The attached is our latest study on blockchain sharding, namely, Boson consensus, which could
Effectively counter single-shard attack by employing a root-chain-first fork choice rule. All blocks from shard chains are protected by the root chain, which has a high-security guarantee.
A node operator is free to run any types of the node including full node, root node or shard node. And with cluster design, a node can be easily scaled to multiple machines and support tens of thousands of TPS verified by community members.
Each shard chain could run any consensus (PoW, PoS, dPoS) and secured by the root chain.
Efficient and secure in-shard and cross-shard transactions.
If you are interested in the blockchain sharding design, please share your feedback and/or comments! Thanks.
The complexity and bandwidth requirement for cross-shards communication cannot be ignore in practicing. And liveness and finalization should also be considered, what would happen if a piece of cross-shards transaction lost but indicated in root chain?
Let me clarify the question a bit more: “cross-shard transaction lost” means that the destination shard cannot find the output of the cross-shard transaction from the source shard, where the output may be called “receipt” or “deposit” (or more general, cross-shard transaction message) in different languages.
If cross-shard transaction is lost, it means the nodes of the destination shard cannot access the block data of the source shard. In our current design, we suggest
All nodes running a full node (as defined in Secion III-D of the Boson paper) and thus unless all nodes are down, any node can access source shard data. The network will probably start like this when the shard numbers are small. Note that such node can be implemented as a cluster so that the node itself can scale horizontally;
A node may just run a partial node that only runs part of shards, which do not include the source shard. To access the cross-shard tx, this node will be a light-client of the source shard.
You can write “Root” to beacon/root chain and send cross-shard transactions directly to another shard(yellow and orange blocks), for example shard X.
On creating new block, Block Proposer of shard X should verify cross-shard transactions via Root of beacon/root chain. What would happen if cross-shard transactions are not received on this time?
The main problem is how to guarantee that cross-shard transactions always arrives before corresponding beacon chain’s block in network layer?
We are assuming cross-shard transactions were possible and with high efficiency, but group-casting on DHT network is very different, and there are no group-2-group algorithm on DHT network yet. I thought you should discuss them in order to make your algorithm viable.
The most problem is network complexity in practical, which is just my point for discussing.
Some considerations: When you have very hight TPS, limited by network bandwidth, full nodes running all shards will be impossible. If we choose nodes with high network bandwidth as full nodes, depending on these nodes would make our system more centralized.
“A cross-shard receipt will be incentivized to be eventually processed at destination shard.” shard-to-shard communication should be described and discussed to prove that your scheme can be practical.
Right now the network is more sensitive to latency rather than bandwidth - the longer the latency that a block propagates to the network, the network will experience a higher block stale rate.
However, my understanding is that the network bandwidth of a node is actually underutilized - the P2P bandwidth is only used when broadcasting a tx or a block, where the time of broadcasting a block is random, and the resulting traffic is sporadic.
Consider a full node that runs all shards and maintains 10,000 TPS and the bandwidth is fully utilized, the expected bandwidth required (with 30 connected peers) will be
which I think it is acceptable if running a machine in a cloud with more than 1Gbps or even 10Gbps bandwidth.
Besides bandwidth, other facts of limiting scalability can be storage and processing power, where our solution is to run a full node as a cluster that processes/stores part of the ledger thanks to sharding. Currently, our code already supports that and our community member can easily produce 100,000 TPS in a test environment (3 full nodes).
In fact, when discussing scalability, Satoshi already provisioned a similar way to address the problem, where I quote here
Satoshi Nakamoto Sun, 02 Nov 2008 17:56:27 -0800: Long before the network gets anywhere near as large as that, it would be safe for users to use Simplified Payment Verification (section 8) to check for double spending, which only requires having the chain of block headers, or about 12KB per day. Only people trying to create new coins would need to run network nodes. At first, most users would run network nodes, but as the network grows beyond a certain point, it would be left more and more to specialists with server farms of specialized hardware. A server farm would only need to have one node on the network and the rest of the LAN connects with that one node.
Satoshi Nakamoto July 14, 2010, 09:10:52 PM: I anticipate there will never be more than 100K nodes, probably less. It will reach an equilibrium where it’s not worth it for more nodes to join in. The rest will be lightweight clients, which could be millions.
At equilibrium size, many nodes will be server farms with one or two network nodes that feed the rest of the farm over a LAN.
Satoshi Nakamoto July 29, 2010, 02:00:38 AM: The current system where every user is a network node is not the intended configuration for large scale. That would be like every Usenet user runs their own NNTP server. The design supports letting users just be users. The more burden it is to run a node, the fewer nodes there will be. Those few nodes will be big server farms. The rest will be client nodes that only do transactions and don’t generate.
where “server farms” == “cluster” in our design.
Note that even the cost of running a fullnode can be higher, the node-running cost vs solo-mining cost is still significantly smaller, where we have the calculation as follows:
The BP of the destination shard may not include the root block that contains the cross-shard transaction receipt if it doesn’t observe the root block or the cross-shard transaction receipts are not ready (e.g. downloaded from the source shard):
As a result, even the root chain/beacon arrives to a BP before the cross-shard transactions receipts, the BP could choose not to process the cross-shard transactions receipts at the cost of losing cross-shard tx fee or full block reward:
Emm, every thing sounds OK. But since you have assumed full nodes which should receive all messages of all shards, why not make them as root chain nodes to avoid cross-shard communication? What is the reason to move bandwidth requirement from root chain to special full nodes?
My understanding of your suggestion is to have a new root chain to include all shard-blocks-to-be-produced (and thus asynchronous cross-shard communication is eliminated)?
I think this means to remove the consensus of each shard (e.g., PoS/PoW), and thus the blocks of all shards are produced at the same time as a root block, and it is essentially an improved version of large block solution as BCH/BSV proposing. In addition, compared to BCH/BSV, since the ledger is sharded by design, and if the node is can be implemented as a cluster (server farms following Satoshi’s term), we could address storage and processing power scalability easily (where I believe BSV/BCH are suffering once the block size approaches their limits). Note that the existing Boson Consensus code (from QuarkChain) can easily support that, meanwhile, I cannot find a “server farm” implementation of Bitcoin at the moment, i.e., even we run the Boson consensus in a degenerated way as you suggest, we achieved what Satoshi proposed 10 years ago for scalability from a different path.
This will be a good starting point of Boson consensus that running as an advanced version of BCH/BSV, however, as I mentioned before, the network right now is more sensitive to latency, and dramatically increasing the block size (10x or 100x) will create longer network propagation time and thus the block stale rate can be extremely high. Introducing consensus of each shard chain can greatly improve that: the shard blocks are produced asynchronously before a root block is produced, and the root block size can be much smaller.
Back to single-chain viewpoint perspective, Boson consensus is a systematic-way allowing pre-broadcasting of the block body (which contains most of block data) before a block is produced. Assuming most of the nodes already received the body, a BP can broadcast a compacted version of the block by replacing the body with its hash. This will dramatically reduce the propagation time of the block. However, the major issue is how to prevent spamming the block bodies since every node may broadcast the body, and a malicious node can spam the network with artificial bodies.
Boson consensus provides a systematic solution to the spamming problem of pre-broadcasting - a body or more officially, a shard block can be broadcasted as long as it satisfies the shard consensus. The root block (which has much greater production cost) that confirms all the transactions can be much smaller.
Moreover, the plus of Boson consensus is that it could encourage decentralization on BPs: e.g., a miner with less hashpower could solely mine a shard block with much lower difficulty rather than a root block with higher difficulty, where I explained in my previous post that cost of mining solely may be more concerning compared to the cost of running a node.
Your key improvement of this consensus is that block size can be reduced to o(nlog2n), this requirement would heavily reduce your value. In the other way, What would happen if some mine pool focused all hash power to attack one shard and made chain of the shard rollback? Should all other shard rollback?
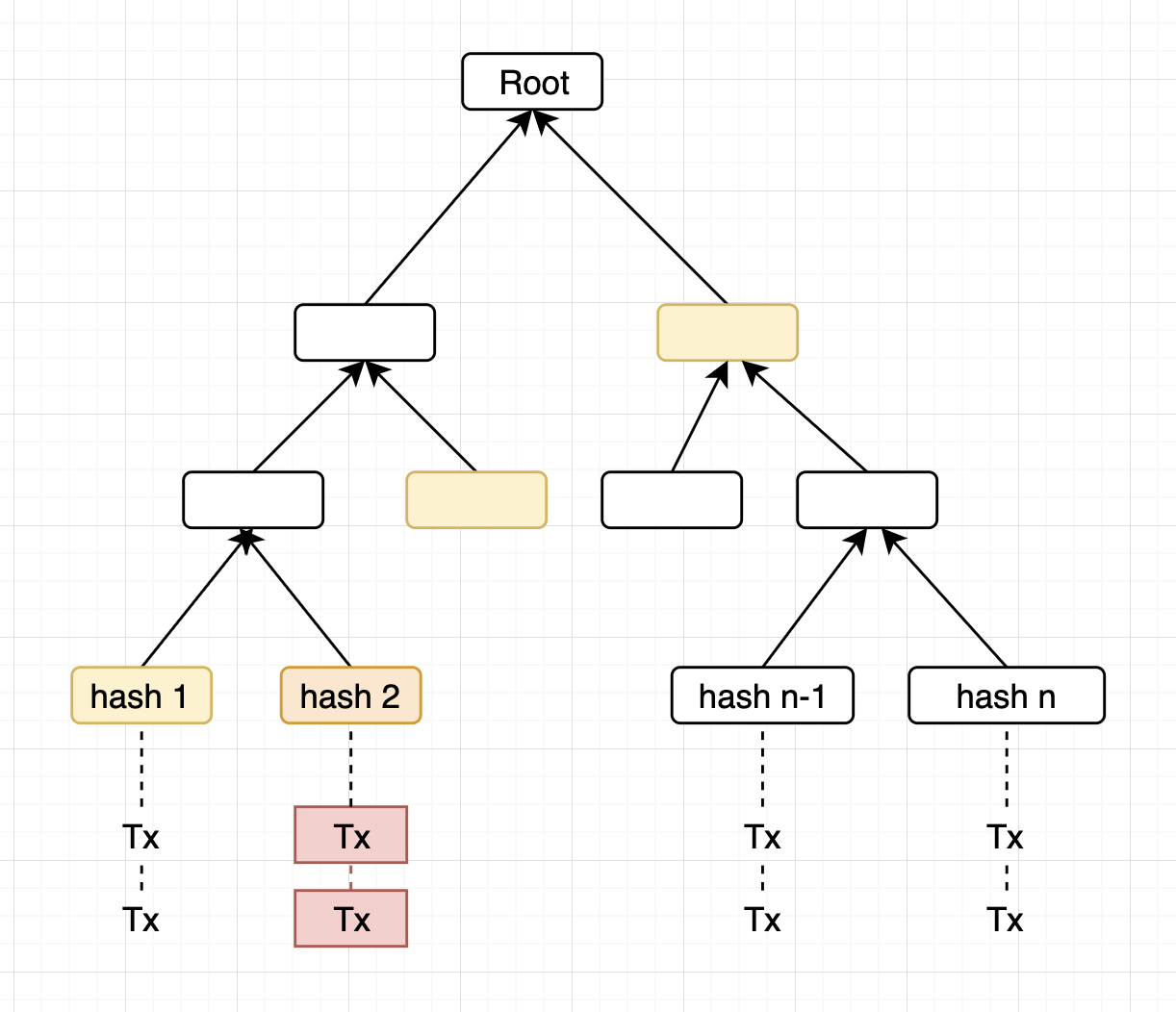
Nice question! First of all, what is the definition of n here? For the size of root block, in Boson Consensus, the root block only needs to include the hash of the latest shard chain tip of all the shards the root block observed, which means that in theory, suppose there are 1024 shards, the block size of root block can reduce to \approx 32 \times 1024 = 32K.
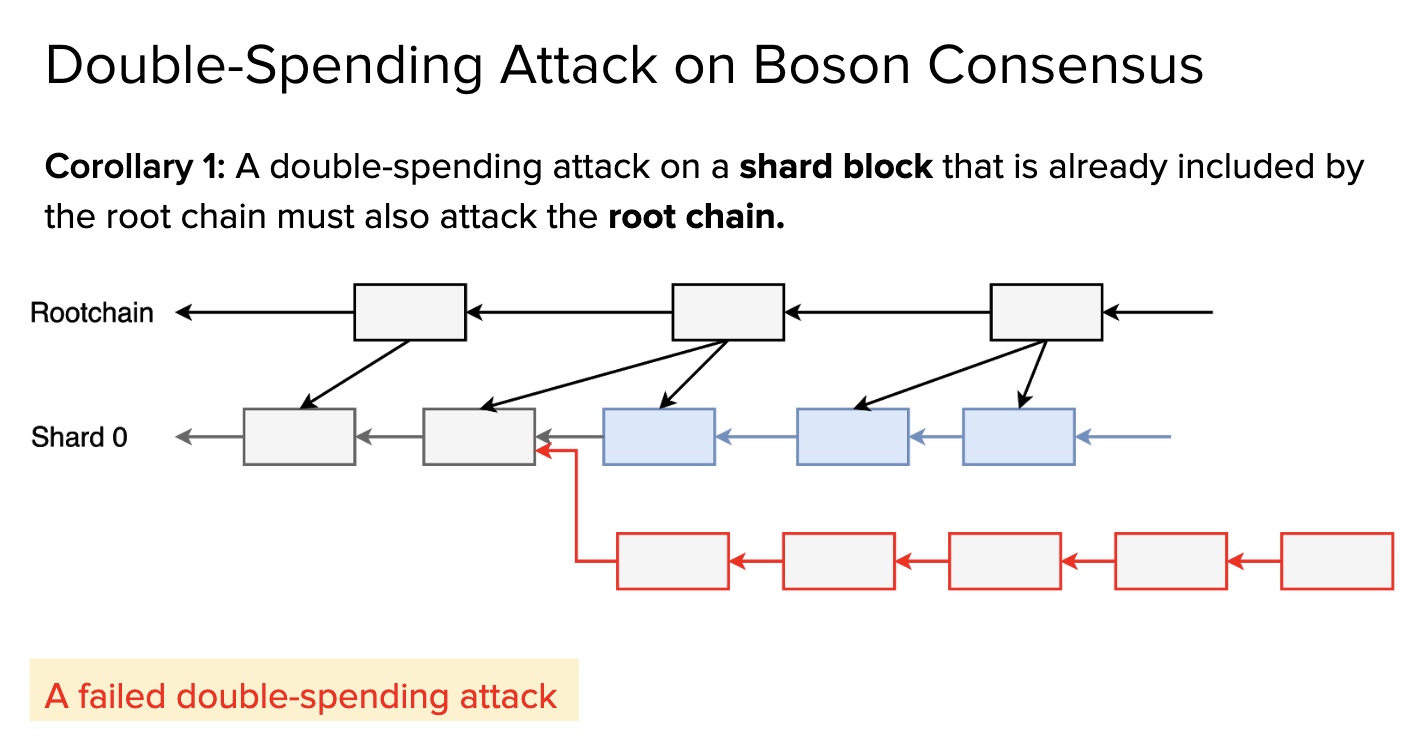
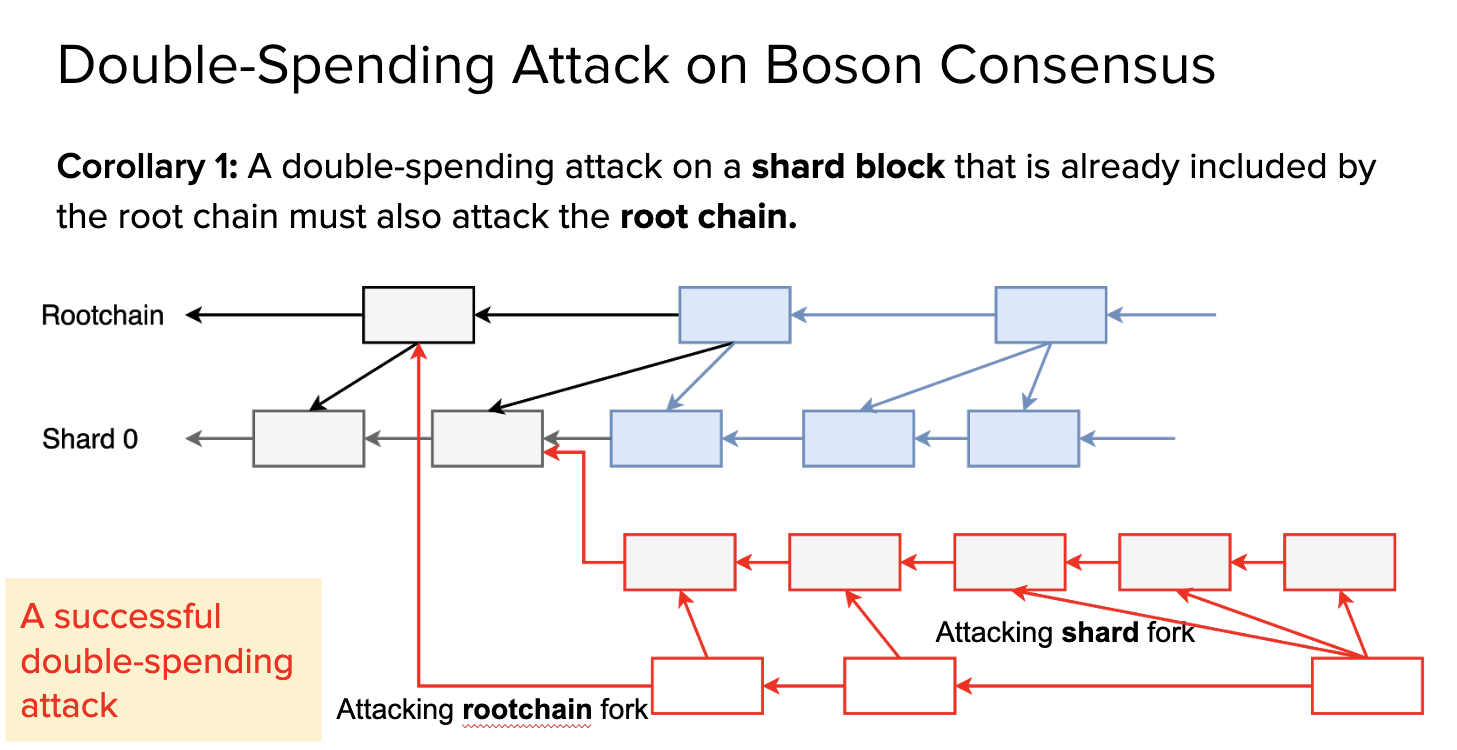
For single-shard attack, Boson consensus provides a way to address the issue by shared security: If a shard block included by root blocks, reverting the shard block must also revert the corresponding root blocks (Proposition 2 in Section III.B Double-Spending Attack has a strict proof). Here are some examples: