PPPT: Fighting the Gossipsub Overhead with Push-Pull Phase Transition
Author: @cskiraly
Note: an early version of PPPT and the algorithms discussed here were introduced in May 2024 in our FullDAS post. A version with measurements was also presented and circulated in slides in January 2025.
Recently, several research groups started working on similar topics, while sharing ideas in various discussion forums. One such excellent work has just been published under the name “GossipSub v2.0”. The ProbeLab team is also involved in related standardization efforts. We do not provide a direct comparison between these approaches in our post, but leave it for further discussion (e.g. in the comments below).
In our previous post we have introduced Batch Publishing, showing significant latency improvements in DAS dispersal, fighting the bandwidth bottleneck at the publisher.
Even if one implements Batch Publishing at the source, GossipSub comes with a large bandwidth overhead during the p2p redistribution due to duplicates. In this post we address this concern, showing techniques to reduce or even eliminate this overhead.
There is of course no free lunch. The techniques introduced here come with compromises, which we will also detail.
The GossipSub Overhead
GossipSub was introduced as a “general purpose pubsub protocol with moderate amplification factors and good scaling properties”. While its bandwidth efficiency is much better than naive FloodSub, it still has a significant bandwidth overhead, causing concern for some of the Ethereum use cases.
GossipSub is based on two main techniques, what we call push, and pull in this writeup.
-
For any given topic, GossipSub constructs a randomised mesh of degree approximately D, and proactively PUSHes messages along this mesh.
-
It also distributes “HAVE” metadata along the larger neighborhood graph (this is the gossip part of GossipSub using so called IHAVE messages), and recovers missing messages by PULLing based on this information.
In the base version of GossipSub PUSH is used for fast dissemination, while PULL is only used for the recovery of losses. A node receiving a message from a peer queues it for sending to all D-1 of it’s mesh peers (D-1, because it is not sending back to the peer it received from). This is the behavior on first reception. Other receptions are deemed duplicates, and are easily filtered out. The question we try to answer here is:
How many duplicates we have, and what can we do to reduce this number with no (or small) sacrifices on performance?
Number of duplicates vs. number of copies
Sometimes it is easier to reason about copies then duplicates. If a node receives C copies of a message, only the first one is useful, while C-1 of these are duplicates.
Number of copies sent
Trivially, each one of the N nodes subscribed to the topic will have a “first reception”, after which it sends D-1 copies, so we will have N * (D-1) copies sent in the system overall. Of all these, only N-1 are useful, the others have to be duplicates.
Number of copies received
The average number of copies received by a node will also be the same: D-1, simply because summing the number of messages sent and received by all nodes we get the same number. However, D-1 is just the average. The number of received copies can vary a lot from node-to-node. In fact it is between 1 and D (in practice node degrees might slightly deviate from D, so the number of copies received can also be a bit larger).
Who are the lucky nodes receiving few duplicates?
The intuition is simple: when the message is sent out first by the source, D nodes will get it. These are the nodes getting it in the 1st hop. Because of the random construction of the mesh, the probability of these being mesh neighbors is rather low. The probability of two of the 1st hop nodes sending to the same node is also low. So when they send to all their neighbors (except back to the source), the 2nd hop nodes will all get their first copies, and don’t send back. Hence, our 1st hop nodes will get almost no duplicates. We have more 2nd hop nodes then first hop nodes, some (but few) of these will be connected to each other, and some of their neighbors (3rd hop) will also be in common. Etc.
Towards the end of the diffusion process, after many hops, the situation is very different. A node that first received the message after e.g. 5 hops still sends it out to D-1 others, but the probability of these neighbors being nodes that have received the message already, i.e. the message being a duplicate, is rather high.
Hop-count vs. duplicates received
While a hop counter is not part of the standard GossipSub message structure, we have amended the nim-libp2p code to include one, so we can easily collect information about the distribution of duplicates received per hop-count. More precisely, we use the hop counter of the first received copy, which is kind of graph distance from the source. A node also gets other copies later on, most probably with larger hop-counts (although a smaller is also possible because of different link latencies). For simplicity here we use the hop counter of the first reception, not the shortest path.
Note that this hop counter is for measurement purposes in our experiment, not for use in the wild (see privacy concerns later).
The figure below shows the distribution of the number of message copies received, as a function of the distance of the node from the source (firsthops: the first hop counter value encountered).
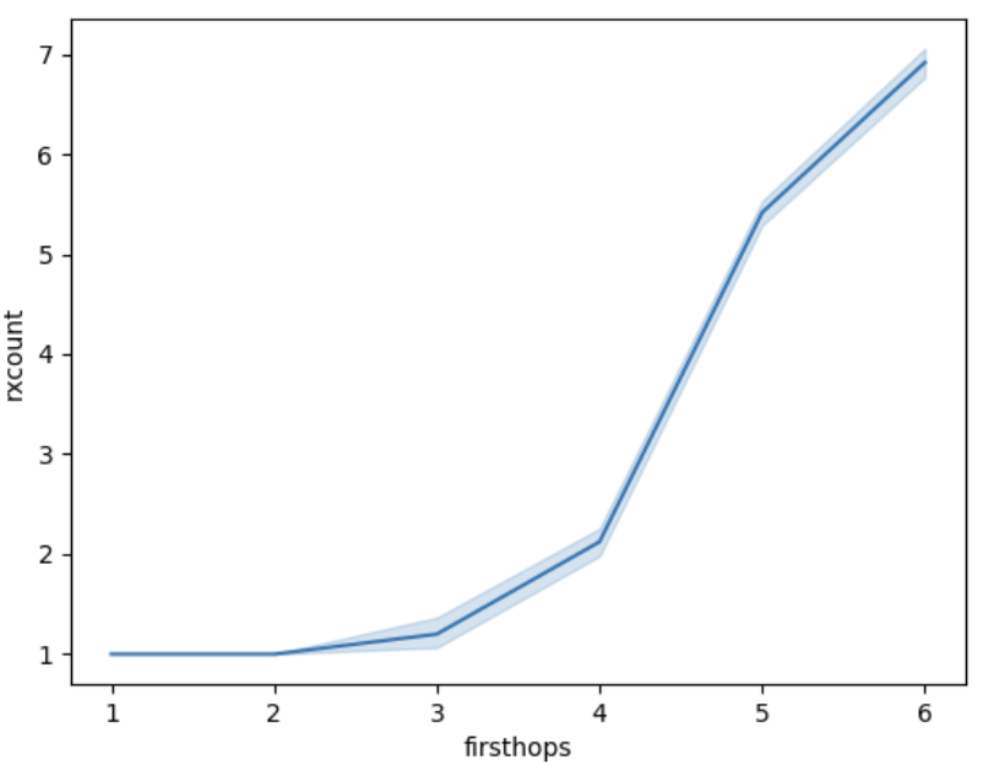
Figure 1: Number of message receptions (1 + duplicates) per peer, as a function of the peer’s hop distance from the message source.
As we can see, the later (bigger firsthop count) a node receives the message, the more duplicates it gets after this first reception. If we add to this the fact that the number of nodes is also almost exponentially growing by firsthop count, it becomes clear that to eliminate duplicates, we should remove them from the later stages of the diffusion. In what follows we compare a few ways to try to achieve this, but before going there, we show the extreme case, where no duplicates occur.
Pull mode
The simplest way to remove duplicates is to use only PULL mode. Once a message is received, a node sends D-1 IHAVE messages to its peers. This is a slight but very simple modification of the protocol. In pull mode, each hop takes more time, since IHAVE (A->B), IWANT (B->A) and then the message itself (A->B) add 3-times the latency then a simple PUSH. IHAVE and IWANT also adds extra traffic bytes, but this can be negligible depending on the message size.
The following figure shows the relation of duplicates and firsthop count in case of Pull. Rather boring.
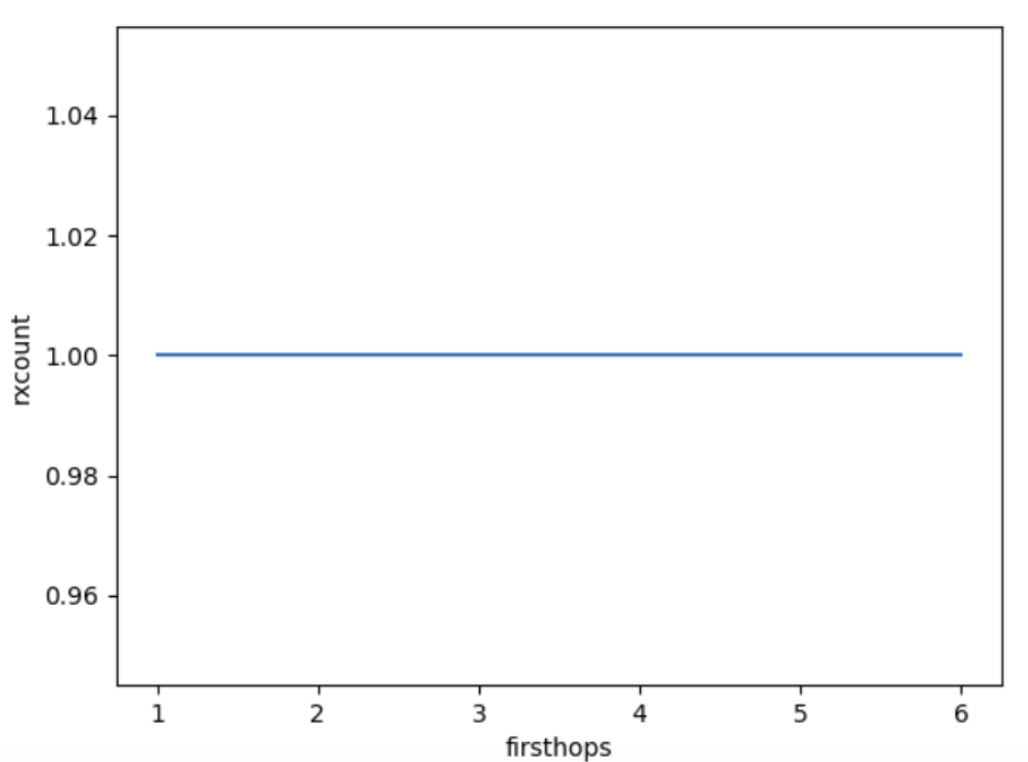
Figure 2: Number of message receptions (1 + duplicates) per peer when using pure Pull. Just to show the difference from Push, otherwise boring.
Delay-based Suppression
Besides switching from PUSH to PULL, we have another means to reduce overhead: simply avoid sending.
Large part of the duplicates are in fact due to messages traversing the same A - B link in both directions. If we add a small (\delta) delay before forwarding, some duplicates might come in, and then we can avoid sending back on those link, sending less than D-1 copies. Note that IDONTWANT works in this dimension, sending a small “warning” before forwarding, even before validating the message.
If we receive duplicates during this timeframe, we do not send back on those links. Thus, some of our nodes will send less then D-1 copies. Note that some wait happens in all implementations because of the GossipSub message validation delay. The Nim implementation already uses this delay to suppress sending messages, while some others don’t do this.
Understanding the Latency-Bandwidth Tradeoff
With all the above intro, we have now arrived to the point where we can map out the tradeoff space between the two extremes of pure PUSH and pure PULL, adding also delays to the decision logic.
We introduce four different strategies, each one of them having a parameter that allows us to “tune” the tradeoff.
-
Wait (\delta): the easiest thing we can do is to just wait some \delta time after reception, before sending the copies. If we receive duplicates during this timeframe, we do not send back on those links. Thus, our nodes could send less then D-1 copies. Note that some wait happens in all implementations because of the gossipsub message validation delay. The Nim implementation already uses this delay to suppress sending messages, while some others don’t do this. (suppressNone)
-
Wait-and-Pull (\delta): in this strategy we again wait \delta time, but if duplicates were received, we not just suppress sending. We also change to PULL mode, sending IHAVEs on all remaining links. (SuppressIfSeen)
-
Push-Pull (d): in this strategy we have D neighbors, but we only PUSH to a subset of these, while we use PULL mode for the rest. We use the d parameter to set the tradeoff, pushing to d randomly selected peers, while sending IWANT to the rest. (suppressAbove)
-
Push-Pull Phase Transition (d), or PPPT: in our last variant we rely on the hop counter. When a node receives a message first with a hop-count value of h, it sends max(0, d-h) PUSHes, and PULL to the rest. (suppressOnHops)
Note that only the last one of these uses the hop counter, the rest can be implemented without modification to the message format (we do use the hop counter in our code to collect statistics). Exposing the hop-count is a controversial topic, we will discuss this in more detail later.
Simulation scenario
To derive performance metics, we use our Shadow and nim-libp2p based simulator. We run simulation with the following parameters:
-
1000 nodes subscribed to the topic
-
small message size of 1KB
-
restricting node bandwidth to symmetric 20 Mbps.
-
p2p latency: previous plots were with a uniform 50ms latency between nodes to simplify presentation of the effect of Push vs Pull. However, this uniformity creates side effects, so in the following plots we use latencies derived from measurements on the real Internet (RIPE Atlas database), mapping each one of our nodes to a random location on Earth. The average latency is 62ms, but there are many links much faster than that.
The following figure shows the tradeoff space between duplicates and reception latency, with points representing the performance of a given strategy with a given parameter according to two metrics:
-
the x axis shows the achieved average delivery latency (we could do a similar plot for e.g. the 95 percentile latency). Smaller values are better, with pure PUSH on the left side and pure PULL on the right side.
-
the y axis represents the average number of copies. Smaller values are better, with pure PULL on the bottom (1 copy received) and pure pull on the top (approx D-1 copies received on average).
As we change the respective parameter of each strategy, we can draw their tradeoff curve compromising between duplicates and latency. For example, the leftmost point of the green curve represents no wait (\delta=0), while the rightmost point shows reduced duplicates but increase delay when we wait \delta=70~ms before forwarding the message.
Similarly, for the other curves, the leftmost point is when we set the parameter such that the strategy is not triggered. This means a (\delta=0) for Wait-and-Pull, and a large value of d (larger than D) for Push-Pull and Push-Pull Phase Transition.
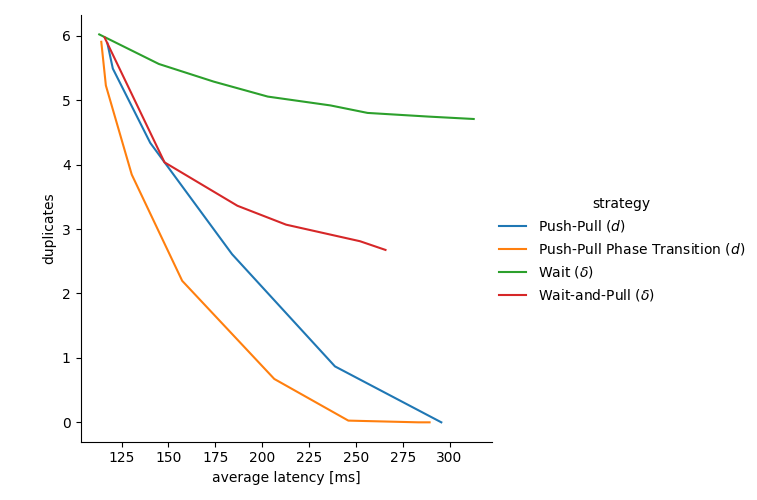
Figure 3: Trade-off between average number of received copies (i.e. bandwidth utilization) and average reception latency. Each curve represents one strategy, while the points of the curve represent different parametrizations of the strategy.
Wait (\delta) is the least effective, increasing delay while only slightly reducing the number of duplicates.
Wait-and-Pull (\delta) achieves notably better results. In fact getting duplicates in a small time window can be used as an estimator of being later in the diffusion process, without having an explicit hop counter.
Push-Pull (d) provides impressive gains, even it is a fixed strategy not requiring an estimator or hop-count.
Finally, PPPT achieves better performance than any of the previous strategies, allowing us to remove almost all duplicates with a small increase in delay, and all duplicates with when doubling the delay.
Discussion
The strategies presented above are just examples of the large variety of possible strategies. Combinations and variants of these can easily be derived. We are not aware of a generic theory that would provide some kind of optimum, especially not in the heterogeneous setting of the Internet.
While our study is preliminary, and much more could be evaluated (different node count; different message sizes; different bandwidth limitations; etc.), we can already highlight some aspects:
Hop counter advantage is clear
It is clear that adding a hop counter can provide substantial gains in reducing duplicates while keeping delay low. This is not surprising after the detailed analysis of where duplicates are in the system, it just confirms that hop-count is in fact a good trigger to change from Push to Pull.
Fixed strategy performance is not bad at all
A bit more surprising (at least to me) is that a fixed strategy also performs reasonably, although the performance curve is clearly suffering from not having the hop-count information.
Hop-count and privacy
It should also be clear that hop count is compromising publisher privacy … if there was any in the first place. We argue that libp2p and GossipSub have uses where publisher privacy is not a concern. Even in the Ethereum use cases, it is often already easy to de-anonymize senders, and in those cases hop-count is not making it substantially easier.
Hop-count can be cheated
Another disadvantage of hop-count is that it is easy to lie about it. Also, hop-count should not be part of peer-scoring, as it would create further incentives to cheat. Still, we think this is not a fundamental problem, as a node lying about the hop-count would only slow-down (or speed-up) his own subtree of the diffusion tree, without having a global effect.
GossipSub use-cases are different
We presented duplicate mitigation strategies as as a trade-off space for a reason: even in Ethereum GossipSub has many use cases (not to mention use outside of Ethereum). Different strategies and parameters might be selected for different use cases (or topic, or message sizes).
About optimize neighborhoods based on RTT
Maybe worth also mentioning that our reasoning about not having duplicates in the first hops assumes random neighborhoods. There is often the idea (in literature and in conversations) to optimize neighborhoods based on measured RTT. Unfortunately, such an optimization has the side-effect of changing the overlay graph structure, leading to much more duplicates in the first hops, and leading to a larger diameter. RTT-based optimizations can be carefully designed, but it is important to be aware of these side-effects.
IHAVE traffic overhead
In our figures we counted with message copies, but did not count with the overhead of IHAVE messages. Whether this simplification is reasonable depends on the message size, and its relation to message IDs and their encoding in IHAVE messages. We note that several optimizations are possible to move the needle here.
-
If there is a high frequency of messages on a link, their individual IHAVE messages can be aggregated in a single message at the cost of a small additional latency.
-
This IHAVE aggregation can also be performed over multiple topics, with a controlled extra latency.
-
In some use-cases, where messages can receive an ID from a structured message ID space, such aggregated IHAVE messages can also be compressed. Such is the case of DAS, where we proposed bitmap based IHAVE messages, but bitmap based compression can also be used as a more general tool.
How to reproduce
The hop-count and all strategies are implemented as part of nim-libp2p, and will be published as a branch in a follow-up shortly.
Our simulation framework also had several ad-hoc changes to accommodate these simulations, which will be published as a follow-up as well.