During the 1.x workshop in Paris last weekend, a couple ideas have been discussed for the transition from hexary tries to binary tries. It has been agreed that each proposal should be published on ethresearch for comparison and further discussion.
TL;DR
A hexary to binary conversion method in which new values are stored directly in a binary tree sitting “on top” of the hexary, while the “historical” hexary tree is converted in the background. When the process is finished, both layers are merged.
Snapshotter
In the present proposal, I am relying on an up-and-coming feature of geth, the snapshotter. I won’t go too much in the details of the snapshotter here, just the general principle:
- it uses series of diff layers to store recent modification,
- an on-disk, storage layer contains a more ancient, stable version of the tree and is used as the base of the diff
This method promises a lot of improvements for speed and sync, including the method proposed here to switch between hexary and binary trees.
The binary tree overlay
The base idea consists in laying a binary tree “over” the hexary tree. The hexary tree is then declared read-only:
- all new values are therefore inserted into the binary tree,
- when reading a value, both trees are being searched in parallel:
- If a value is found in the binary tree, it is returned,
- If a value is found in the hexary tree and not in the binary tree, it is returned,
- a background process converts the base layer from hexary to binary
- when the base layer conversion has been achieved, the miner signals that they are ready for the switch by publishing the new root in the block header. When enough (N) miners have reported the same conversion, that trie is considered the new base layer and the top layer can then be merged.
Transition process
In the subsequent paragraph, root^{2} represents the root of a binary tree, and root^{16} that of a hexary tree.
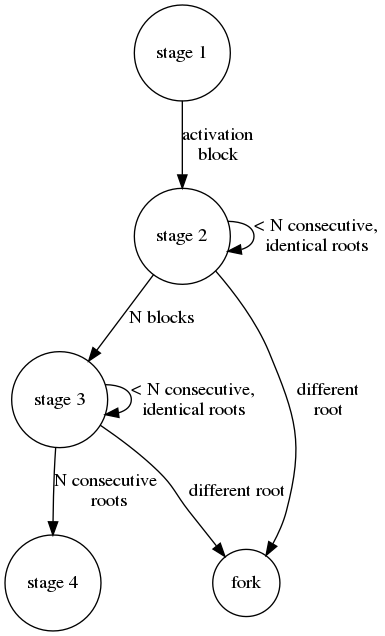
The transition goes through 4 phases:
- The block format is unchanged until block number n_{activation}
- At block number n_{activation}, blocks contain two state roots: the root root_{base}^{16} of the hexary base layer and the root root_{overlay}^{2} of the overlay binary tree. Participants have N blocks to convert the base layer from hexary to binary in a background process. During those N blocks, the value of root_{base} remains the value of the hexary state root at block number n_{activation}-1 (that is, root_{base}^{16}), and any other value will be refused by honest nodes.
- At block number n_{activation}+N, the value of root_{base} becomes that of the translated base tree to binary, i.e. root_{base}^{2}. This block format is used until N consecutive blocks have provided the same value for root_{base}^{2}. A background process starts to insert elements represented by root_{overlay}^{2} into the tree with root root_{base}^{2}. This is done in the background and the block should keep reporting an identical value for root_{base}. At this stage, a block can only be considered valid if they provide either the hexary value or the binary value previously seen. Any other value has to cause a fork at block number n_{activation}+N.
- Once N consecutive blocks have occured, the two layers are merged and only root_{base}^{2} is present in subsequent blocks. From this point on, the consensus rules are the same as during stage 1, except that the state tree is now binary.
Required changes
- state roots: during the transition period, blocks should have two state roots: that of the hexary tree (which should not change over time) and that of the binary tree. When the conversion of the base layer has happened, the hexary root is replaced with the result of the binary conversion. After N blocks have had the same root, the hexary root is deprecated in favor of the binary root. After another N blocks, the two binary layers are merged and the top state root is discarded.
- consensus: both state roots have to be considered by the consensus algorithm
I believe that this can be done in one hard fork, and some people have expressed reservations about this. I’m looking forward to discussing this point.
Key metrics
Here are key metrics that a prototype should be able to measure in order to demonstrate the feasibility of this concept
- Memory usage: it depends on the conversion process
- Disk space: it is estimated to require around 30 extra GB during the transition
- CPU usage: this model proposes a conversion that is done by miners and full node to the benefit of the entire ecosystem, and is very costly to these actors. Computation costs could be shared with the community by a gas price increase during the process.
Open questions
- Should we delete values present in both trees? This could reset the calculation of the hash, and therefore create an attack vector that would forever stall the conversion. It would also simplify the final hash calculation.
- Symmetrically, should reads returning values from the hexary tree that are not present in the binary tree be inserted there? This adds extra calculations which should cause a gas price increase. This would make the final merge easier, though.
- How long will this realistically last? Current estimates range from between two weeks to a month, testing will answer this question more precisely.
- Who is going to pay for it? Presumably the miners, if an increase in gas price can offset the extra costs. This has the advantage that, for a couple weeks, the price of gas will be more expensive and therefore the amount of transactions lower, which will in return help reduce the increase in required resources.
Thanks
This has benefited from the valuable feeback from Sina Mahmoodi and Tomasz Stanczak.
9 Likes
I like the simplicity of this compared to other “gradual merge” proposals!
Doesn’t step 3 have the issue that the new value for root^2_{base} is a moving target, because the overlay is a moving target? Why not instead this slightly modified approach?
- Let R_{base} base the current hexary root. At block height H_1, the hex tree becomes read-only, and any writes after that point instead go to a new overlay tree with root R_{overlay}. The overlay tree starts out empty. Reads check the overlay tree first, then check the base tree if something is not found in the overlay tree.
- Full nodes compute R^2_{base}, a translation of R_{base}, to binary. At block height H_2, it is assumed that all full nodes have R^2_{base}, and blocks after this point must contain R^2_{base} instead of R_{base} as their primary state root. Writes now go into the main tree, and the overlay becomes read-only.
- A background process slowly walks through the overlay tree left to right, deleting the overlay nodes and adding them to the main tree (ie. this is part of the per-block state transition). Eventually the overlay tree becomes empty again, at which point it gets forgotten.
- state roots : during the transition period, blocks should have two state roots
Could just temporarily abuse extradata for this.
2 Likes
That’s a nice simplification! Moving (key, values) from the overlay back to the main tree in such a predictable fashion is very practical.
The implementation detail to watch out for, is a potential race condition that occurs when a (key, value) move is preempted by a tx from the same block that accesses/writes the same location. Apart from that, it seems pretty straightforward.
1 Like
Thank you for writing this down! If the migration is expected to take from 2 weeks to a month, does not this mean that any node joining during the migration will no be able to verify the state root of the binary overlay? And no new miners can easily join in?
Or is the two weeks to a month not a requirement? If the snapshotter is used, then perhaps the conversion can be done much faster?
One approach is to just be lazy and say that new miners cannot join during the transition until they compute the entire tree. IMO we should not discount the “quick and lazy” answer, especially if it has fewer corner cases.
Another approach would be to stagger it, eg. require blocks to commit to a binary tree representing just accounts starting with 0x00 after 1 hour, then a binary tree representing accounts starting with 0x00 or 0x01 after 2 hours, etc etc. Then a newly joining client would only have to compute at most a small subtree.
1 Like
I wrote a quick and dirty, unoptimized PR to have a worst-case estimate of how long it would take for geth to convert the hexary trie to a binary trie.
- Running the snapshotter on the account trie currently takes around 9 hours. The way it is implemented in geth, this can be done before H_1
- I estimate the hex -> bin conversion time of the base to around 1.5 days, and is mostly IO-bound. This has been estimated with Goerli, I’ll do a mainnet test as soon as I have a machine available.
With these preliminary numbers, and adopting Vitalik’s 3rd point method, there should be around two days between H_2 and H_1.
It is indeed a steeper curve for miners to join at this time. Big miners won’t have that much trouble, as the conversion is highly parallelizeable. To smaller miners, though, joining during the transition period will feel like doing another full sync (which it is, in a way).
If these numbers hold for mainnet, small miners would be better off holding for two more days, before fast-syncing.
I just want to add a little clarification.
- Converting a hexary account-trie to snapshot-format takes around 9 hours. This is IO bound, since we need to iterate the entire trie, including all intermeidate nodes.
- Converting a snapshot into a hexary trie hash : takes on the order or 10 minutes (estimate). I would assume a binary trie hash takes roughly the same time. This is so much faster since we really only need to iterate data according to the ‘native’ key ordering on the flat db. It’s also read-only, and since the hasher receives keys in order, we can always collapse “behind us” and not have to build large memory structures.
- Converting a snapshot into a hexary/binary trie (whole tree). This has not yet been tested. I would assume it’s on the order of ~10h, mainly output-bound, since we’re writing huge amounts of data to a new database. However, we know in advance roughly how much data we’re about to write, and could thus probably optimize this step quite a lot (so the difference between a first naive implementation and an optimized one could be significant).
At the time when we want to switch over, we should assume that geth-clients already have a snapshot database.
Update – generating the trie hash from main account trie (no storage) took below 10 minutes (hat-tip to @gballet) :
Generated trie hash from snapshot accounts=80438713 elapsed=9m14.613433638s
Regarding the EIP, my initial thought (I may not have read it thoroughly enough, apologies if so):
- I’m the first miner to complete the conversion, and want to signal readiness. If I do so, the risk of my block being orphaned (not uncled, but totally abandoned) increases dramatically. So it would be in my best interest to not do so.
So I’m thinking there may be built-in disincentives from actually going through with the conversion?
From the EIP:
Phase 2 ends when a sufficient number of subsequent blocks have reported the same value for Hᵣ².
This sounds ‘odd’ to me. If I am a miner, who has not yet calculated the binary trie root, I have no way to actually validate one of those blocks. So as soon as I see one such block at height N, then
- I can choose to ‘trust’ that it’s correct, and hope that my binary stateroot actually becomes equal, at some point. If I do that, I can mine on top of this block.
- I can choose to ignore that block, and keep mining on
N (until a binary-root-free N is propagated).
It’s a quirky situation, imo, where there’s some game at play, but I’m not sure about the game mechanics here.
- I’m the first miner to complete the conversion, and want to signal readiness. If I do so, the risk of my block being orphaned (not uncled, but totally abandoned) increases dramatically. So it would be in my best interest to not do so.
The idea here is that you “vote” for a root, to figure out if your conversion was correct (if “correct” means “the same as the majority”). If you get a different number than that of the majority, it means that your conversion is corrupt (or that you are the honest minority).
But the fact that your value is different from that of the majority isn’t going to make your block invalid during phase 1, it’s just advisory.
This sounds ‘odd’ to me. If I am a miner, who has not yet calculated the binary trie root, I have no way to actually validate one of those blocks.
Rephrasing for the sake of clarity: in this phase, you need not validate the new root, it’s just a vote by some other miner.
I can choose to ignore that block, and keep mining on N (until a binary-root-free N is propagated).
You could do that, especially if you see that your converted value is different from what is being advertised. If a majority of honest nodes behave correctly, they have no reason to follow your new block and you find yourself having to catch up with the longest chain.
I can choose to ignore that block, and keep mining on N (until a binary-root-free N is propagated).
A simpler version, which I believe Vitalik described in his response, is to simplify the process by removing the vote and fixing a block height h_2 “far enough in the future” at which R^{16}_{base} is replaced with R^2_{base}.
h_2 is chosen to leave clients enough time to perform the conversion. With current algorithms, it looks like 2~3 days max.
It has the advantage that removing the vote is a good way to make sure that the vote won’t be gamed.
Some suggestions about simplifying the process (quite a lot, I would think): https://github.com/ethereum/EIPs/pull/2584#issuecomment-621080575
As a summary of the discussion in that PR: @holiman suggests to disable tx writes to the trie for the ~ 45 minutes that the (account) conversion takes. Only coinbase updates would end up in the overlay. The result is that phase 2 could be achieved in a couple blocks.
In practice: blocks in the conversion phase would be all empty, so the ‘disable tx writes’ is a side-effect, with the consequence that only miners (canon and ommer-miners) are modified in each block.