Theoretical Blob hit rate based on the EL mempool
This work was done in collaboration with my colleagues at ProbeLab and with the support of the Ethereum Foundation. The presented report aims to analyze the theoretical blob hit rate that a Consensus Client can expect when querying its Execution Layer Clients about the blob transactions included in a proposed beacon block.
Big thanks to the Ethereum Foundation networking team and the EthPandaOps team for their valuable feedback.
Motivation
Ethereum is looking to scale up its blob throughput through PeerDAS, a promising step that could enable significantly higher blob counts without requiring every node to download and process all data themselves. While this is great for scalability, it introduces new challenges for validators who build blocks locally. These local builders would still need to broadcast all the blobs they reference within the 4-second block propagation window, which isn’t always feasible under bandwidth constraints.
To ease that burden, the concept of distributed block-building has been proposed. This approach allows local validators to include any blob transactions they’re already aware of, under the assumption that others in the network might have seen those blobs too. Instead of rebroadcasting the entire blob set through GossipSub, the idea is to rely on the network to help fill in the gaps. When a node spots a blob-transaction included in a block that it also holds locally (verified via the engine_getBlobs RPC call to the EL), it can take on the responsibility of initiating its GossipSub broadcast, effectively lightening the load on the original block proposer.
To assess whether this kind of collaborative blob distribution could work in practice, we aim to quantify the theoretical availability of blob transactions at the moment of block proposal. This study will look into mempool trends and blob-transaction visibility to understand whether distributed block-building can realistically support higher blob counts without overwhelming local validators.
Summary
- Assuming that US and AU represent some of the best and worst connected regions in the network (in terms of network latency), we identified that
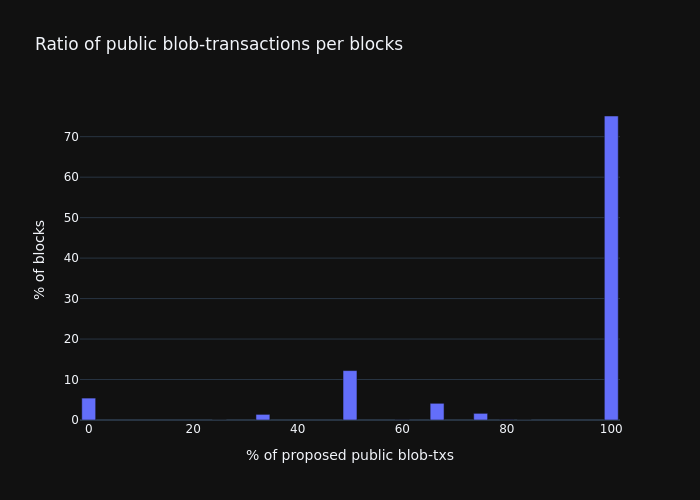
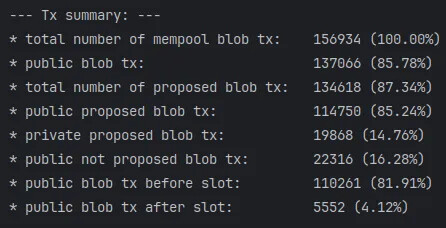
99%of blob transactions in the public mempool are seen in mempools of both locations within 1s of delay between when a blob-tx was seen for the first and the last time, respectively. - As a summary, our results show that out of the proposed blob transactions:
14.5%where not seen at the public mempool before the block-arrival,81.91%of the blob-transactions weren’t only public but also arrived before the start of the slot,- only
4,12%of the blob-transactions were seen in the public mempool, after the start of the slot.
- These numbers show that, at least on paper, distributed block-building should work fine as long as public blob transactions remain at the current rates.
- Potential optimisation for distributed block-building: local-builders could start broadcasting blob-sidecars over GossipSub in the reverse order of arrival to the mempool. This would ensure that the blobs that people are likely to not be aware of are shared with the block that needs them.
Study
Methodology
The following study relies on the data provided by the EthPandaOps team through their public Xatu Database. We’ve used the following Xatu schemas or tables to compute the analysis:
- Xatu - Beacon API events | ethPandaOps
- Xatu - Mempool events | ethPandaOps
- Xatu - Canonical Beacon chain events | ethPandaOps
The results of the study correspond to the following dates:
- dates: from
2025-03-01to2025-03-15 - slots: from
11163298to11264098
*NOTEs: *
- All the transactions from the mempools were filtered to track only blob-txs, therefore, the study only contains txs whose type was type == 3 .
- To keep the distributions as clean as possible (my attempt to clean outliers from them), the code includes a filter that removes arrival events that happened after 12s from the first arrival (1 slot).
Propagation delay for blob-tx over the public mempool
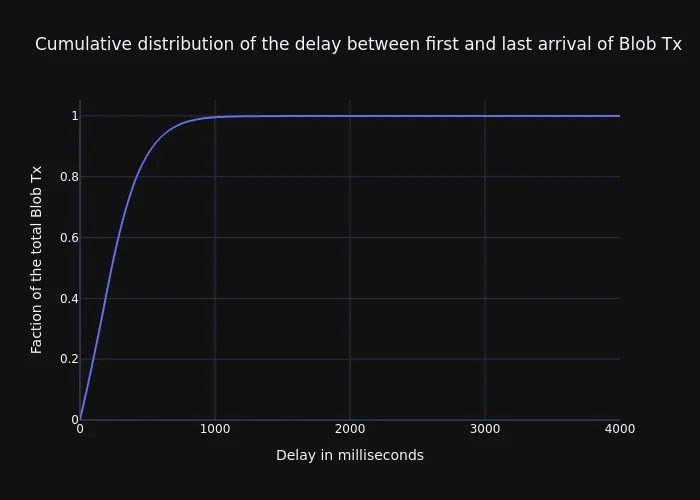
In a similar way as beacon blocks or other messages that get distributed over a p2p network, there is always a time difference between the first arrival and the last arrival of a message for different peers in the network. In the following graph, we display the CDF of the measured delay that Xatu gathered for each of the public blob-tx.
To be more specific, the graph shows the elapsed time between the first time the tx was seen by a peer and the last arrival tracked in the dataset (i.e., last time the tx was seen by a peer). The graph shows that over 99% of the transactions are seen within one second of delay. If we get to the mean of the distribution, or the percentile 50, this value gets reduced to 235ms or less.
Blob Tx arrival delays based on the node’s country
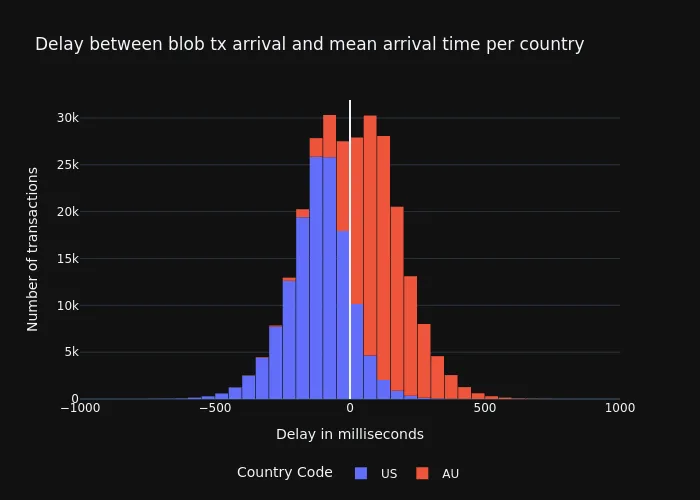
Despite Ethereum being a distributed and decentralized network, there are still prominent network clusters that can affect the arrival time of messages to nodes running within those clusters and locations (current distribution from probelab.io). The following graph shows the arrival time of the blob-tx using the mean between the first and last arrival as reference. What we see is that nodes in the US tend to be within the early nodes receiving those messages, giving them higher chances of success if the CL asks for blobs through the engine_getBlobs RPC call for those blobs that were shared closer to the beacon block proposal.
Arrival time difference between the Tx being public in the mempool and the start of the slot
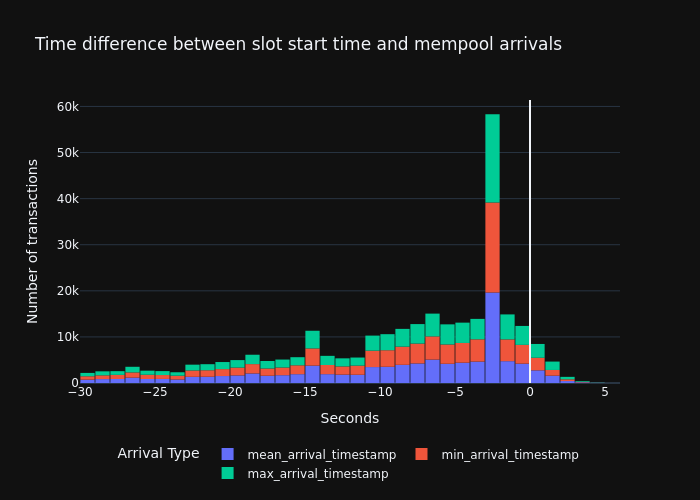
Once we know the arrival time of blob transactions and the slot at which they got included, we can visualize when did those transactions arrive in the first place (best case), the network’s mean (average case), and the last place (worst case) in comparison to the slot starting time.
In the resulting chart, we can see that the biggest chunk of public-blob-txs arrive within the 12 seconds before the slot, with the biggest peak happening at the 3 secs mark prior to the slot start time. Interestingly, there are blob-txs that arrived even a few slots before.
Observations:
- Due to the low delay in the tx propagation, there isn’t much difference between the best and the worst case, or between different countries.
- Perhaps even more importantly, the percentage of public blob-txs that fall beyond the
slot-start-timeis only4.12%(more numbers in the next section), while still most of these tx arrive within the first 2 seconds of slot.
Flow of blob txs
We’ve seen how the public blob-tx are “available” at the local EL mempool before the start of the slot where they are published. However, it isn’t still enough evidence to give us the big picture of whether “distributed-block-building” could work. In other words, if the public transactions are indeed available before the proposal, but they only represent, say, 10% of the total included blob-txs, this would mean that 90% of the total blob-txs are coming from private mempools. If that were the case, peers wouldn’t be able to publish the blob-sidecars without receiving them through GossipSub channels first.
We might still argue that this doesn’t affect local-builders in any case, as they could only propose public blob-tx, and we could expect similar numbers as the presented ones. Still, the following graph shows the Sankey diagram of the total number of blob transactions seen over those dates.
The highlights that we can extract from it are:
14.76%of the proposed blob-txs are coming from a “private source” (*), and the other85.78%come from the public mempool16.28%of the public blob-tx are never included in a subsequent beacon block payload81.91%of the proposed blob-tx were seen at the public mempool before the start of the slot where they included and only4.12%came afterwards (the rest are private)
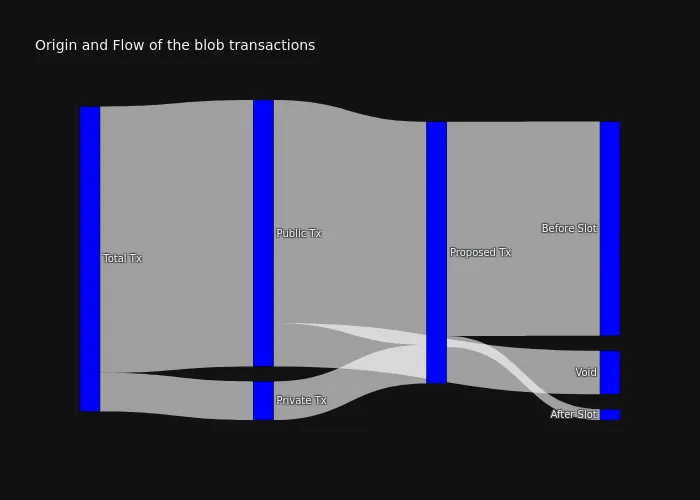
NOTE: (*) because we need to define the dates of the data that we are requesting, some of the transactions that we consider “private” could have been seen previously by the mempool but we couldn’t fetch them because they fall before the requested time (this is the best we could get based on the query parameters of Xatu). This could ultimately produce false positives when identifying “private txs”.
NOTE: The percentage of the transactions shown in the figure reference the total representation to their “parent” set.
Common questions
What happens with those “Void” transactions?
Transactions in Ethereum can be reverted or replaced as long as they’re still in the mempool and not yet included on-chain. A transaction can be overridden by submitting a new one with the same nonce and a higher fee. This applies to blob transactions as well — they can be updated as long as the nonce remains the same.
We believe that the transactions marked as “void” in the graph fall into this category, rather than being the result of any kind of censorship.
What happens with those “Private Tx”?
(Big thanks to @pop for his input on this matter.) The use of private mempools is common in Ethereum — as a countermeasure against third-party MEV extraction, to achieve faster inclusion, or simply to keep a transaction private until it’s included. (For more on this, see @nero_eth’s post).
However, the nature of blob transactions is quite different from general-purpose transactions. They are primarily used by L2s to submit proofs or data blobs for their operations — which, for most of the network, are just arbitrary bytes. This reduces the incentive to keep them private or shield them from MEV.
Our study shows that, in general, the network relies on the public mempool to broadcast these transactions, at least in the vast majority of cases. That said, around 15% of blob transactions appear to originate from private mempools, with Taiko (ZK-rollup) being the main contributor (reference graph).
Conclusions
- The study shows that the network, at the moment, handles generally public blob transactions, which nodes are aware of before the arrival of the block at which they end up included.
- At the current public blob tx rate and their arrival time into the mempool, solutions like Distributed Block Building can ease a faster processing and propagation of higher blob counts.
- This also means that the network is allocating resources propagating redundant information, as the majority of proposed blob txs are propagated over the EL mempool first and then rebroadcasted over the CL’s gossipsub topics.
- Inevitably, this can lead to large blob tx consumers to have some resource cuts, as they can just submit their blobs once into a private mempool or builder, delegating into them the propagation of those blobs that happen only at the moment of publishing the block.
- Despite this being beneficial for the network, as it means that there is more bandwidth available (nodes don’t have to download and propagate the same information twice), this can create some centralization risks for the MEV builders.