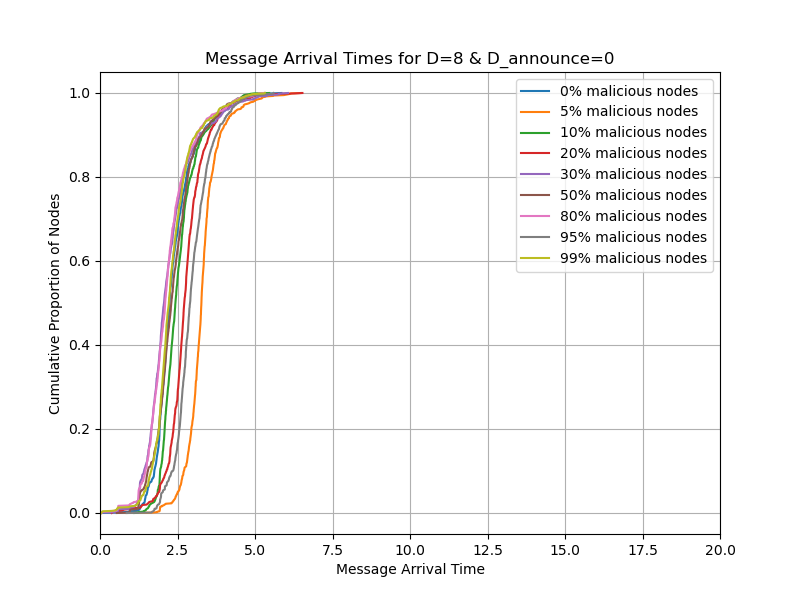
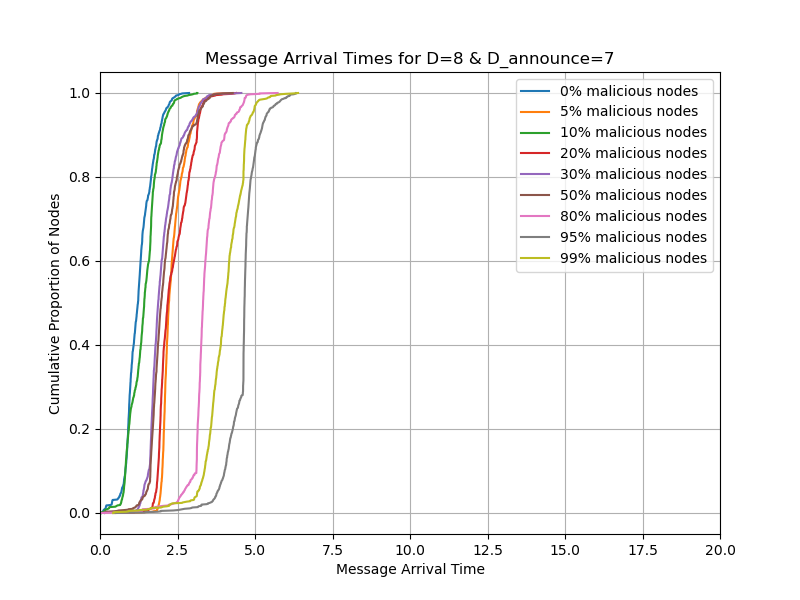
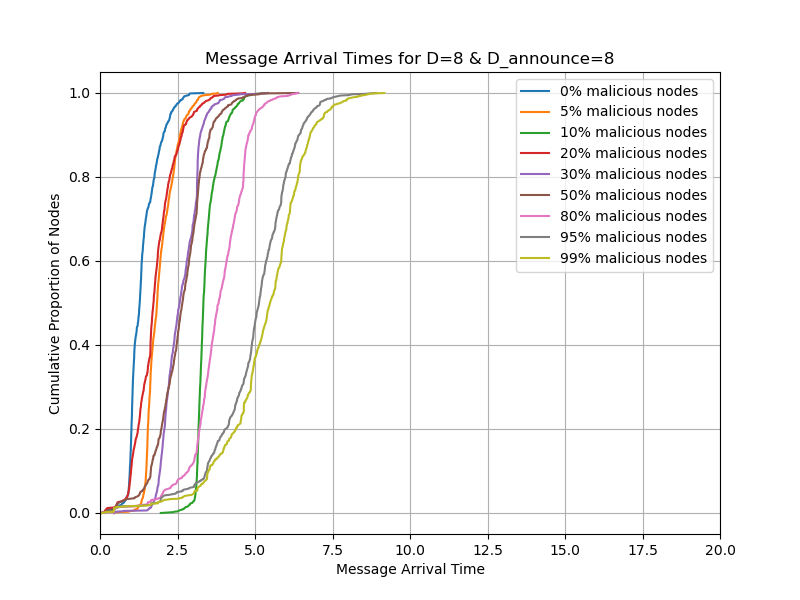
tldr; with gossipsub v2.0, we can double the blob count from whatever is specified in Pectra
Gossipsub v2.0 spec: here
Introduction
Gossipsub is a pubsub protocol over lib2p which is based on randomized topic meshes. The general message propagation strategy is to broadcast any message to a subset of its peers. This subset is referred to as the ‘mesh’. By controlling the outbound degree of each peer you are also able to control the amplification factor in the network.
By selecting a high enough degree you can achieve a robust network with minimum latency. This allows messages to be dispersed resiliently across a network in a short amount of time.
The mesh that is selected is random and is constantly maintained via gossip control messages to ensure that the quality of peers stays consistent and doesn’t deteriorate. Gossip Metadata is emitted during every heartbeat to allow peers who might have missed certain messages due to downstream message loss to be able to recover and retrieve them.
Each peer has a memory of all seen messages in the network over a period of time. This allows nodes to drop duplicates and prevents them from being further disseminated.Also having memory of messages which were propagated allows peers to make scoring decisions on their mesh peers. This allows them to prune lousy peers from the mesh and graft new ones in.
Problem With Gossipsub Today
As demonstrated above gossipsub has some very desirable characteristics as a pubsub protocol. However, while you have a resilient network with minimal latency (assuming a high enough degree), Gossipsub as of its current design brings about a high level of amplification.
The tradeoff of the current design is if a network requires messages to be propagated with minimal latency it requires a large amount of amplification. This is problematic in networks which need to propagate large messages, as the amplification done is significant. If many of these large messages start being propagated in a network it would affect the general decentralization and scalability of the network.
For networks such as those Gossipsub v1.2 introduced a new control message called IDONTWANT. This control message allows a peer to tell its mesh peers not to propagate a message matching a particular message ID. The main goal of this is to prevent duplicates from being sent and reduce amplification in the network as a whole.
While this does help in reducing duplicates it ultimately relies on remote peers being able to act on the control message in time. If they do not, the message still ends up being forwarded wasting bandwidth on both the sender and the receiver. So how can we improve on this?
Our Solution
We enshrine a lazy-pull mechanism adjacent to the original eager-push mechanism in v2 of GossipSub. With lazy-pull we only broadcast the message ids instead of the entire message. We do so by introducing two new control messages IANNOUNCE and INEED which carry a single message id within them.
In essence, an announcement of the message is made using IANNOUNCE and a request for the announced message is made using INEED. A node waits for the actual message as a response to INEED for a configured timeout.
If the timeout expires it tries to get the message from another peer (an individual node only sends INEEDs sequentially). When the timeout occurs, the node will also down-score the peer to prevent malicious peers from ignoring INEEDs and never sending back the message.
With such a lazy-pull mechanism we drop the number of duplicates to nearly zero, but, by trading off latency. To minimize the effect of increased latency we introduce the concept of an announcing degree. The announcing degree indicates the number of mesh peers chosen by a node at random for lazy-pull from within its mesh. Because this splits the mesh into two, D_announce <= D always.
Before forwarding the message to each mesh peer, the node will toss a coin to decide whether to send the message lazily with the probability of D_announce/D or otherwise send the message eagerly, so expectedly the node sends the message lazily to D_announce of its mesh peers and eagerly to D-D_announce of its mesh peers.
The formal spec with its simplicity accommodates for future strategies minimizing the latency effects of a lazy pull mechanism. However, in this post we explore the concept of D_announce and some other strategies through simulations.
Simulation Setup
We used the implementation of Gossipsub v2.0 of go-libp2p as shown in this PR and used Shadow as a simulator.
We ran simulations with 1,000 nodes, 20% of which have the bandwidth of 1Gbps/1Gpbs and 80% of which have 50Mbps/50Mbps. The publisher always has 1Gbps/1Gbps in order to get consistent simulation results.
The latency between each pair of nodes are consistent with the real-world geographic locations which we adopt from the simulation tool Ethshadow. We decided to spend effort to make them as close to the real world as possible because we know that the round-trip time caused by IANNOUNCE/INEED has a significant impact on the result and it’s heavily dependent on geolocations.
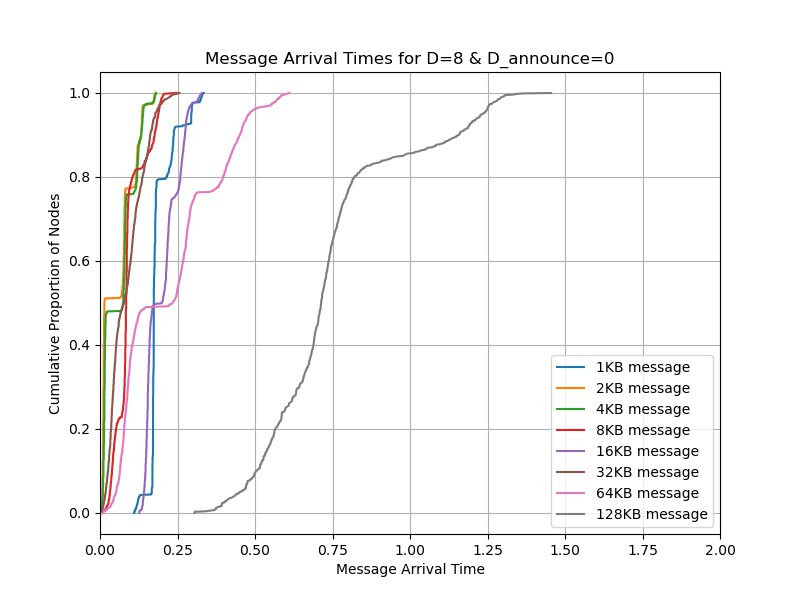
Firstly we simulate the network of a single publisher publishing a single message with different message sizes. Secondly we simulate the network of a single publisher publishing multiples message with different numbers of messages where each has a size of 128KB.
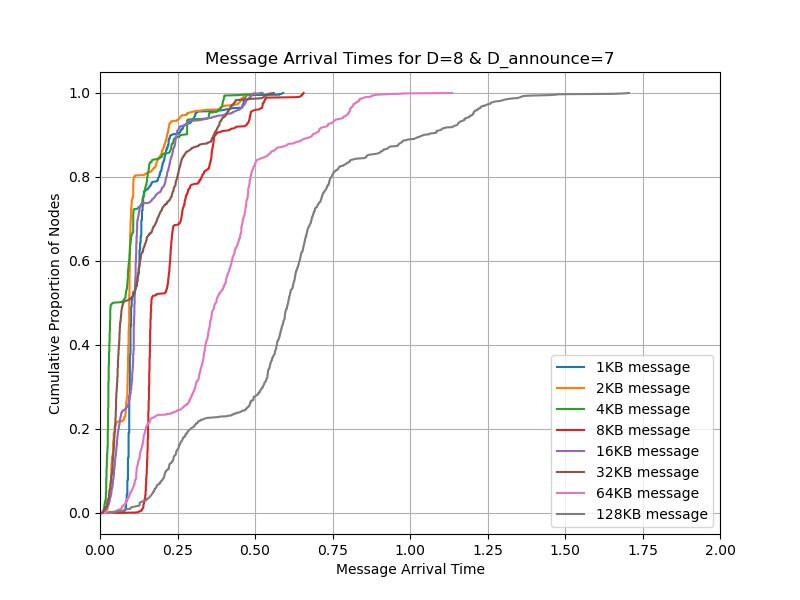
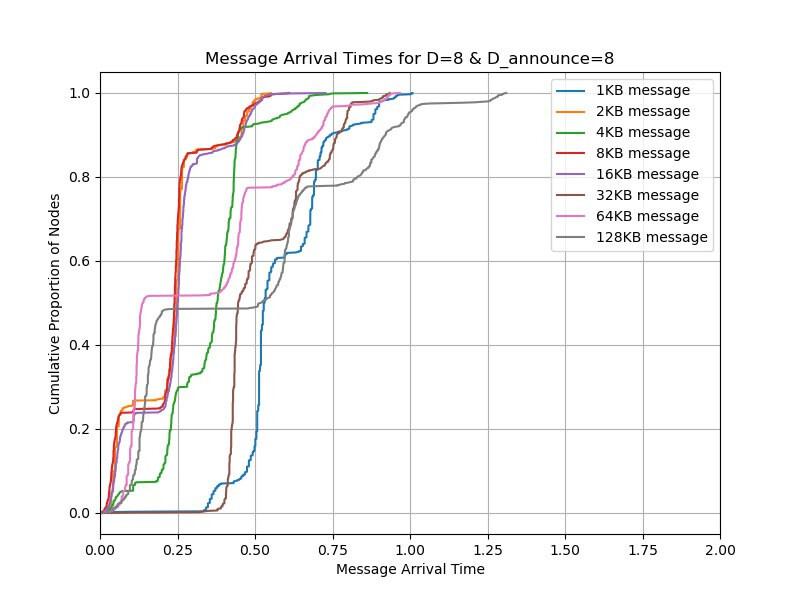
Then we repeat what we mentioned with D_announce=0,7,8 and with D=8 and the timeout of 1 second. We ran D_announce=7 to see if it will help when we add some randomness. In the cases of D_announce=7,8, we also change the heartbeat interval from the default CL value of 0.7s to 1.5s to reduce the number of duplicates from IHAVE/IWANT.
Results
Multiple messages
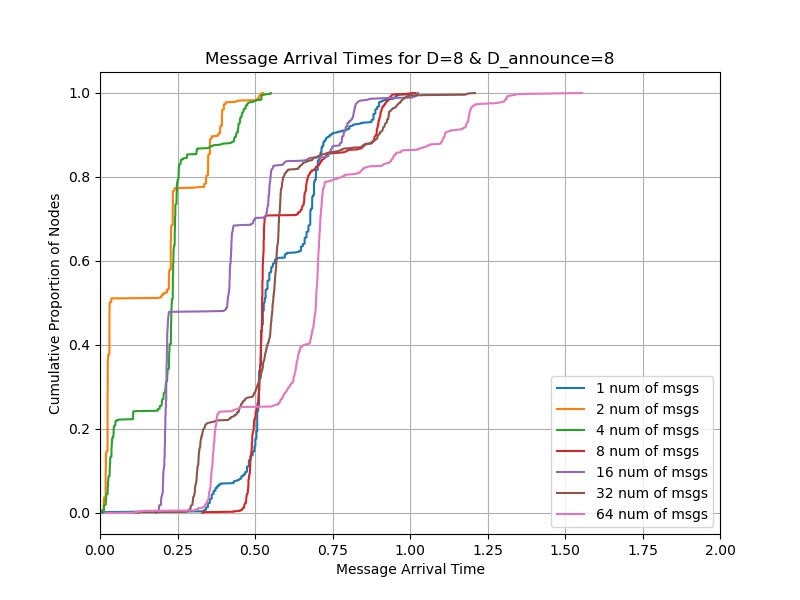
Firstly, we look at the simulations when a single publisher publishes multiple messages simultaneously.
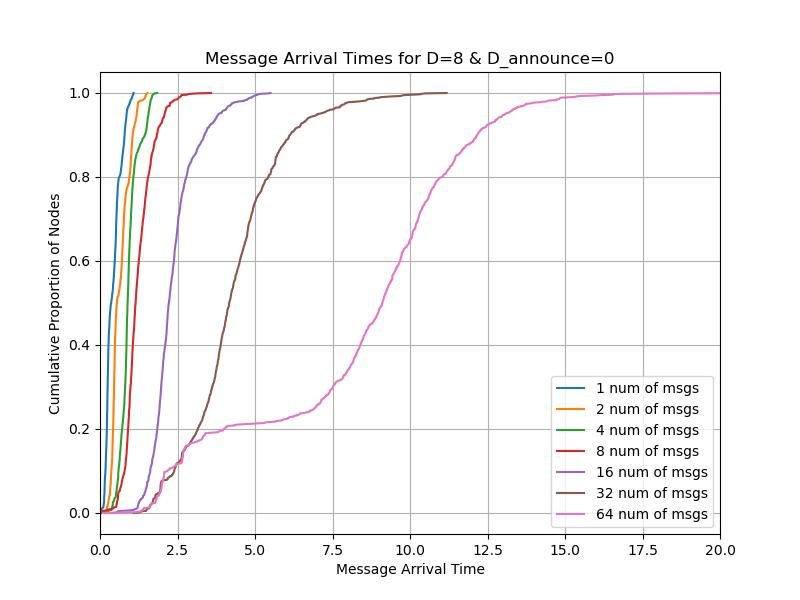
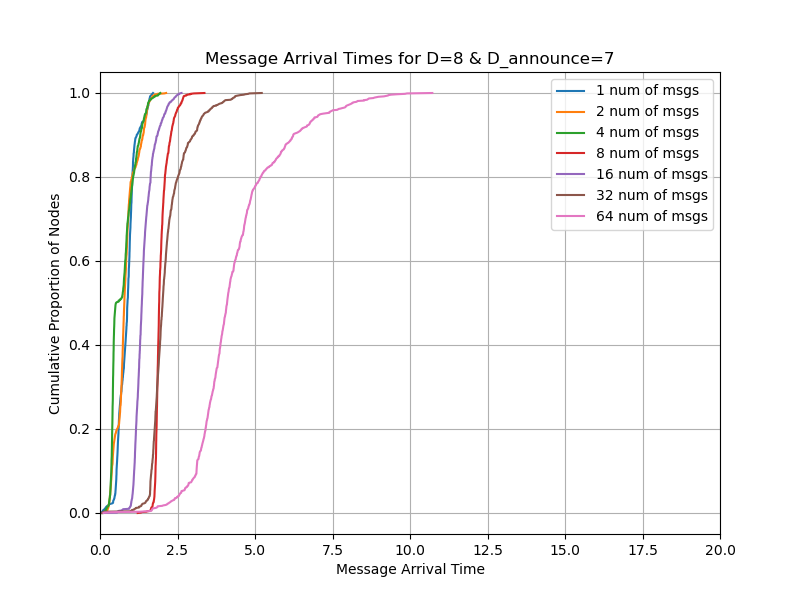
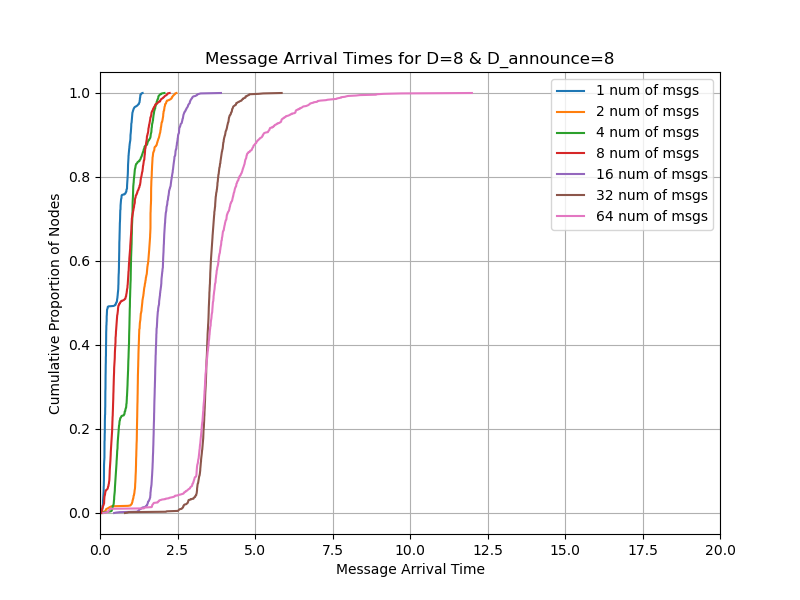
You can see from the result that with D_announce=0, you can publish 16 messages with the deadline of 4 seconds while with D_announce=7,8, you can publish 32 messages. So we conclude that we can double whatever the blob count is in Pectra.
Also note that D_announce=7 is also much better than D_announce=8 because with the latter, the propagation can be delayed by the round-trip time from each hop. With the former, each node expectedly sends the message eagerly to one random peer to allow the message to propagate faster.
Single message
Even if publishing a single message doesn’t matter much for Ethereum, we should still consider it because Gossipsub is a general-purpose pubsub protocol and publishing a single message is the most popular use case.
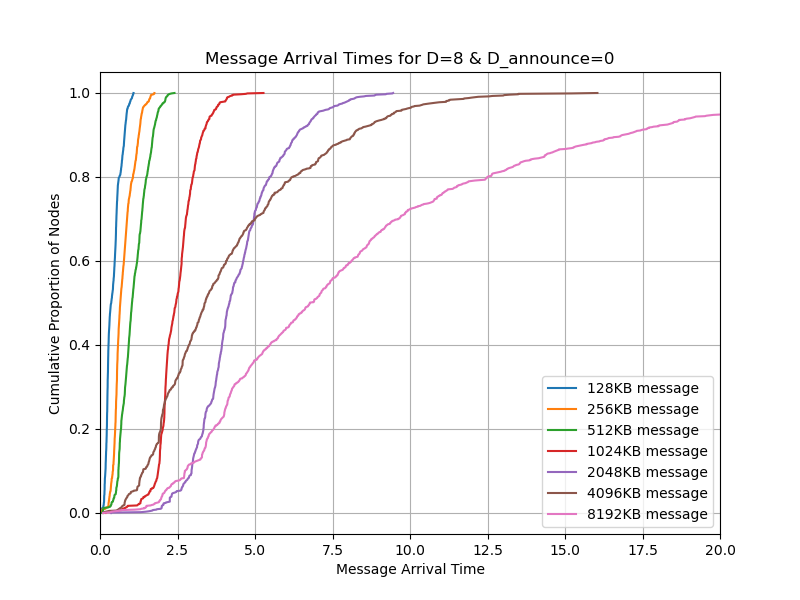
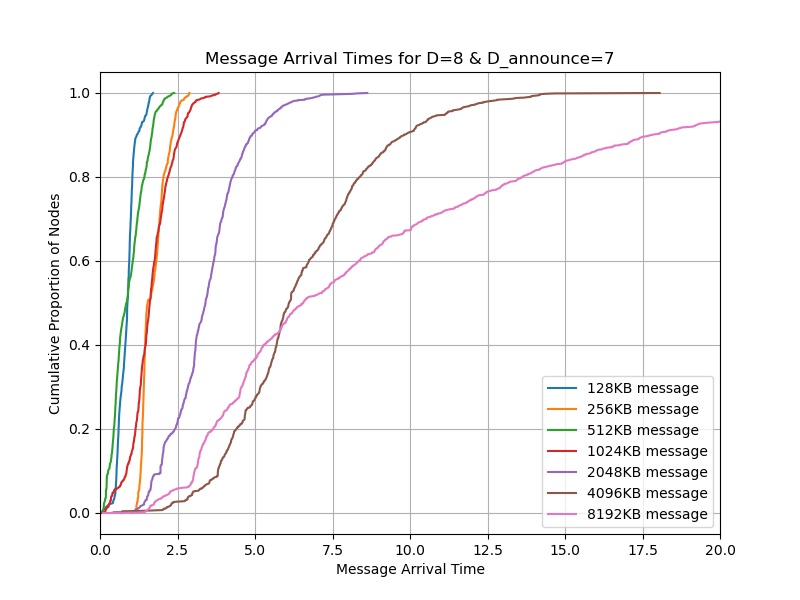
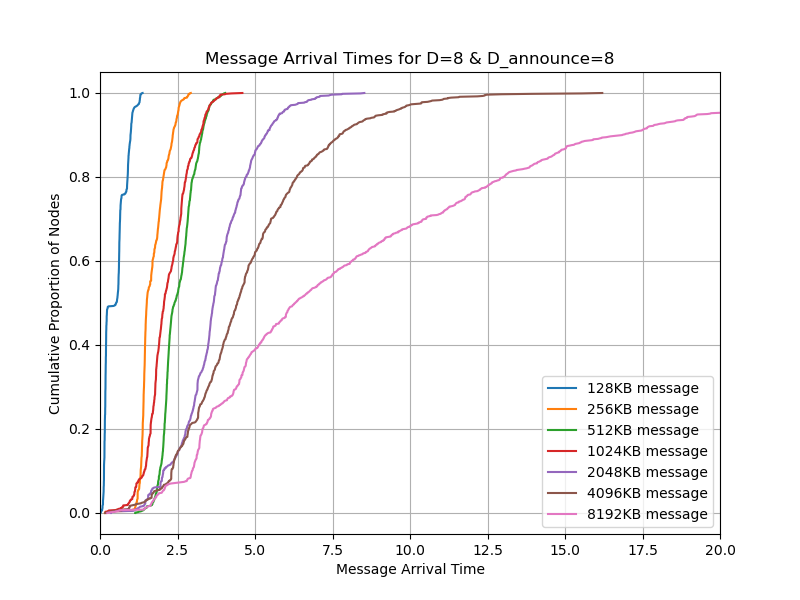
You can see from the result that we don’t gain any improvement from v2. Our hypothesis is that even if the bandwidth consumption is reduced, sometimes the links are idle because of the round-trip time.
Duplicates
Let’s look at the average number of duplicates per message for the case of multiple messages.
| 1 msg | 2 msgs | 4 msgs | 8 msgs | 16 msgs | 32 msgs | 64 msgs | |
|---|---|---|---|---|---|---|---|
| D_announce=0 | 4.515 | 5.492 | 5.658 | 5.686 | 6.161 | 7.394 | 9.232 |
| D_announce=7 | 0.598 | 0.565 | 0.586 | 1.259 | 0.767 | 1.482 | 2.244 |
| D_announce=8 | 0.192 | 0.804 | 0.179 | 0.395 | 0.769 | 0.673 | 1.236 |
You can see that the number has improved so much that further bandwidth optimisation probably would not benefit much.
We also noticed that almost all of the remaining duplicates are due to IHAVE/IWANT which we think we should reconsider how important it really is.
Now look at the average number of duplicates for the case of a single message.
| 128KB | 256KB | 512KB | 1024KB | 2048KB | 4096KB | 8192KB | |
|---|---|---|---|---|---|---|---|
| D_announce=0 | 4.515 | 4.749 | 5.122 | 5.832 | 8.909 | 11.022 | 12.990 |
| D_announce=7 | 0.598 | 2.284 | 1.163 | 2.506 | 4.078 | 6.971 | 9.275 |
| D_announce=8 | 0.192 | 1.777 | 1.087 | 1.950 | 3.762 | 5.927 | 8.692 |
The numbers look good for 128KB to 1024KB, but they did not improve much for larger messages. That is because larger messages take more time to send between peers and then INEED timeout is more likely to occur. It results in sending many INEEDs and then leads to receiving more duplicates.
Concerns
The major concern of Gossipsub v2 is that we introduces a new parameter called INEED timeout, which is the time a node will wait for a message after sending INEED.
Setting the timeout is tricky. We don’t want malicious actors to ignore INEEDs or delay sending messages. We should set the timeout in a way that all honest nodes are able to follow most of the time.
When you down-score a peer after the timeout occurs, you also have to make sure that you don’t down-score too much. Otherwise, you will kick out honest peers too quickly when they occasionally trigger the timeout. A possible alternative would be to ignore IANNOUNCE messages from peers who have repeatedly ignored or responded too late to INEED messages previously rather than down-score them.
Currently we set the timeout to 1 second because even if you have three consecutive peers triggering the timeout, you would still be able to receive the messages within the deadline of 4 seconds or even better IHAVE/IWANT will sometimes help you get the message before the deadline. The simulation result also suggests that timeouts by honest nodes don’t make you miss the deadline.
Acknowledgements
Thank Vyzo for valuable comments on AnnounceSub which was a predecessor of GossipSub v2.0.
Further research
- Reconsider how important IHAVE/IWANT is. Can we remove it completely or we reduce its effect instead, such as by increasing the heartbeat interval, etc?
- Simulate the network with 5%, 10%, 20% of malicious nodes in the network, where malicious nodes mean nodes that ignore INEEDs.
- Define exactly how much a node should down-score a peer after a timeout occurs.
- Perhaps we don’t need the timeout for INEED, but it’s better to down-score peers based on how late they reply back the message.
- Integrate with Codex’s batch publishing and see the result.
Resources
- Gossipsub v2.0 spec: Gossipsub v2.0 spec: Lower or zero duplicates by lazy mesh propagation by ppopth · Pull Request #653 · libp2p/specs · GitHub
- Gossipsub v2.0 implementation in go-libp2p-pubsub: Gossipsub v2.0 by ppopth · Pull Request #587 · libp2p/go-libp2p-pubsub · GitHub
- If you would like to re-run the simulation, you can use the following repo: GitHub - ppopth/pubsub-shadow