Author: @cskiraly
With the increase of blob count in Pectra, and the upcoming introduction of DAS in Fusaka, more attention had been drawn to the role of the EL mempool in blob diffusion and to the availability of blobs in the mempool. After working on improving Data Availability and Sampling in the Consensus Layer, we discuss how blobs are spreading in the Execution Layer mempool, and how this influences the scaling of Ethereum.
TL;DR
- Recent research largely focused on the CL, but the spreading and availability of (blob) transactions in the EL mempool is an important part of the system.
- A single EL node knows a lot about the state of transactions in the mempool from it’s peers, and we can extract this data (even more if we increase the peer count).
- Transactions are spreading vary fast in the mempool, reaching 50% of nodes in less than 2 seconds. This is true for type 3 blob carrying transactions as well.
getBlobshas lots of blob data to work with. When all blobs of a block were public (60% of the cases), it works almost perfect.- When not all blobs of a block were public, the current version of the CL has no chance, but we can fix this.
- We can make getBlobs return full results by making it wait for results to be fetched in the EL.
- We can enable the CL to use partial results by implementing cell-level messaging.
- We can make block builders select blobs wisely.
- Block builders with low uplink bandwidth (e.g. home builders) can choose blobs wisely to maximize their chances of success by sampling the mempool.
- We could make the mempool networking erasure coding aware, making it more robust and allowing better sampling.
Introduction
When blobs are selected for inclusion in a block, the block builder has to send the block and all selected blobs over the CL p2p network using GossipSub. Then, nodes need to receive these blobs (or samples of them), to use it as part of their fork choice:
- In EIP-4844, CL nodes need to receive all selected blobs.
- In PeerDAS, CL nodes should receive selected columns of the 1D encoded structure, i.e. selected segments of all selected blobs.
- Finally, in FullDAS, CL nodes require only cells of the 2D encoded strucure, so only a few selected segments of some selected blobs.
Whichever the case, it is important to note that the data that a CL node needs might have already been diffused in the EL, as part of the p2p mempool transaction exchange.
We can work on more efficient diffusion in the CL, but if such blobs were already present in the EL mempool, why send it over the CL again? The CL node can get it through the engine API from the accompanying EL node using the getBlobs interface. This has several benefits:
- CL nodes get blobs faster: if blobs are already in the mempool, there is no need to wait for the CL to diffuse them.
- CL diffusion gets faster: if a CL node can “pull” the data from the mempool, it can start contributing to the CL GossipSub diffusion even before receiving it over the CL, acting as a a “secondary source”.
- blob diffusion gets more robust: since blobs can “enter” the CL network in more points, GossipSub becomes multi-source, and fundamentally more robust.
- builders with low uplink bandwidth (e.g. home builders) can build blocks with more blobs: the chances of distributing the blob content increases, since other nodes can help seeding the content. In the extreme case, the block builder doesn’t even have to send out the blobs, just the block!
To better understand how this could work, however, we need to know how blobs diffuse in the mempool. In other words, whether blob data is available in the mempool.
What is the availability of blob data in the current mempool? What effect does the availability of blob data in the mempool have on 4844, PeerDAS, and later iterations? How the diffusion of blob data is different from other transaction types?
These are some of the questions we try to start answering in this post.
What is DA in the mempool?
DA, or Data Availability, in the context of the mempool should be interpreted at the level of transactions. If we know that a blob carrying (type 3) transaction is widely available in the mempool, we can use it in a block and be sure other nodes will have it, even if it is not sent out again over the CL. This in-turn, allows home (or low-resource) builders to build blocks with more blobs, and it also allows better blob diffusion in general.
Evaluating this in the current mempool is quite difficult: not all transactions are relevant(some doesn’t make it to a block, others are replaced), and it is also not clear at what point in time should we evaluate. We can instead focus on the availability of block transactions, i.e. transactions that made it to a block. The question we might ask is whether a transaction that became part of a block was available in the public mempool beforehand. This is something we can measure.
These are the transactions that we usually refer to as “public” transactions, with the assumption that other transactions were “private”, i.e. arrived to a block builder through some private transaction feed, without hitting the public mempool.
The above vision is however largely simplified. It stems from the underlying notion of a single mempool in the whole system, globally synchronized between all EL nodes. In reality, the mempool is a distributed database, with each EL node having it’s own partial view, also based on its own resource limits, throttling, and filtering policies. Transactions are submitted at one (or a few) points of the EL node network, then distributed to other nodes using the devP2P protocol using both push and announce (gossip) based mechanisms. The protocol is conceptually similar to the libP2P GossipSub used in the CL, but many details differ.
Simply because of the speed of light, there are differences in the mempool as seen by an EL node in Europe and one in Australia. Still, in the past such a simplified vision of a globally synchronized mempool might have been accurate enough.
Is the synchronized mempool view still accurate today? We will shortly figure out. If, however, we want to scale Ethereum to a point where the transaction throughput is more than what a single node can handle, and we want to keep the public mempool as the main entrypoint, the mempool will not be globally syncronized. Each node will have it’s local partial view, and these will be different.
Important to note that this is true regardless of us introducing new structured mempool sharding techniques, or just simply letting the current protocol handle the fragmentation of the mempool naturally, as an emergent behavior.
Methodology
How we measure DA in the Mempool? Can we do sampling and some form of DAS?
To measure DA in the mempool, we should define what and how we want to measure exactly:
- What: the unit of data in the mempool is the transaction (tx). However, we are not interested in all transaction, but only those that make it to a block. We call these “block transactions”. Note that we could easily refine this further to look for finalized transactions, etc.
- Where: we are looking at the perspective of a single EL node. Transactions that arrived to our node through the mempool protocols are clearly available. The mempool however also have gossip mechanisms, where nodes notify their peers about a transaction by sending over the tx hash. This is our Sampling. Kind of a PeerDAS at the mempool level, with the important difference that we don’t have a proof of our peer having the data, we just take our peer’s word for it. A typical EL node, having 50 peers, have 50 samples of whether a tx is (claimed to be) available at other nodes or not.
- When: We evaluate DA at the time of block arrival. Note that we could have chosen other time instances, e.g. slot start, safe-head, or finalized state. From the system perspective, block arrival is the most relevant event, where CL and EL interact over the Engine API. This is also the most important for evaluating the usefulness of getBlobs.
- To what extent: how much a transaction is available in the mempool is also interesting to know. In the simplified globally synchronized view, a tx is either in the mempool (at all nodes), or not. It is either public, or private. In reality, we might have cases where only part of the network have a given tx. It is public, just not well diffused in the network, and maybe never will be if networking resources are limited and new transactions are coming. How many nodes see a given transaction? We don’t know. But every EL node has a sample of it, simply by knowing the announcements of it’s peers.
Measurement Setup
We use a single slightly modified Geth EL instance coupled with Nimbus CL, running on a relatively powerful machine (AMD Ryzen 9 8945HS, 96GB RAM, Samsung 990 Pro SSD), well connected (2.5Gbps/2Gbps) to the Internet, running as a home node.
At block arrival, we take all block transactions, and log what we know about each transaction’s state in the mempool:
- do we have it?
- when did we receive it?
- how many nodes we’ve sent it to?
- how many of our peers reported having it, and when?
To improve the quality of our sampling, we cheat a little bit by not sending notifications, thus ensuring that we really hear back from all our peers if they have the given tx.
Results
Let’s start by analyzing block transactions by transaction type. This data is really easy to extract, we just report it here for reference.
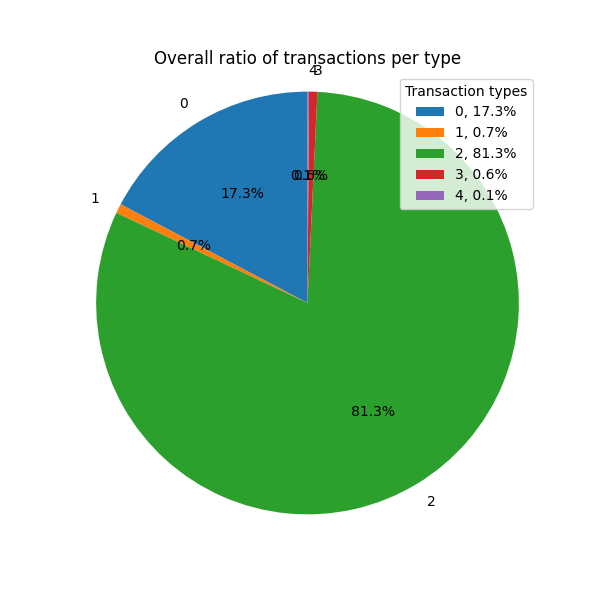

Different transaction types have different popularity in the mempool, and type 2 transactions dominate if we consider the number of transactions. If instead we factor in transaction sizes, the picture changes, and type 3 transaction dominate.
Ratio of block transactions received through the mempool
Now, lets see what part of block transactions are public (received through the mempool) and what part are private (we first heard about them from the block).
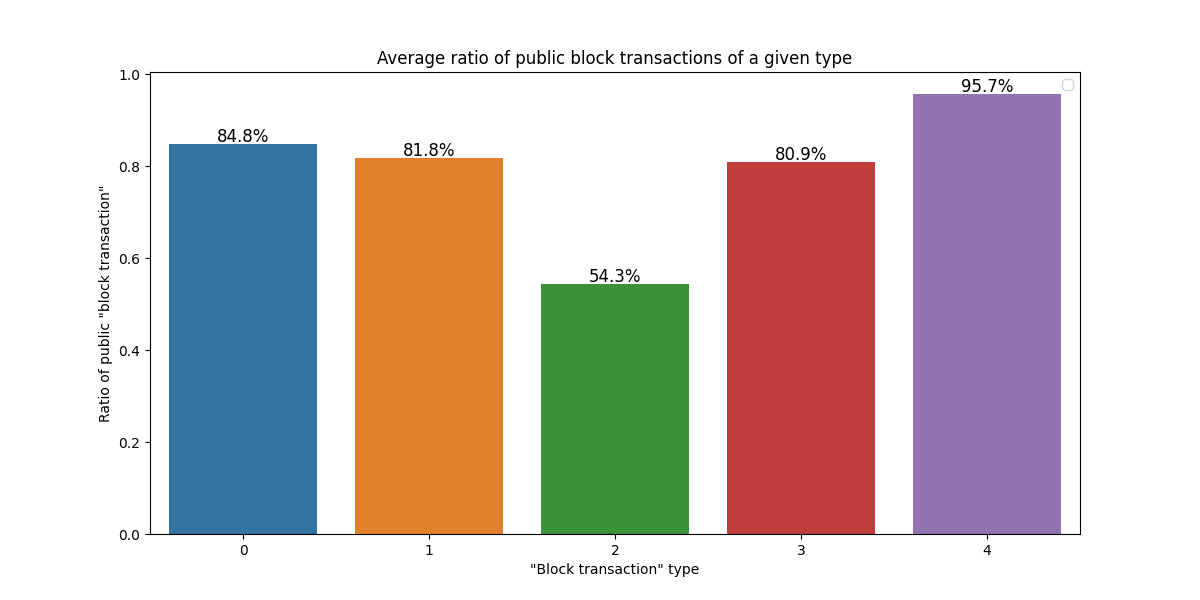
First, let’s focus on block transaction that actually arrived to our node through the mempool, without considering sampling. In the next figure, we show for each transaction type how much of the block transactions are definitely public (since we’ve actually received them through the mempool before seeing them in a block).

Clearly, if we have received a transaction from other EL nodes, that was a public transaction. While we receive approx. 80% of most transactions types, for type 2 this is only around 52%, and for the new type 4 transactions it is above 90%.
Speaking of transaction reception, note a fundamental difference between type 3 and other transactions:
- if a type 0/1/2/4 transaction is shown here as private, we have not received it from the mempool, but we have received it’s content in the block from the CL.
- if a type 3 transaction is shown here as private, we might miss the actual blob contents, i.e. the sidecar.
The transactions we haven’t received are not necessarily “private”, these can still be of different categories:
- maybe they were coming from a private feed (were never submitted to the public mempool). This is the typical assumption in most discussions.
- or maybe they were submitted to the public mempool, but the pool is fragmented, and we were unlucky, not receiving it in time.
- or maybe they were submitted late, which increases our chances of being unlucky.
Ratio of block transactions “heard of” from the mempool
To see whether some of the transaction we haven’t received were actually submitted to the mempool, we could look at our Sampling, i.e. what we heard from our peers. The plot below shows the portion of transactions we have received OR got notified about by at least one of our peers.
The difference compared to received ones is relatively small. This means that we have received almost everything we could, the network is healthy.
Note that this difference should be bigger at a bandwidth constrained node, something still to be quantified.
Sampling the diffusion state in the mempool
Above we defined a known transaction as one that we’ve got notified about from at least one of our peers. However, it is worth asking what we know about the level of diffusion of these transactions in the network. The below plot focuses only on transactions that we have identified as public (received or heard of). For each one of these, we measure what portion of our peers have reported to know them, and thus estimate their level of diffusion (a value in [0..1]). Finally, we plot the histogram of the public block transaction diffusion values.
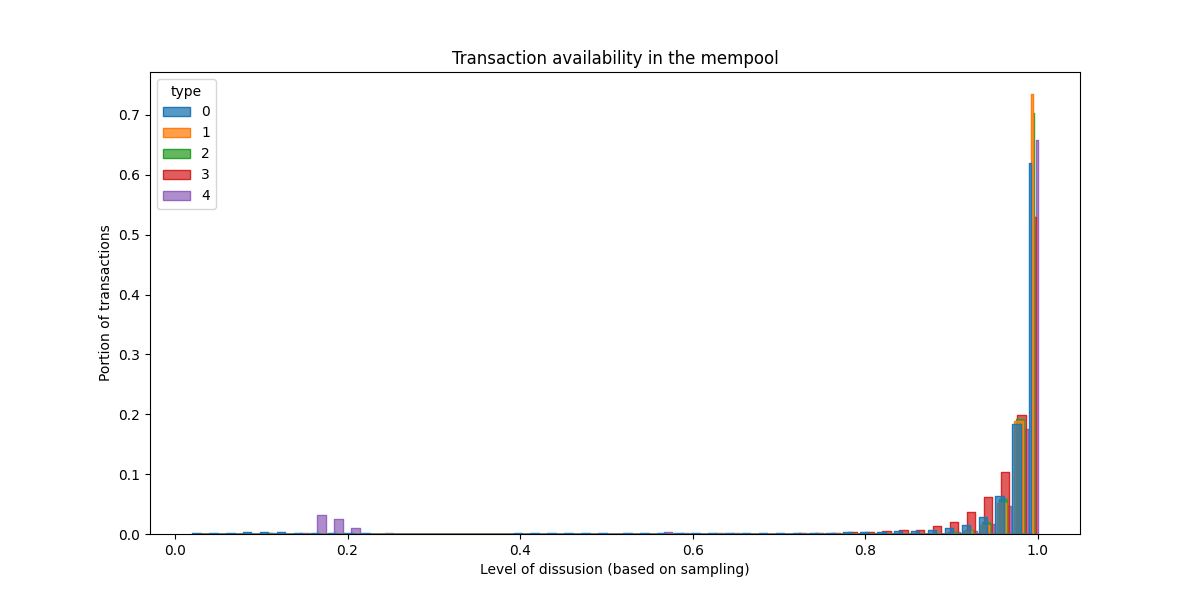
What we see is the following: if a block transaction was public, it was widely diffused in the system. This is true for all types of txs, even blobs. Again, this is the current state. We plan to monitor what happens after the following forks, and we know this can’t remain the case as we scale the public mempool.
The effect of peer count
Another interesting thing to check is how much the above results depend on our sample size, i.e. the number of peers we have. For this we’ve run a Geth instance changing peer count between 1 and 500. Below we show the averages.

The plot is a bit noisy because conditions fluctuate while we measure, but one thing is clear: even if we sample from significantly more peers (500), we don’t see more transaction as public.
Maybe more surprising, we get a complete view even if connected only to a few peers. Note that here luck plays a mayor role: we were lucky enough to have good peers when having only a few. If we would run this experiment longer, we would probably see some slight difference in the averages with fewer peers due to cases when all our few peers are weak ones. There is ongoing work to reduce the probability of this happening in Geth with faster dial and better peer selection.
The effectiveness of getBlobs
Note: some of the results in this section can be cross-checked against results shown in this work from ProbeLab.
Now that we’ve clarified everything about private vs. public transactions, we can start evaluating the usefulness of getBlobs on the Engine API, passing blob data from the EL mempool directly to the CL, circumventing eventual bottlenecks in the diffusion of blobs in the CL.
By definition, getBlobs cannot work on private transactions. These are simply not present in the mempool.
In the upcoming (Fusaka) iteration of PeerDAS, getBlobs is also not working if at least one of the blobs of a block is missing from the EL. This is because the unit of transmission in the CL is complete columns, and a column has pieces of every single blob belonging to a block. Thus, getBlobs is only useful if all blobs are present. This will change with the introduction of FullDAS, row topics, and cell-level messages, as we’ve already discussed in our FullDAS writeup.
The plot below shows the effectiveness of getBlobs according to the Fusaka model, categorizing blocks into 3 distinct groups (here we only focus on blocks that have at least one blob):
- Private: if a block has at least one blob belonging to a private type 3 transaction. Here the current version of getBlobs has no chance.
- Public, getBlobs works: these are blocks where all type 3 transaction are public, and our node received all of them by the time of block reception.
- Public, getBlobs doesn’t work: in these blocks all type 3 transactions are public, but our node misses some of them.
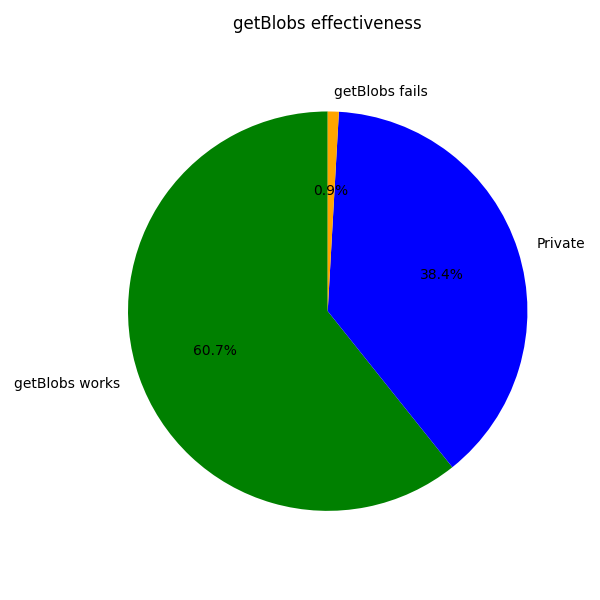
Among the cases where getBlobs could even work approx (60%), it works overwhelmingly .
This is already very good, but we could make it work even better:
- For the remaining 5.7% of blocks, we know peers who have the blob. When the block arrives and the list of important blobs becomes clear, we can request these blobs over the EL with a high priority. This is adding some delay to the getBlobs response, but it could result in the reduction or even elimination of this category where getBlobs doesn’t work.
- If we allow the CL to use cell-level messages and thus exchange partial columns, we can use the results of getBlobs even if it is partial.
getBlobs success ratio as a function of block blob-count
What will happen when we scale blobcount? We can’t measure that on the live network, but we can check the current situation, analyzing blocks by their blob count.
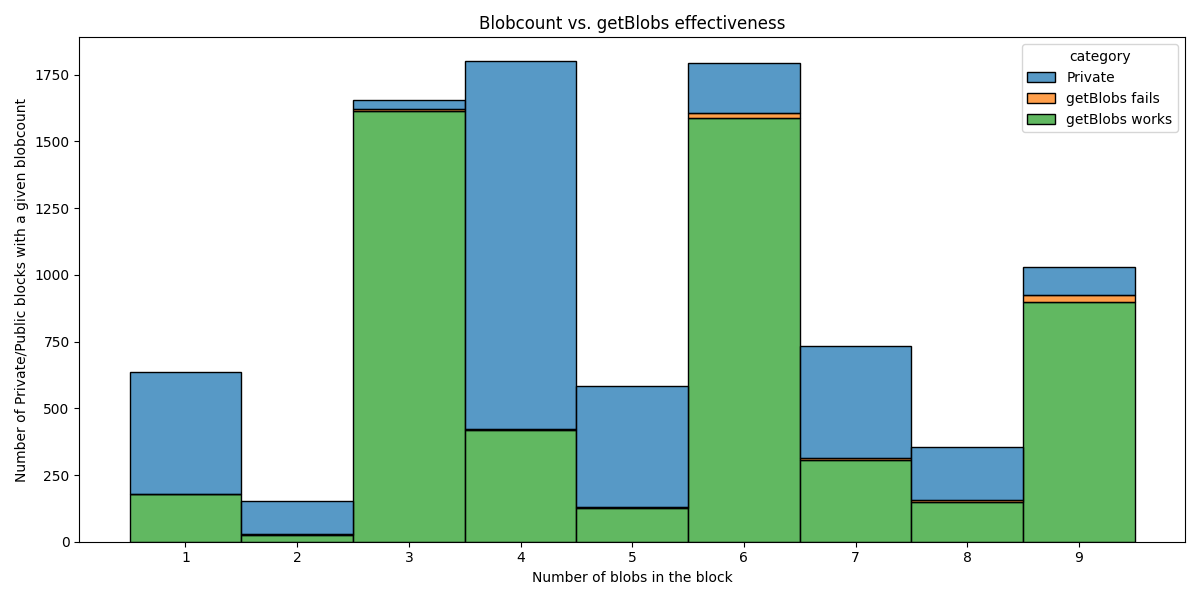
Interestingly, the ratio of blocks with private transactions vs. blocks with public transactions varies a lot based on blobcount. Maybe a longer dataset would even this out, although we think this depends more on builder strategies than on anything else.
What are more interested in is the size of the orange part, the cases where getBlobs doesn’t work. The more blobs we have, the bigger the chance getBlobs fails. Is this at a critical level with 9 blobs? Not at all, we are very far from this being an issue.
What are those blocks with private blobs?
We can also analyze how many blobs we miss from blocks with at least one private type 3 transaction. Below we focus only on these “private” blocks.
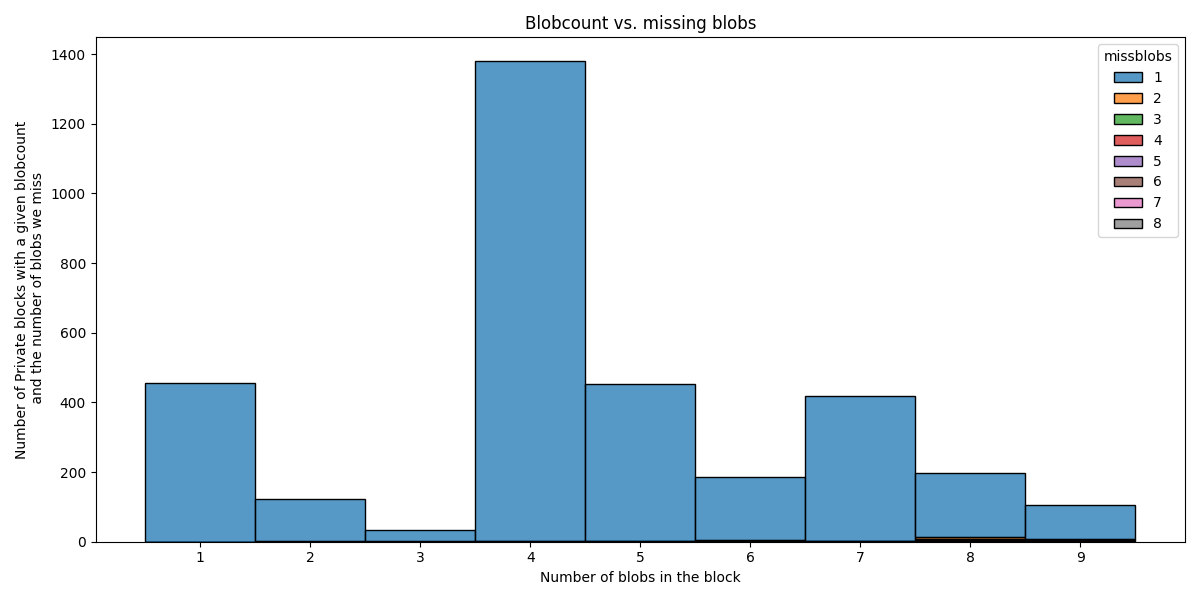
Interestingly, we almost always miss only 1 blob, even if the block had 9 blobs in total. The other values (2..8) are almost unnoticeable on the figure.
As we’ve discussed, the current version of getBlobs can’t help here. Our recommendations to block builders is to avoid making such blocks if they can’t push out enough copies. It just doesn’t worth to take the risk for adding a single extra blob.
How fast transactions spread in the mempool
Now that we know transactions that were submitted to the mempool are also widely diffused in the system, we can go even further by analyzing timing. It would be great to know when transactions arrived to every single EL node … but we don’t have that information. What we have instead is our sampling: peers announcing to us as soon as they have received a given tx. And if we scale our Geth node, we can collect these from 500 peers, i.e. from 500 distinct points in the network! We don’t have an exact timestamp of reception at the peer, but we know when we received their announcements.
Let’s see how this looks for a few transactions:
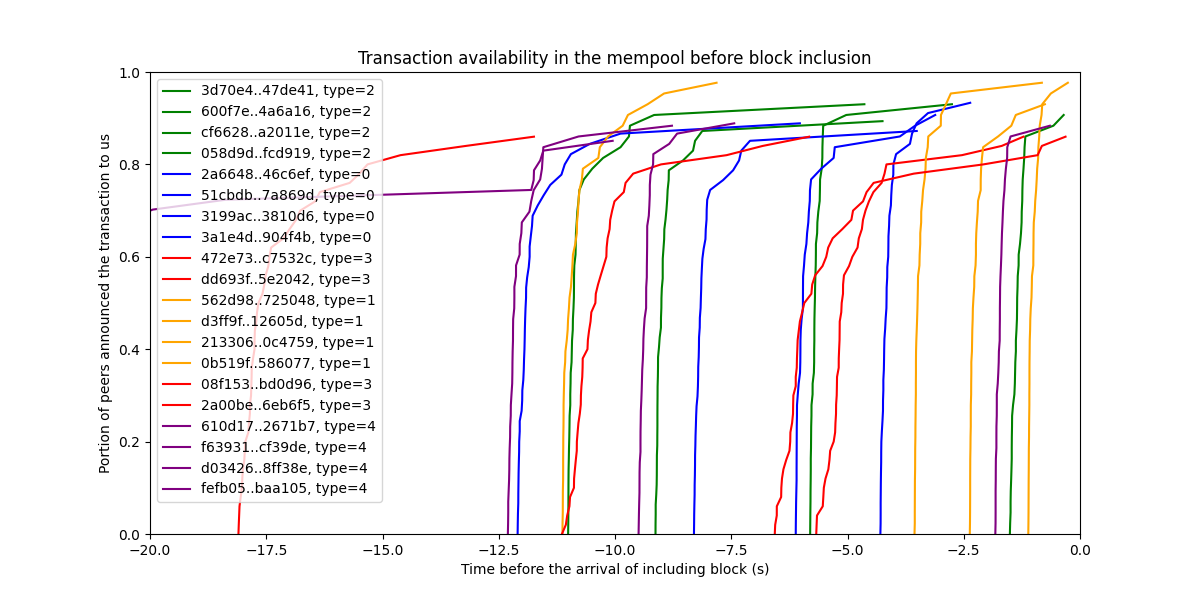
The X axis shows the time before the arrival of the respective block, the one in which the given tx was included. Each line shows information we have about a single tx. Lines do not arrive to 100% because not all of our peers report reception. This can either be because they did not get the transaction, or because they did not report it. We don’t know. What we know (although without the cryptographic guarantees of a real DAS sampling based on erasure coding and KZG commitments) is that who reported has also received the transaction before reporting it to us. From the curves, we see that every one of these transactions were propagating very fast in the mempool, even type 3 transactions (the red lines).
Note: *Note that the plot shows when the announcements arrive to us. The announcement was obviously sent earlier. We could estimate the network latency to compensate for this, and our lines would probably be even more vertical, but we haven't done this correction here.*
We can also look at this data differently, focusing on how fast transactions spread in the system, by setting the startline to the first time we heard about a transaction.
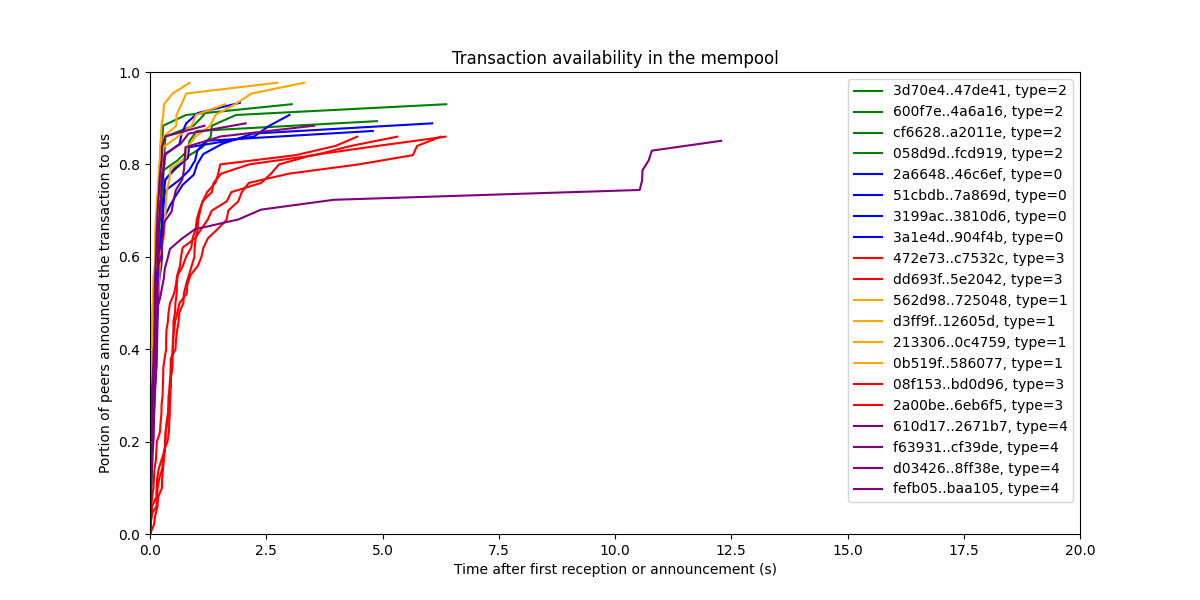
Transactions spread really fast in the network.
Obviously, we can’t plot this for all transactions, there are millions of them. We can however try to extract some meaningful statistics. One such statistics is the “average time to reach X% diffusion in the mempool”. We can extract this data, per transaction type, and plot the mean and it’s confidence interval.
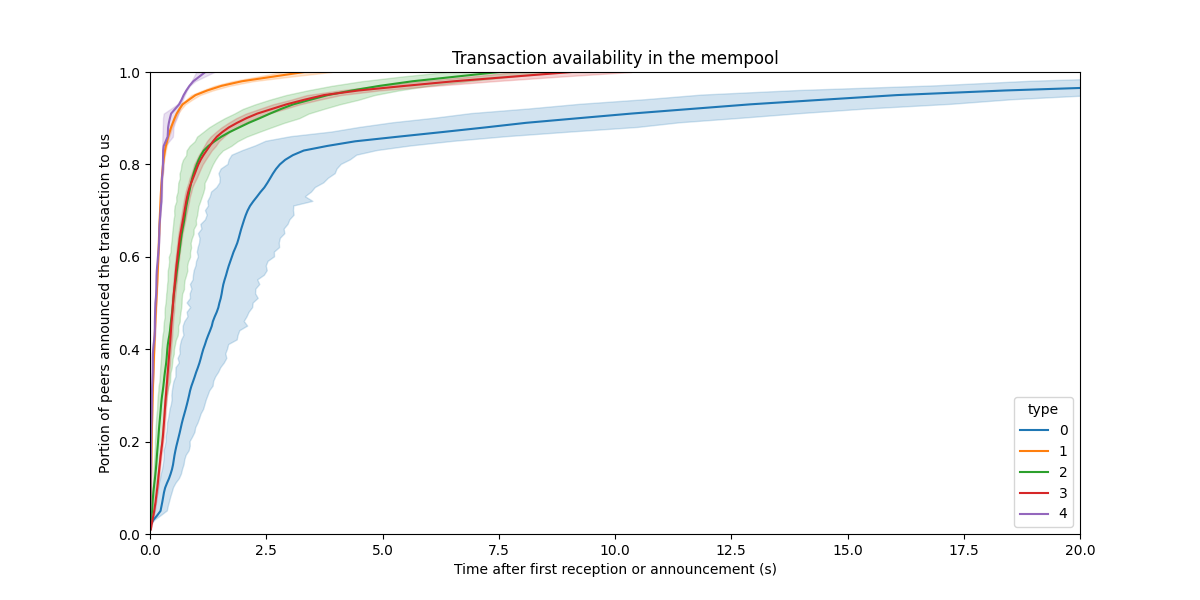
Interestingly, type 0 transactions seem to spread relatively slow. Still, everything is diffused in a few seconds, which is more than enough for the mempool.
Blob transactions spreading in the Mempool
Let’s focus on type 3 transactions only, carrying blobs. A type 3 transaction “bundles” several blobs, which will then be included in a block together. Clearly, having more blobs than what a block can contain does not make sense. But now that we have started increased the maximum blob count (to 9 in Pectra), another limit becomes relevant: maximum message size at the EL, which is currently set to 1MB in Geth.
One might argue that we should increase this EL message size limit, but there are several reasons not to do so:
- Larger messages would mean that a single type 3 transaction can occupy a whole block. Blocks would then multiplex blobs from different sources with lower efficiency, and larger delay. As a consequence, the inclusion delay of other type 3 transactions could increase.
- Larger messages spread slower in the network. And now we can also show how much.

With 6 blobs, our messages are still spreading fine in the mempool. However the trend is clear as the number of blobs in type 3 transactions increase: spreading is slower, while more and more nodes would start missing these transactions.
Note that the message size limit does not influence the overall blob throughput of the network. The advantages of larger type 3 transactions are:
- amortized fixed cost, but that has a diminishing return,
- the atomicity of block inclusion, but that doesn’t seems to be used at the moment.
Thus, keeping the message maximum message size relatively low makes sense.
Block transaction age
It is also interesting to observe how much time block transactions spend in the mempool. More specifically, we look at how much time they have spent in the mempool (as seen by our EL node) before being included in a block.
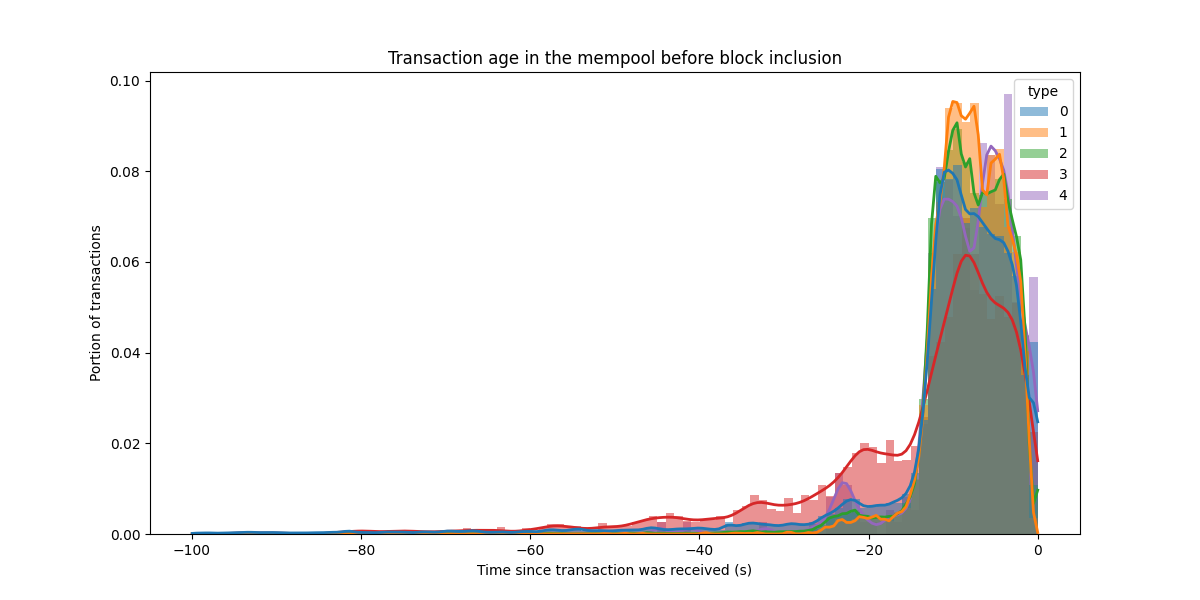
While there are old transaction included as well, the majority is from the last 20 seconds. For type 3 transactions, inclusion time is slightly higher. Since diffusion is really fast in the mempool, this short inclusion delay is not a problem.
Could we do “real DAS” directly in the mempool?
As highlighted multiple times, the sampling done here is without guarantees. DAS in the CL is instead based on erasure codes and KZG commitments. Could we do something similar in the mempool?
Now that we start moving erasure coding to the mempool by making it mandatory to encode blob transactions at the point of submission, we could. We are not yet there, but we could add a new message type at the network layer which sends blob cells directly between EL nodes. This is something to investigate, together with the use of coding techniques as part of mempool diffusion. In fact, we can use erasure coding to speed up diffusion similar to how we use erasure coding as part of the network stack in our work of FullDAS.
But even without such changes to the protocol and the guarantees provided by KZG commitments, a block producer knows quite a lot about the diffusion state of transactions, and we think this could be used already by low-resource builders to make block and blob diffusion more robust.