cons: Potentially leads to inconsistent views of the ER rollup state among rollups A, B, and L1 (if the ER rollup has a native bridge to L1). That being said, such inconsistencies remain contained; an inconsistent view of the ER rollup in one rollup does not impact the execution of other rollups, as both rollups settle independently.
For the simple KVS use cases, we expect sovereign settlement would work. Furthermore, such KVS rollups may choose not to settle to L1 itself (= be a sovereign rollup). If any rollup that does not embed the KVS rollup wishes to read the KVS state, it can do so through the settled state root of a rollup that does embed the KVS rollup. In this sense, the KVS rollup can “free-ride” when the embedding rollup is settled.
Conclusion
In this post, we introduced the core concept of embedded rollups and presented a simple key-value store use case. In the next post Embedded Rollups, Part 2: Shared Bridging we will explore how embedded rollups can be used to implement a shared bridge layer to enable fast and cheap L2<>L2 interoperability.
Appendinx: ERs From the Lens of the STF
In this section, we’ll provide a slightly more “formal” description of embedded rollups.
At the heart of every blockchain is the STF. This function defines how the blockchain updates its state. For example, in Ethereum L1, the STF takes the current state S_{L1} and inputs I_{L1} (which are determined through L1 consensus) to compute the next state S_{L1}':
Rollups are blockchains that outsource consensus and data availability to the L1, i.e., Rollups derive their inputs from L1. Consider rollup A, for example. It obtains its input by applying a derivation function to the L1 state and inputs:
Here, the derivation function takes not just S_{L1} but also I_{L1}, as L2 transactions are typically not stored in state and only present in calldata/blobs inside the input.
Then, rollups progress their state using their STF:
Note that the state of rollup A is calculated and maintained independently from the L1 state. This is the key to how rollups enable scalability, as no L1 computation nor state is used.
Typically, {deriveInput}_A reads inputs from the rollup A ’s inbox contract in L1. However, nothing prevents rollup A from reading other contracts on L1, including inboxes of other rollups. This is a core insight towards implementing embedded rollups.
Now, imagine there is another rollup, which we call ER (for embedded rollup). If rollup A decides to embed ER, it yields a new rollup that we’ll refer to as rollup A \left< ER \right>. This rollup will derive inputs for both A and ER from L1:
Furthermore, the state of rollup A will embed the state of rollup ER, denoted as S_A\left<S_{ER}\right>. In other words, rollup A maintains a local view of ER within A ’s state. For example, this could be implemented through a special contract in rollup A that stores ER's state root. As we described in the Execution section, there are other ways to achieve this embedding.
The STF of rollup A \left< ER \right> functions as follows:
In lines 1 to 3, the STF of A \left< ER \right> progresses the local view of ER using the STF of ER.
In lines 3 to 4, the STF of A\left<ER\right> is used to calculate the next state of A. The STF execution here should be mostly the same as {STF}_A, with some minor modifications for the handling of the local view of ER.
Finally, another rollup—let’s call it rollup B —can also embed the same ER and yield rollup B\left<ER\right>. As long as A\left<ER\right> and B\left<ER\right> share the same L1, genesis ER block, and {STF}_{ER}, A and B ’s local view of ER will be the same. Hence, the state of ER serves as a read-only shared state between rollups A and B. This read-only shared state enables a range of use cases, which we will explore in this post and will explore in the following posts.
If you are interested in topics like this and want to be at the cutting edge of protocol research on Ethereum, we’re hiring. Apply through the website, or reach out to one of the co-authors (Conor or Lin) through Twitter. Let’s keep Ethereum great together.