Author: @cskiraly
This research was conducted by the Codex Research Team: @cskiraly, @leobago and @dryajov
TL;DR
- We can achieve significantly lower latencies in DAS by applying chunk/peer scheduling techniques compared to using “standard” GossipSub.
- If the main bandwidth constraint is the publisher’s uplink, individual segments will get diffused in the system shortly after sending out their first copy. Hence, first copies should be prioritized.
- Batch publishing is a way to introduce this prioritization in GossipSub.
- Beyond GossipSub, similar chunk/peer scheduling techniques are beneficial in other protocols designed for DAS as well.
Intro
There are cases where an application should send out multiple messages over GossipSub simultaneously. A typical example of this is the use of GossipSub in PeerDAS and FullDAS, where a larger block of data is erasure coded and split up into multiple segments (columns, rows, or cells), and each of these is published on different “column topics” (or row/column topics) as individual messages.
While these messages could be sent out sequentially, publishing them one-by-one as it is done in implementations today, the notion of these belonging to the same “batch” allows for more advanced scheduling, resulting in substantial performance gains.
While we have mentioned and used such scheduling in our simulators and presentations in the past, we’ve not yet provided a dedicated writeup. So here it comes.
The Problem
The problem with typical GossipSub implementations is that an ordering of messages is enforced by the publish API. When a message is published, it is immediately sent (queued for sending) to all selected neighbours on the relative topic. In case of limited available uplink bandwidth the end result is that the “first” message will propagate fast, while the “last” messages will face long queuing times and thus start diffusion very late, breaking the “diffusion balance” between messages with otherwise equivalent priority.
Intuitively, it is clear that the entirety of the data cannot be diffused in the system before at least one copy of each segment is sent out by the publisher (for the sake of simplicity we disregard the effect of erasure coding and on-the-fly repair for now). If some parts are sent out multiple times over a limited capacity link, the diffusion of other parts will be unavoidably delayed. Hence, we need better control over the ordering of message sending.
Proposed Solution: Batch Publishing
We can use chunk and peer scheduling techniques to balance the diffusion of segments. Our technique is not new, it is clearly inspired by literature and best practices on efficient p2p distribution (see e.g. rarest first chunk scheduling policies in Bittorrent, or some other literature related to chunk/peer scheduling).
We have used such scheduling techniques since the beginning of our DAS simulations. In fact, scheduling is important independent of whether GossipSub or some other custom pub-sub protocol is used, but here we focus on the GossipSub aspect.
While chunk and peer scheduling can be quite complex, here we describe a simple strategy that improves performance considerably. The main intent is to make sure a first copy of each message in the batch is sent out to the network before second, third, etc. copies are sent out. In other words, we interleave the publishing of messages. This allows p2p redistribution to happen as fast as possible, distributing load over the network in a timely manner.
We propose the introduction of the notion of “batch publishing” to describe and handle such a scenario. The role of batch publishing is to explicitly inform the underlying protocol stack that a group of messages belongs together, allowing the stack to optimize publishing priorities according to this information. Various implementations are possible at the API level (passing all messages in one call, passing a special iterator, etc.), and various scheduling techniques can be implemented underneath.
Once batch publishing is available at the API level, the implementation of a scheduling policy is relatively simple. A prototype implementation of a simple interleaved strategy is available in nim-libp2p, which we use for results presented below.
Simulations
We use the Nim version of our DAS Simulator, with a modified nim-libp2p GossipSub stack implementing batch publish. The simulator is based on the Shadow Network Simulator framework.
Our scenario for the performance comparison is a homogeneous PeerDAS-like (although largely simplified) scenario:
- blobs: 128KB erasure coded to 256KB
- blob count: 8
- columns count: 128
- custody: 16
- Number of nodes: 1000 (ideally we should use 10000, but we need a bigger simulation server for that and 1000 is still indicative of performance gains)
- network latency between nodes: 50ms
- GossipSub degree: 8
- Uplink and downlink bandwidth limit: between 10 Mbps and 100 Mbps
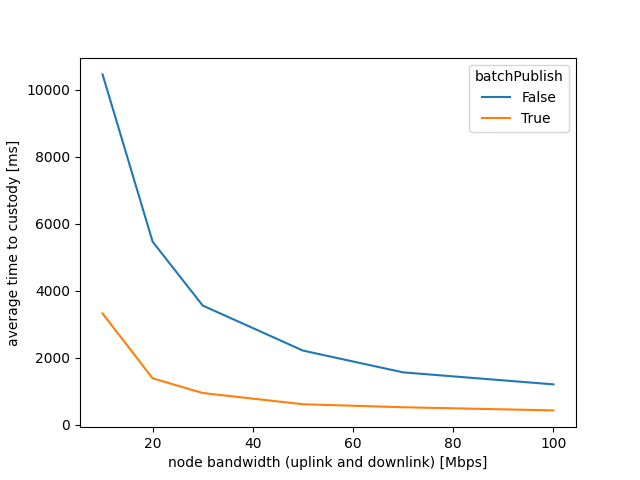
The above summary figure shows average time to custody as a function of the available (symmetric) network bandwidth, with traditional (sequential) and with batch publishing. We take the time to custody (when all 16 columns have arrived) of every one of the 999 nodes, and average these values.
As expected, there is a tremendous advantage to batch publishing when available bandwidth is low, and there is notable advantage even at higher bandwidth.
To understand better what happens in the network, we also show detailed figures for both the traditional and batch publishing cases. Because of the level of detail, we should focus on a specific bandwidth: we select the 20 Mpbs scenario. These are dense figures with many overlapping curves, and we need some explanation:
- per message propagation: shows a curve for each individual message (we have 128 of these), with each curve showing the percentage of diffusion in the network of the message as a function of time. The percentage of diffusion is measured among those nodes that subscribed to the specific column.
- per peer custody progress: shows a curve for each peer (999 curves), with each curve showing the percentage of custody columns arrived. 100% means all 16 columns have arrived.
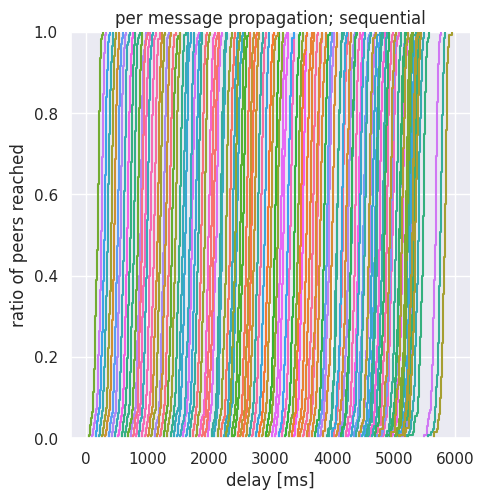
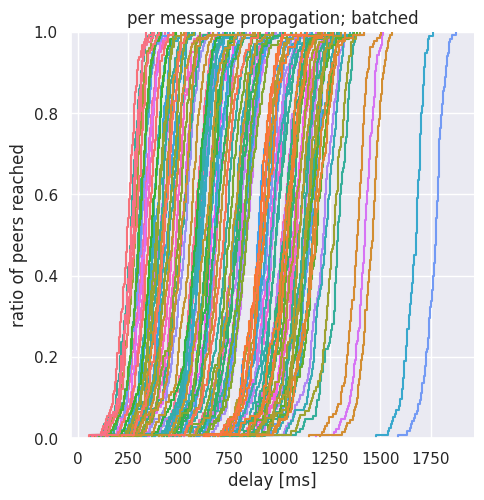
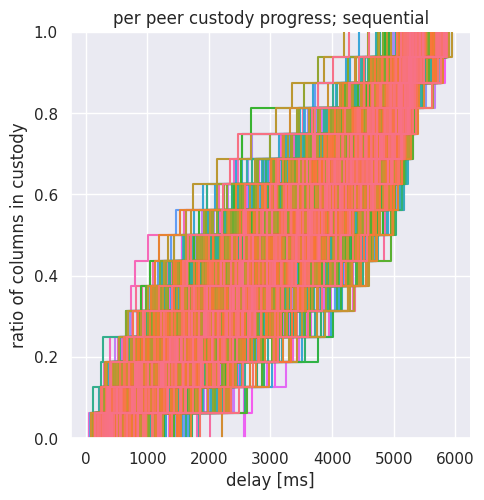
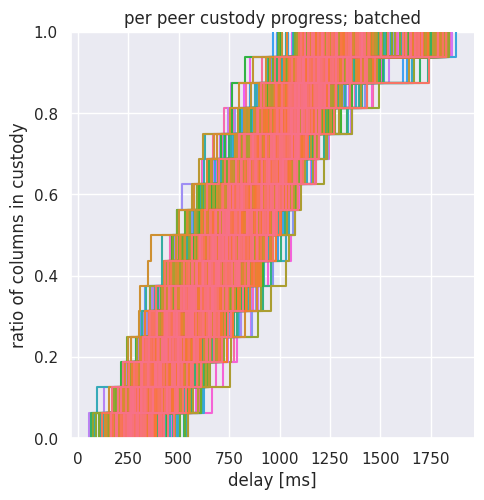
Note that the x-axis has a different scale for the sequential and for the batch case.
As first copies of messages leave the publisher, curves start at the bottom of the per message plot. Clearly, this happens much earlier with batching. Once the first copy is out, the network has plenty of bandwidth and p2p multiplicative effect to diffuse individual messages, leading to 100% diffusion for the given message in a short time.
The per peer plot instead shows us how custody progress is uniform among peers in the batched case. At any quantile (horizontal cut on the figure) the time difference between the best and worst peer is not more than 400ms. Only at the last diffusion step (from 15 columns in custody to all 16 columns in custody) the plot widens. Note that we have already introduced techniques to “cut” this tail of the distribution in our LossyDAS post, and similar techniques could be used here as well.
If instead we look at the case of the sequential strategy, we see that the difference between the custody progress of individual peers is much bigger: several seconds.
Further experiments will be conducted with different parameters and with heterogeneous scenarios, but we expect baching to provide significant benefits also in other cases.
Sounds Great, but How Many Blobs?
The previous simulation was run with 8 blobs. In the figure below we vary the number of blobs from 3 to 64, and plot the average time to custody as a function of available network bandwidth. This is still a homogeneous network scenario, but indicative of what to expect (also note that this is plotted from single runs at the moment, so curves are not smooth).
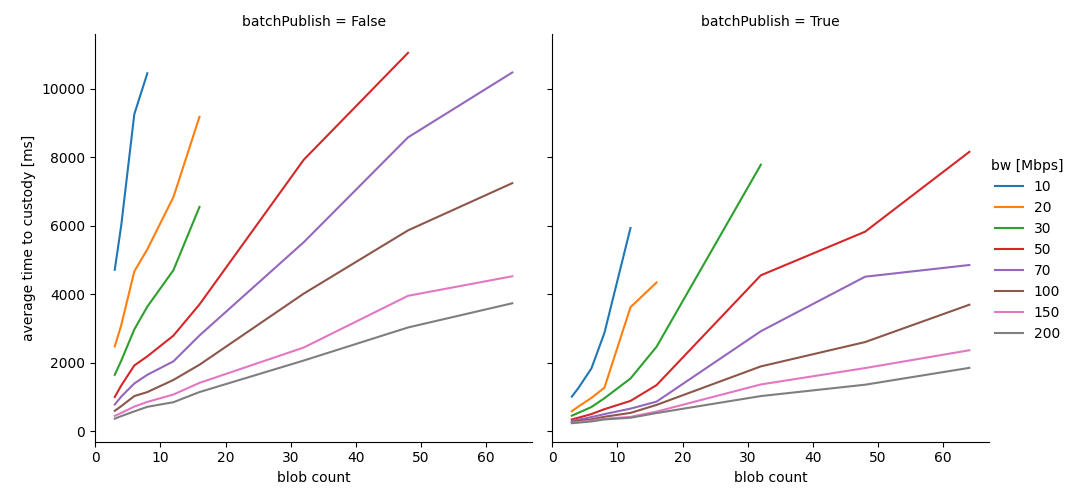
The results seem promising, showing that Batch Publishing could really help in increasing the blob count in PeerDAS.
Further experiments will be conducted with different parameters and with heterogeneous scenarios, but we expect batching to provide significant benefits also in other cases.
Discussion
Batch publishing is only one of the techniques we prepare to improve the performance of DAS. We have mentioned several other possibilities in our FullDAS writeup and presentations, and plan to provide details on more in the future.
Similar effects to batch publishing can be achieved by so called “staggered sending” which was studied by Tanguy and @Nashatyrev in the past. We think the notion of batching provides a better semantics and allows better scheduling than staggered send.
When considering possible scheduling strategies, there are many ways to complicate ![]() the above described simple interleaving:
the above described simple interleaving:
-
Message order randomisation: the order of messages in the batch could be randomly shuffled between iterations. This has the advantage of removing even more bias from the distribution.
-
Per-message peer order randomisation: Regarding the first, second, etc. copies of a single message, we can randomise the order of mesh peers. This is to make sure load is distributed evenly among peers. Of course randomisation is not the only possible strategy, just the simplest one. Different peers can be mesh neighbours in multiple topics. Counter-based strategies can provide more even distribution; weighted random strategies can be used if there is more information (peer score, latency, bandwidth estimate, etc.) about peers.
-
Feedback based adjustment: in cases of low uplink bandwidth, it can easily happen that by the time the batch publisher starts to send out second copies, most messages are already diffused in the network. Feedback about the diffusion state of individual messages (e.g. through IHAVE messages) might also start to come in. Such feedback can be used to prioritise the seeding of 2nd, 3rd, etc. copies of one message over another. We note that such feedback cannot be trusted, so care should be taken when adapting the sending schedule. As an alternative, a hidden trusted “buddy” node could also be used to observe the diffusion state.
As mentioned before, batching and chunk/peer scheduling can be used not just with GossipSub, but also with other pub-sub protocols where multiple copies are sent out. This is true for UDP-based protocols, and even if we use erasure coding. A notable exception to this is the use of fountain codes or random linear network coding, where there are no replicas. In that case peer scheduling might still be important, but chunk scheduling is not directly applicable.
The goal of Batch Publishing is to reduce the impact of a bandwidth bottleneck at the publisher, allowing for better home staking. It significantly improves latency even if available bandwidth is higher. Other techniqes under development such as Distributed Blob Building are complimentary to our technique.
References
[1] Original PeerDAS post
[2] Our FullDAS post
[3] DEVCON SEA Talk on Scalability
https://app.devcon.org/schedule/EVSLDH
[4] libp2p Day 2024 Bangkok Talk

[5] Batch Publishing prototype implementation